

쌩로그
자바 ORM 표준 JPA 프로그래밍 Ch.14. 컬렉션과 부가 기능 (1) 본문
목록
- 포스팅 개요
- 본론
2-1. 컬렉션
2-2. @Converter - 요약
1. 포스팅 개요
자바 ORM 표준 JPA 프로그래밍의 14. 컬렉션과 부가 기능를 학습하며 정리한 포스팅이다.
이번 포스팅에 4개의 주제가 있는데, 리스너와 엔티티 그래프에 대해서는 인프런에서 스프링 데이터 JPA 강의에 대해 정리 & 포스팅 한 이후 포스팅할 예정이다.
2. 본론
다룰 내용은 목차에서 보았듯이 다음과 같다.
- 컬렉션 : 다양한 컬렉션과 특징을 설명한다.
- 컨버터 : 엔티티의 데이터를 변환해서 데이터베이스에 저장한다.
2-1. 컬렉션
JPA는 자바에서 기본으로 제공하는 Collection, List, Set, Map 컬렉션은 지원하고 다음 경우에 이 컬렉션을 사용할 수 있다.
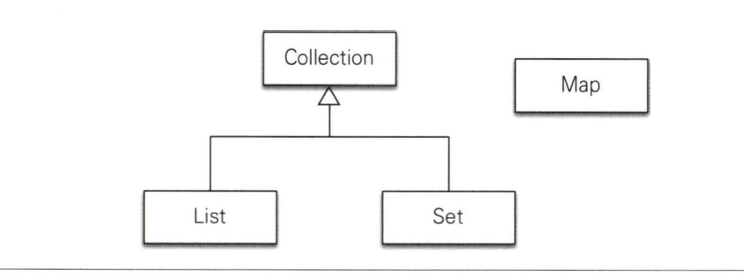
@OneToMany,@ManyToMany를 사용해서 일대다나 다대다 엔티티 관계를 매핑할 때@ElementCollection을 사용해서 값 타입을 하나 이상 보관할 때
JPA 명세에는 자바 컬렉션 인터페이스에 대한 특별한 언급이 없다.
따라서 JPA 구현체에 따라서 제공하는 기능이 조금씩 다를 수 있다.
(지금은 하이버네이터 구현테을 기준으로 한다.)
참고
- Map은 복잡한 매핑에 비해 활용도가 떨어지고 다른 컬렉션을 사용해도 충분하므로 생략한다.
- 참고로 Map은
@MapKey*어노테이션으로 매핑할 수 있다.
JPA와 컬렉션
하이버네이트는 엔티티를 영속 상태로 만들 때 컬렉션 필드를 하이버네이트에서 준비한 컬렉션으로 감싸서 사용한다.
@Entity
public class Member {
...
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
...
}
@Entity
public class Team {
@Id @GeneratedValue
@Column(name = "team_id")
private Long id;
@OneToMany(mappedBy = "team")
private Collection<Member> members = new ArrayList<>();
...
}위 예제의 Team은 members 컬렉션을 필드로 가지고 있다.
다음 코드로 Team을 영속 상태로 만들어보고 출력결과를 보면 다음과 같다.
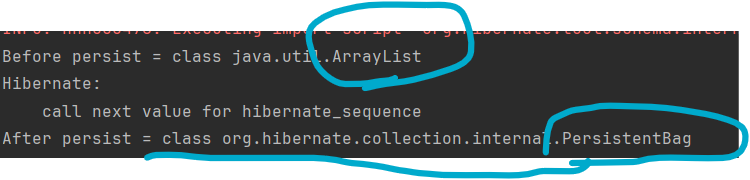
출력 결과를 보면 원래 ArrayList 타입이었던 컬렉션이 엔티티를 영속 상태로 만든 직후에 하이버네이트가 제공하는 PersistentBag타입으로 변경되었다.
하이버네이트는 컬렉션을 효율적으로 관리하기 위해 엔티티를 영속 상태로 만들 때 원본 컬렉션을 감싸고 있는 내장 컬렉션을 생성해서 이 내장 컬렉션을 사용하도록 참조를 변경한다.
하이버테이트가 제공하는 내장 컬렉션은 원본 컬렉션을 감싸고 있어서 래퍼 컬렉션으로도 부른다.
하이버네이트는 이런 특징 때문에 컬렉션을 사용할 때 다음처럼 즉시 초기화해서 사용하는 것을 권장한다.
