
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 멀티 쓰레드
- 쓰레드
- 도커
- java network
- Collection
- Thread
- 자바 입출력 스트림
- 도커 엔진
- 자바 io 보조스트림
- 자바
- Kubernetes
- 동시성
- 쿠버네티스
- 김영한
- java
- 자료구조
- 컨테이너
- LIST
- 인프런
- 스레드 제어와 생명 주기
- container
- 리스트
- filewriter filereader
- Java IO
- java socket
- 스레드
- 알고리즘
- 실전 자바 고급 1편
- 시작하세요 도커 & 쿠버네티스
- Docker
- Today
- Total
쌩로그
넓고 얕게 외워서 컴공 전공자 되기 - 인프런(널널한 개발자) 본문
목차
- 포스팅 개요
- 본론
2-1. 16진수
2-2. 디지털 회로와 덧셈
2-3. 컴퓨터가 사칙연산을 수행하는 방법
2-4. 컴퓨터가 연산하는 과정
2-5. 컴퓨터가 기억공간을 관리하는 방법
2-6. HDD와 SSD
2-7. 동시성과 병렬성
2-8. 원자성, 동기화, 교착 상태
2-9. 컴퓨터의 구성요소와 아바타
2-10. 국가와 국민으로 이해하는 컴퓨터 세상
2-11. User mode와 Kernel mode 그리고 가상화까지!
2-12. 가상 메모리
2-13. 고급어와 저급어
2-14. 인터프리터(Interpreter)
2-15. API와 SDK
2-16. 자료구조와 알고리즘 - 요약
1. 포스팅 개요
인프런에서 널널한 개발자님의 '넓고 얕게 외워서 컴공 전공자 되기'를 출퇴근 길에 수강하면서 정리한 글입니다.
일단 1bit의 체계부터 알려주시는데, (주관적인 입장에서) 기초적인 부분은 생략하고, 정리하는 점 양해바랍니다.
2. 본론
2-1. 16진수
16진수는 한 자리가 4bit입니다.
16진수 표기가 사용되는 예는 다음과 같습니다.
- 색상 표현(RGB - Red, Green, Blue)
- 컴퓨터 하드웨어 주소 표현
- 메모리 값 표현
색상 표현시
예를 들어서 색상 중 #B7 1C 1C가 있을 때,
4bit가 2개씩 3개가 있으므로, 8bit *3 으로 24bit로 색을 표현합니다.
(도중에 8bit가 더 추가되어서 32bit로 표현된다고 합니다.)
컴퓨터 하드웨어 주소 표현
아래 그림과 같이 주소가 표현되어있는데, 저 값들의 대부분이 16진수 입니다.
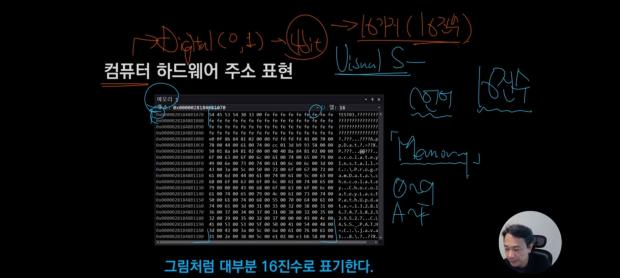
참고로, 단위 체계는 다음과 같습니다.