Collection<Member> members = new ArrayList<>();다음 인터페이스에 따라 어떤 래퍼 컬렉션이 사용되는지 확인해보자.
Collection일 때 : class org.hibernate.collection.internal.PersistentBag
List 일 때 : class org.hibernate.collection.internal.PersistentBag
Set 일 때 : class org.hibernate.collection.internal.PersistentSet
//
@OneToMany(mappedBy = "team") @OrderColumn
private List<Member> members = new ArrayList<>();
//
위처럼 List + @OrderColumn 일 때 : class org.hibernate.collection.internal.PersistentList인터페이스에 따른 하이버네이트 내장 컬렉션과 특징을 정리하면 다음과 같다.
| 컬렉션 인터페이스 | 내장 컬렉션 | 중복 허용 | 순서 보관 |
|---|---|---|---|
| Collection, List | PersistentBag | O | X |
| Set | PersistentSet | X | X |
| List + @OrderColumn | PersistentList | O | O |
Collection, List
Collection, List 인터페이스는 중복을 허용하는 컬렉션이고, PersistentBag을 래퍼 컬렉션으로 사용한다.
이 인터페이스는 ArrayList타입으로 초기화하면 된다.
Collection, List는 엔티티를 추가할 때 중복된 엔티티가 있는지 비교하지 않고 단순히 저장만 하면 된다.
따라서 엔티티를 추가해도 지연 로딩된 컬렉션을 초기화하지 않는다.
Set
Set은 중복을 허용하지 않는 컬렉션이다.
하이버네이트는 PersistentSet을 컬렉션 래퍼로 사용한다.
이 인터페이스는 HashSet으로 초기화하면 된다.
Set은 엔티티를 추가할 때 중복된 엔티티가 있는지 비교해야 한다.
따라서 엔티티를 추가할 때 지연 로딩된 컬렉션을 초기화한다.
List + @OrderColumn
List 인터페이스에 @OrderColumn을 추가하면 순서가 있는 특수한 컬렉션으로 인식한다.
순서가 있다는 의미는 데이터베이스에 순서 값을 저장해서 조회할 때 사용한다는 의미다.
하이버네이트는 내부 컬렉션인 PersistentList를 사용한다.
다음은 List + @OrderColumn를 사용한 예시 코드다.
@Getter
@Entity
public class Board {
@Id
@GeneratedValue
@Column(name = "board_id")
private Long id;
private String title;
private String content;
@OneToMany(mappedBy = "board")
@OrderColumn(name = "POSITION")
private List<BoComment> comments = new ArrayList<>();
}
@Entity
@Getter
public class BoComment {
@Id
@GeneratedValue
private Long id;
private String comment;
@Setter // 학습상
@ManyToOne
@JoinColumn(name = "board_id")
private Board board;
}Board.comments에 List인터페이스를 사용하고 @OrderColumn을 추가했다.
따라서 Board.comments는 순서가 있는 컬렉션으로 인식된다.
자바가 제공하는 List 컬렉션은 내부에 위치 값을 가지고 있다.
따라서 다음 코드처럼 List의 위치 값을 활용할 수 있다.
list.add(1, data1); // 1번 위치에 data1을 저장하라.
list.get(10); // 10번 위치에 있는 값을 조회하라.순서가 있는 컬렉션은 데이터베이스에 순서 값도 함께 관리한다.@OrderColumn의 name 속성에 POSITION이라는 값을 주었다.
JPA는 List의 위치 값을 테이블의 POSITION 컬럼에 보관한다.
Board board = new Board("제목1", "내용1");
em.persist(board);
BoComment boComment1 = new BoComment("댓글1");
boComment1.setBoard(board);
board.getComments().add(boComment1); // POSITION 0
em.persist(boComment1);
BoComment boComment2 = new BoComment("댓글2");
boComment2.setBoard(board);
board.getComments().add(boComment2); // POSITION 1
em.persist(boComment2);
BoComment boComment3 = new BoComment("댓글3");
boComment3.setBoard(board);
board.getComments().add(boComment3); // POSITION 2
em.persist(boComment3);
BoComment boComment4 = new BoComment("댓글4");
boComment4.setBoard(board);
board.getComments().add(boComment4); // POSITION 3
em.persist(boComment4);@OrderColumn을 사용해서 List의 위치 값을 보관하면 편리할 것 같지만 다음에서 설명하는 것처럼 실무에서 사용하기에는 단점이 많다. 따라 @OrderColumn을 매핑하지 말고 개발자가 직접 POSITION 값을 관리하거나 다음에 설명하는 @OrderBy를 사용하길 권장한다.
@OrderColumn의 단점
@OrderColumn은 다음과 같은 단점들 때문에 실무에서 잘 사용하지 않는다.
@OrderColumn을 Board 엔티티에서 일대다로 매핑하므로Comment는POSITION의 값을 알 수 없다. 그래서Comment를INSERT할 때는POSITION값이 저장되지 않는다.POSITION은Board.comments의 위치 값이므로, 이 값을 사용해서POSITION의 값을 UPDATE하는 SQL이 추가로 발생한다.
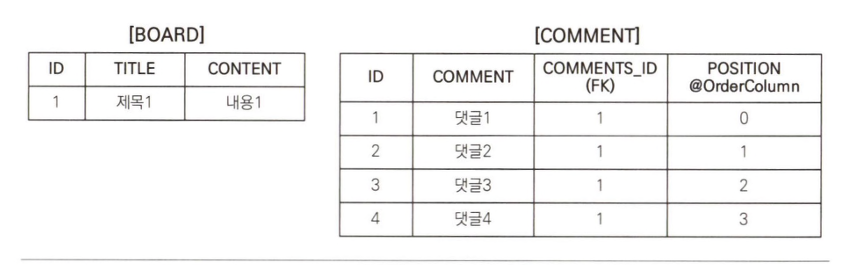
List를 변경하면 연관된 많은 위치 값을 변경해야 한다. 예를 들어 위의 그림에서 댓글2를 삭제하면 댓글3, 댓글4의POSITION값을 각각 하나씩 줄이는 UPDATE SQL이 2번 추가로 실행된다.- 중간에
POSTIION값이 없으면 조회한List에는null이 보관된다. 예를 들어 댓글2를 데이터베이스에서 강제로 삭제하고 다른 댓글들의POSITION값을 수정하지 않으면 데이터베이스의POSITION값은[0,2,3]이 되어서 중간에 1 값이 없다. 이 경우List를 조회하면 1번 위치에null값이 보관된다. 따라서 컬렉션을 순회할 때NullPointerException이 발생한다.
@OrderBy
@OrderColumn이 데이터베이스에 순서용 컬럼을 매핗애서 관리했다면 @OrderBy는 데이터베이스의 ORDER BY 절을 사용해서 컬렉션을 정렬한다. 따라서 순서용 컬럼을 매핑하지 않아도 된다.
그리고 @OrderBy는 모든 컬렉션에 사용할 수 있다.
다음 예제를 통해 알아보자.
@Entity
public class Team {
@Id @GeneratedValue
@Column(name = "team_id")
private Long id;
private String name;
@OneToMany(mappedBy = "team") @OrderColumn
@OrderBy("username desc, id asc")
private Set<Member> members = new HashSet<>();
public Set<Member> getMembers() {
return members;
}
public Long getId() {
return id;
}
}
@Entity
public class Member extends BaseEntity {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "MEMBER_NAME")
private String username;
@Embedded
private Address address;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
@OneToMany(mappedBy = "member")
private List<Order> orders = new ArrayList<>();
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return username;
}
public void setName(String username) {
this.username = username;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
}
위 코드의 Team.member를 보면 @OrderBy를 적용했다.
그리고 @OrderBy의 값으로 username desc, id asc를 사용해서 Member의 username 필드로 내림차순 정렬하고 id로 오름차순 정렬했다. @OrderBy의 값은 JPQL의 order by절처럼 엔티티의 필드르 대상으로 한다.
순수 JPA를 사용해서 다음과 같이 코드를 작성해보면 된다.