| 단위 | 크기 | 특징 |
|---|---|---|
| 1 Bit(비트) | 전기 스위치 1개 | 용량이 아니라 표현의 최소 수준. |
| 1 Byte(바이트) | 8비트 한 묶음 | 영문자 한 글자를 저장할 수 있는 기억 공간의 최소단위. 컴퓨터는 기억공간을 관리할 떄 1바이트 단위로 관리합니다. |
| 1 KB(킬로 바이트) | 1024 바이트 | 보통 JPEG 사진 파일 하나가 몇 백 KB 정도 됩니다. |
| 1 MB(메가 바이트) | 1024 킬로 바이트 | MP3 파일 하나가 대략 4~5 MB 정도 크기입니다. |
| 1 GB(기가 바이트) | 1024 메가 바이트 | 영화(.avi나 mp4) 파일 하나가 대략 2~6GB 정도 크기입니다. |
| 1 TB(테라 바이트) | 1024 기가 바이트 | 하드 디스크 1개 용량이 보통 1~2TB 정도 크기입니다. |
| 1 PB(페타 바이트) | 1024 테라 바이트 | 2016년 7월 기준 네이버 IDC센터 '갹(춘천)'의 규모는 약 900 PB 정도입니다. |
| 1 EB(엑사 바이트) | 1024 페타 바이트 | 64 비트를 용량으로 계산하면 16EB가 됩니다. |
| 1 ZB(제타 바이트) | 1024 엑사 바이트 | 20017년 기준 전 세계 데이터 센터 트래픽이 약 7.7 제타 바이트입니다. |
| 1 YB(요타 바이트) | 1024 제타 바이트 | 곧 다루게 될 대용량일 수 있습니다. |
1byte 는 영문자 한 글자가 저장될 수 있는 메모리 크기이며 관리의 최소단위입니다.
(한글 한 글자를 저장하려면, EUC-KR은 2byte, UTF-8은 3byte입니다.)
컴퓨터가 글자를 다룰 때
십진수 65는
컴퓨터에겐 영문 대문자 'A'
16진수로는 0x41입니다.
컴퓨터는 0과 1밖에 모릅니다. 따라서 A를 입력하면, 바로 A를 출력해주는 것처럼 보이지만, 실상은 내부적인 규칙에 따라, 그림으로 문자가 출력되는 것이라고 합니다.
그런데 컴퓨터 제조사마다, 값에 따라 출력되는 문자가 서로 달라서 표준 체계를 만들었는데, 그 표준 체계가 바로, ASCII 코드입니다.
ASCII
American Standard Code for Information Interchange의 약자로서 미국에서 사용하는 표준 코드체계입니다.
바이너리(Binary)
숫자와 글자를 구별하지 않고 정보를 말할 때 바이너리(Binary)라고 합니다.
아래는 메모장에서 다음 문구를 바이너리로 표현한 것입니다.
Hello World!
Hi.
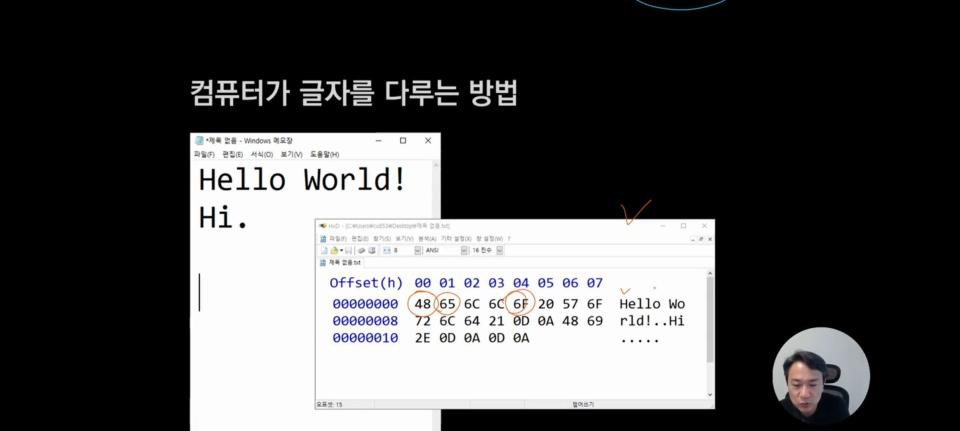
보시면, 끝에 0D 0A가 보이는데,
이 0D 0A는 개행 문자의 바이너리 값입니다.
또 Hello 라인에서 20번을 볼 수 있는데, 20은 띄어쓰기에 대한 바이너리 값입니다.
컴퓨터가 사진을 다루는 방법
모니터상 '점' 하나를 화소(pixel)이라고 합니다.
여러점들을 모아 하나의 사진으로 만들 수 있습니다.
화소 하나를 표현하는데, RGBA 각각 8bit씩하여, 32bit(4byte)로 표현할 수 있습니다.
- RGB는 레드, 그린, 블루를 의미하는데, A는 투명도를 의미하는 Alpha를 나타냅니다.- 참고로 화소가 작을수록 사진이 더욱 매끄럽습니다.(고해상도)
바탕색(실제 색이 필요하지 않은 영역)은 검은색, 혹은 흰색으로 나태날 수 있는데, 사진을 있는 데이터정보로 그대로 표현하면 용량이 커집니다. 따라서 바탕색을 제외하고 보통은 실제 데이터 정보들로 압축하여 사진을 나타냅니다.
(각 픽셀의 정보를 일일이 나열한 것을 rowbitmap 이미지라고합니다.)
사진을 압축한 것들이 jpg jpeg png gif 등등이 있습니다.
2-2. 디지털 회로와 덧셈
게이트 회로에 4가지가 있습니다..
AND는 모두가 참이어야 참,
OR는 하나라도 참이면 참,
XOR는 서로 다를 때 참 같으면 거짓,
NOT은 결과를 뒤집습니다.
이런 디지털 회로로 CPU를 만듭니다.
CPU는 원래 전자식 계산기입니다.
전자식 계산기는 산수계산을 합니다.
산수계산 중 사칙연산을 어떻게 할것이냐에서 CPU가 출발했습니다.
CPU를 만들고 싶다면 사칙연산 계산기를 만들면됩니다.
2-3. 컴퓨터가 사칙연산을 수행하는 방법
덧셈
컴퓨터는 이진수를 통해서 덧셈 연산을 수행합니다.
이진수 연산을 XOR와 AND연산을 통해서 덧셈을 연산하게 되는데, 그 연산을 전가산기라는 계산기를 이용해서 합니다.
전가산기에 대한 부분은 여기 이 링크에 제가 풀어놨습니다.
뺄셈
뺄셈 또한 덧셈을 이용합니다.
바로 보수를 이용하는데요.
보수는 기준 값이 있습니다.
어떤 임의의 수 n,m이 있고, m이 n보다 작을 때, n에 대한 m의 보수는 n-m입니다.
예를 들어, 10, 6 이 있을 때, 6이 10보다 작으며, 10에 대한 6의 보수는 10-6인 4입니다.
그럼 보수에 대한 예기를 꺼낸 이유는 바로 컴퓨터카 뺄셈을 할 때, 보수를 사용해서 연산을 하기 때문입니다.
컴퓨터는 2진수로 연산을 한다고 했는데,
어떤 임의의 2진수에 2의 보수를 더하면, 자동적으로 뺄셈 연산이 됩니다.
가령 10진수의 13과 6을 생각해보겠습니다.
그리고 4bit 연산을 수행해보겠습니다.
10진수 13은 2진수로 1101입니다.
10진수 6은 2진수로 0110입니다.
(4bit 기준입니다.)
13 - 6 = 7입니다.
7의 결과가 나와야 하는데,
이 때 13에서 "6의 2의 보수"를 구하여 더해주면 7이됩니다.
참고로 2의보수는 1의 보수에 1을 더한 것입니다.
6의 2의보수를 구해보도록 하겠습니다.
6의 1의 보수를 구합니다.
그냥 2진수 6에서 0은 1로, 1은 0으로 바꿔주면 됩니다.
0110 => 1의 보수 => 1001입니다.구한 1의 보수에 1을 더하여 2의 보수로 만들어줍니다.
1001 에 1을 더하면, 1010입니다.13과 6을 2의 보수로 만든 결과를 더해줍니다.
1101 + 1010 의 결과는
10111 입니다.
그런데 우리는 4bit 연산을 하고있습니다?
10111은 5자리이므로 제일 앞의 한자리를 제외시킵니다.
그럼 결과는 0111인데, 이를 10진수로 바꾸면, 4+2+1 = 7
네..
13-6=7인데,
13에 6의 2의보수를 더한 결과도 7입니다.
이처럼 뺄셈은 어떤 수의 2의 보수를 구하여 더해주면, 자동적으로 뺄셈 연산이 일어나는 것입니다.
곱셈
곱셈과 나눗셈은 shift연산을 이용해서 이루어집니다.
곱셉은 왼쪽으로의 shift, 나눗셈은 오른쪽으로의 shift로 생각하면 됩니다.