Team team = new Team();
em.persist(team);
em.flush();
em.clear();
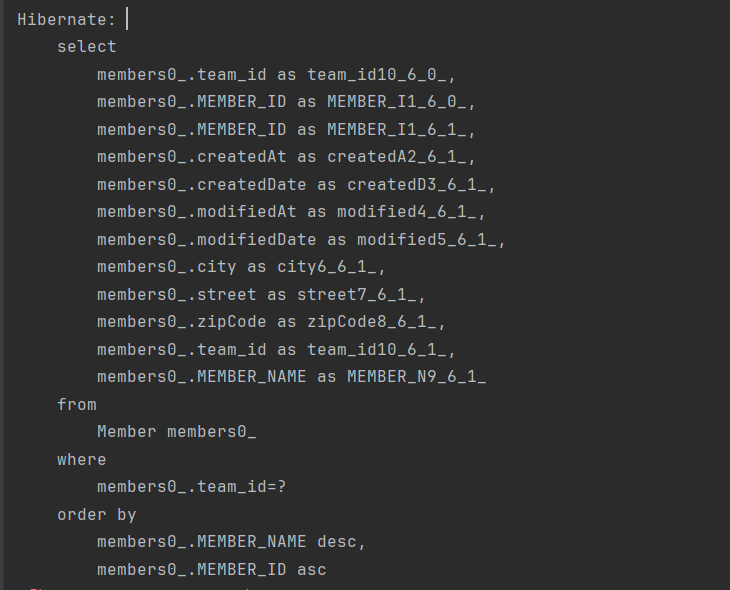
Team findTeam = em.find(Team.class, team.getId());
findTeam.getMembers().size();Team.members를 초기화할 때 실행된 다음 SQL을 보면 ORDER BY가 사용된 것을 확인할 수 있다.
참고
- 하이버네이트는 Set에
@OrderBy를 적용해서 결과를 조회하면 순서를 유지하기 위헤HashSet대신에LinkedHashSet을 내부에서 사용한다.
2-2. @Converter
컨버터(converter)를 사용하면 엔티티의 데이터를 변환해서 데이터베이스에 저장할 수 있다.
예를 들어 회원의 VIP 여부를 자바의 boolean 타입을 사용하소 싶다고 하자.
데이터베이스에 저장될 때 0 또는 1인 숫자로 저장된다. 그런데 데이터베이스에 숫자 대신 문자 Y 또는 N 으로 저장하고 싶다면 컨버터를 사용하면 된다.
CRAETE TABLE MEMBER (
ID VARCHAR(255) NOT NULL,
USERNAME VARCHAR(255),
VIP VARCHAR(1) NOT NULL,
PRIMARY KEY (ID)
)위의 코드는 Member테이블의 create문이다.
매핑할 테이블을 보면 문자 Y. N을 입력하려고 VIP 컬럼을 VARCHAR(1)로 지정했다.
@Entity
public class Member extends BaseEntity {
private Long id;
...
@Convert(converter = BooleanToYNConverter.class)
private boolean vip;
...
}위의 코드에 있는 회원 엔티티의 vip 필드는 boolean 타입이다.@Converter를 적용해서 데이터베이스에 저장되기 직전에 BooleanToYNConter 컨버터가 동작하도록 했다.
BooleanToYNConter 컨버터를 보자.
@Converter
public class BooleanToYNConverter implements AttributeConverter<Boolean, String> {
@Override
public String convertToDatabaseColumn(Boolean attribute) {
return (attribute != null && attribute) ? "Y" : "N" ;
}
@Override
public Boolean convertToEntityAttribute(String dbData) {
return "Y".equals(dbData);
}
}컨버터 클래스는 @Converter 애너테이션을 사용하고 AttributeConverter 인터페이스를 구현해야 한다.
그리고 제너릭에 현재 타입과 변환할 타입을 지정해야 한다.
여기서는 <Boolean, String>을 지정해서 Boolean 타입을 String 타입으로 변환한다.
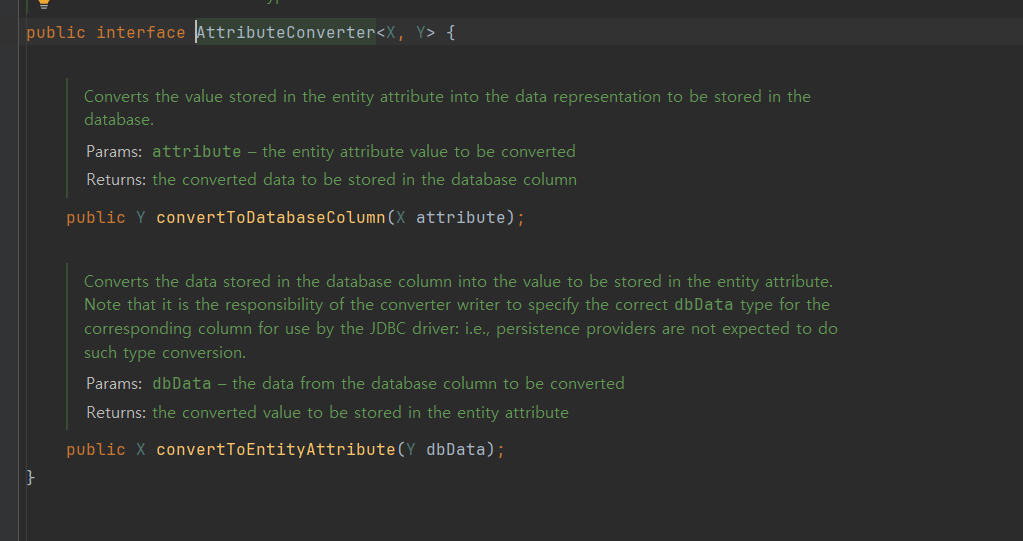
위의 코드와 같이 AttributeConverter 인터페이스에는 구현해야 할 다음 두 메서드가 있다.