곱셈에 대한 과정을 보면 가령 예를 들어서 10진수 5에 곱하기 2를 한다고 하면,
2는 2^1(2의 1승)이기때문에, 한 칸을 왼쪽으로 밀어주면(shift) 됩니다.
4비트를 예로 들겠습니다.
10진수 5는 2진수로 0101인데,
왼쪽으로 shift 하게 되면 즉, 밀게되면
01010입니다.
이 때 가장 앞자리에 있는 0은 잘리게됩니다.(4비트라서)
결과는 1010인데, 1010은 10진수로 8입니다.
그리고 왼쪽으로 shift하면서 오른쪽에 0으로 채워지는 것을 padding이라고 합니다.
그럼 만약 10진수 5에 3을 곱하면 어떻게 될까요?
일단, 0101을 왼쪽으로 shift 연산을 하면 2가 곱해진 결과잖습니까?
거기에 0101을 더해주면 됩니다.
01010 : 10진수에 shift해줌으로 * 2를 한 결과에
0101 을 더해줍니다.
이를 더해주면 1111이 나오는데, 2진수 1111은 10진수 15입니다.
정확히 5에 곱하기 3을 해준 결과입니다.
만약 4를 곱하게 되면, 4는 2^2(2에 2승)이므로 왼쪽으로 두 번 밀어주면(shitt)됩니다.
그리고 오른쪽에 밀린 두칸에 0으로 채워주면(padding) 됩니다.
ex) 0101 * 4 = 010100
(만약 4bit라면 오버플로우가 발생하여 0100이 되겠죠?)
그럼 2의 승수에 가까운 수가 아니라면?
2의 승수에 가깝다는 의미는 제가 표현을 어떻게 해야될지 몰라서 이렇게 적었습니다만,
2^1, 2^2, 2^3 등 2, 4, 8 이런식으로 2에 2를 곱해나가는 수를 의미합니다.
2의 지수에 따라서 shift 연산을 해주면 되는데,
만약 6, 혹은 10 과 같이 2의 승수에 가까운 수가 아니라면, 연산을 어떻게 해야할까 생각해보았습니다만 간단하더군요...
가령 6을 곱한다고 예를 들어보겠습니다.
6은 2+4입니다.
따라서, 어떤 임의의 수에 1칸(2^1) shift한 연산과 2칸(2^2) shift한 연산을 더해주면됩니다.
이번에 6비트로 한 번 생각해보겠습니다.
10진수 5는 0101이고, 6을 곱하면 10진수로는 30, 2진수로는 11110입니다.
계산해본다면
0101 에 2를 곱한다면, 왼쪽으로 1번 shift연산을 수행하면 됩니다.
0101 에 4를 곱한다면, 왼쪽으로 2번 shift연산을 수행하면 됩니다.
0101 * 2 = 01010
0101 * 4 = 010100
2를 곱한 것과 4를 곱한 것을 더하면
011110입니다. 이를 10진수로 환산하면, 30이 되네요
5 * 6은 당연히 30인데, 2진수로의 곱셈 또한 결과가 정확히 같습니다.
나눗셈
나눗셈은 오른쪽으로의 shift연산을 통해 이루어집니다.
4비트를 예로 들었을 때, 곱셈은 왼쪽으로 shift연산을 하여 오른쪽에 padding(0으로 채워짐)이 이루어졌고, 왼쪽에서 잘림이 발생했습니다
나눗셈은 그 반대로 오른쪽으로 shift연산을 하여 왼쪽에 padding이 이루어지고, 오른쪽에서 잘림이 발생합니다.
가령 예를 들어 10진수 6은 2진수의 4비트로 나타내면,
0110입니다.
이를 2로 나누면, 10진수로는 3이고, 2진수로는 0011입니다.
0110 을 오른쪽으로 shift연산해준다면,
0011이 되고, 0011은 10진수로 3이 됩니다.
그런데, 나눗셈의 동작방식은 정말 많이 복잡합니다...
shift 연산으로 하려면, 나누려는 수(나눔을 당하는 수라는 의미인지는 모르겠지만, 피제수라고 합니다)가 몇 비트인지 알아야되고, shift연산도 피제수의 비트수만큼 하면 되는데,
shift 연산과 뺄셈을 이용하여 이루어집니다.
예를 들어 10진수 7을 3을 나누면, 몫은 2, 나머지는 1입니다.
이를 간단하게 3bit로 잡아보자면,
7은 111
3은 010
입니다.
한번 해보도록 하겠습니다.
3bit이기 때문에, 앞에 shift 연산을 통해서 옮겨질 3bit와 피제수의 3bit를 생각하고, 예를 들어보겠습니다.
그리고 제수(나누는 수 : 여기선 3)는 오른쪽에 표시해보겠습니다.
몫도 표시해보겠습니다. 몫은 일단 xxx로 채우겠습니다.
피제수 : 000 111 제수 : 011 몫 : xxx
첫 번째 쉬프트 연산 후,
피제수 : 001 110 제수 : 011 몫 : xxx
쉬프트 연산 후, 왼쪽의 3bit와 제수를 비교합니다.
001 과 011 인데,
001 에서 011을 빼지 못합니다. 그럼 못의 첫 번째 비트에 0으로 채웁니다.
첫 번째 쉬프트 연산에 대한 결과는 다음과 같습니다.
피제수 : 001 110 제수 : 011 몫 : 0xx
이제 두번째 쉬프트 연산을 수행합니다.
두 번째 쉬프트 연산 후,
피제수 : 011 100 제수 : 011 몫 : 0xx
두 번째 쉬프트 연산 후, 왼쪽의 3bit와 제수를 비교합니다.
011 과 011 인데,
011 에서 011은 뺄셈이 가능합니다.
따라서 011 에서 011을 빼주면 000 이 되고, 몫의 두 번째 비트에 1로 채웁니다.
두 번째 쉬프트 연산에 대한 결과는 다음과 같습니다.
피제수 : 000 100 제수 : 011 몫 : 01x
이제 세번째 쉬프트 연산을 수행합니다.
세 번째 쉬프트 연산 후,
피제수 : 001 000 제수 : 011 몫 : 01x
새 번째 쉬프트 연산 후, 왼쪽의 3bit와 제수를 비교합니다.
001 과 011 인데,
001 에서 011은 뺄셈이 불가능합니다. 따라서 못의 세 번째 비트에 0으로 채웁니다.
따라서 쉬프트 연산에 대한 결과는 다음과 같습니다.
피제수 : 001 000 제수 : 011 몫 : 010
7나누기 3은 몫이 2이고, 나머지가 1입니다.
그대로 나왔습니다.
shift 연산 최종의 피제수가 001 인데, 이는 나머지를, 몫이 010인데, 십진수로는 2입니다.
그런데 이 위의 과정은 그냥 우리가 아는 뺄셈과정이고, 컴퓨터의 뺄셈은 빼려는 수의 2의 보수를 더하는 것입니다.
그래서 사실 나눗셈에 대한 부분은 잘 모르겠다는 것이고,
쉬프트 연산을 이용한 나눗셈의 매커니즘은 이와 같다고 생각하시면 될거 같습니다.
(내년에 방통대 편입예정인데, 컴퓨터 구조 과목에서 이를 해결해보길 기대해봅니다.)
쉬프트 연산 말고 다른 방법도 있습니다.
피제수에서 제수를 계속 뺄셈을 하고 남은 값을 제수와 대소비교를 해가면서 뺄셈을 못 할 때까지 계속해서 빼는 것입니다.
직접 해보니 이 방식은 2의 보수에 대한 처리도 가능했습니다.
가령 예를 들어, 8을 3으로 나누면 몫은 2이고, 나머지도 2입니다.
4bit로 처리해보면,
일단,
8은 1000,
3은 0011 입니다만, 뺄셈을 해야하기 때문에 3에 대한 2의 보수는 1101입니다.(그냥 1의 보수에 +1하면 됩니다.)
즉, -3 은 1101입니다.
이를 이용해서 나눗셈을 해보면 되는데, 나눗셈을 뺄셈의 연속입니다.
1000과 0011을 비교합니다. 1000이 크죠?
다시 얘기해보자면,
"8과 3을 비교합니다. 8이 크죠?" 이 말입니다.