public Y convertToDatabaseColumn (X attribute);- 엔티티의 데이터를 데이터베이스 컬럼에 저장할 데이터로 변환한다. 위의 BooleanToYNConverter 코드에서는 true면 Y를 false면 N을 반환하도록 했다.
public X convertToEntityAttribute (Y dbData);- 데이터베이스에서 조회한 컬럼 데이터를 엔티티의 데이터로 변환한다. 위의 BooleanToYNConverter 코드에서는 문자 Y면 true를 아니면 false를 반환하도록 했다.
이제 회원 엔티티를 저장하면 데이터베이스의 VIP 컬럼에는 Y 또는 N이 저장된다.
컨버터는 다음과 같이 클래스 레벨에도 설정할 수 있다.
단 이때는 attributeName 속성을 사용해서 어떤 필드에 컨버터를 적용할지 명시해야 한다.
@Entity
@Convert(converter = BooleanToYNConverter.class, attributeName = "vip")
public class Member {
...
private boolean vip;
}글로벌 설정
모든 Boolean 타입에 컨버터를 적용하려면 다음 예제와 같이 @Converter(autoApply = true) 옵션을 적용하면 된다.
(참고로 Convert가 아니라 Converter이다.)
@Converter(autoApply = true)
public class BooleanToYNConverter implements AttributeConverter<Boolean, String> {
@Override
public String convertToDatabaseColumn(Boolean attribute) {
return (attribute != null && attribute) ? "Y" : "N" ;
}
@Override
public Boolean convertToEntityAttribute(String dbData) {
return "Y".equals(dbData);
}
}이렇게 글로벌 설정을 하면 @Convert를 지정하지 않아도 모든 Boolean 타입에 대해 자동으로 컨버터가 적용된다.
@Convert 속성은 다음과 같다.
| 속성 | 기능 | 기본값 |
|---|---|---|
| converter | 사용할 컨버터를 지정한다. | |
| attributeName | 컨버터를 적용할 필드를 지정한다. | |
| disableConversion | 글로벌 컨버터나 상속 받은 컨버터를 사용하지 않는다. | false |
3. 요약
- JPA에서 컬렉션을 사용하면 JPA에서는 원본 컬렉션을 감싸는 내장 컬렉션을 생성해서 내장 컬렉션을 사용하도록 참조를 변경한다. 각 컬렉션마다 어떤 내장 컬렉션을 사용하는지 알아보았고, 그외
@OrderColumn과@OrderBy를 알아보았다. - 컨버터 기능을 이용해서 객체의 데이터를 데이터베이스에 원하는 데이터로 변환해서 저장하고 받아오는 방법을 알아보았다.
다음은 15장의 내용을 포스팅한다.
'Spring > JPA' 카테고리의 다른 글
| 실전! 스프링 데이터 JPA (인프런 - 김영한) (0) | 2024.02.18 |
|---|---|
| 자바 ORM 표준 JPA 프로그래밍 Ch.15. 고급 주제와 성능 최적화 (0) | 2024.02.16 |
| 자바 ORM 표준 JPA 프로그래밍 Ch.13. 웹 애플리케이션과 영속성 관리 (2) (2) | 2024.01.30 |
| 자바 ORM 표준 JPA 프로그래밍 Ch.13. 웹 애플리케이션과 영속성 관리 (1) (0) | 2024.01.29 |
| JPA로 Entity ID에 UUID 타입 사용하기(with. MySQL 8.x) (4) | 2024.01.24 |