10진수는 아래에 괄호로 표시하겠습니다.
다시 처음부터..
1000과 0011을 비교합니다. 1000이 크죠?
(8과 3을 비교합니다. 8이 크죠?)
1000과 0011을 가지고 뺄셈을 하는데, 뺄셈은 2의보수를 더한 것이니, 0011의 2의 보수인 1101을 더합니다.
1000
1101 +
0101 입니다. 그리고, 몫에 1을 더합니다.(몫은 보기 쉽게 10진수로 표현하겠습니다.)
일단 0101에 몫은 1입니다.
또 다시 뺄셈을 하도록 하겠습니다.
0101 과 0011을 비교합니다. 0101이 크죠?
(5와 3을 비교합니다 5가 크죠?)
0101과 0011의 2의 보수를 더해줍니다.
0101
1101 +
0010 입니다. 뺄셈이 이루어졌으니 몫에 1을 더합니다. 몫은 2입니다.
그리고, 0010과 0011을 비교합니다.
0011이 더 크기 때문에 뺄셈을 할 수 없습니다.
따라서 남은 0010이 나머지이고(10진수로는 2), 목은 2입니다.
즉, 8에서 3을 나눈 그대로 이루어진 것입니다.
흠.. 양수는 이렇게 떨어지는데, 음수는 정말 모르겠습니다..(역시 내년에 방통대에서 해결할 수 있길 기대해봅니다.)
그럼 다음으로 넘어가겠습니다.
한 가지만 더 생각해보면, 만약 0을 나눈다면 어떻게 될까요?
나눗셈은 뺄 수 있을 때까지 빼는 방식이라는 것을 아셨을 겁니다.
그럼 0을 나눈다면...
무한정 뺄셈이 이루어질 것입니다.
예전에는 cpu가 터질 정도였다고 하지만, 지금은 운영체제나 프로그램에서 막아놔서 그럴 정도는 아니라고 합니다.. ㅋㅋ
이제 ㄹㅇ 다음으로 가보겠습니다!
2-4. 컴퓨터가 연산하는 과정
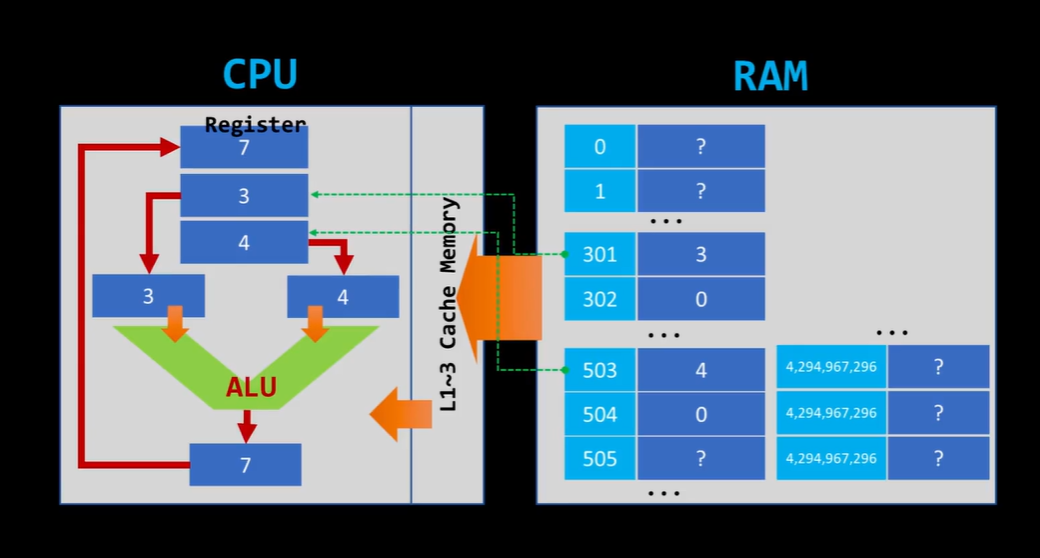
컴퓨터라는 기계는 기본적으로 CPU가 컴퓨터입니다.
나머지는 CPU를 보조하는 장치들입니다.보통 RAM까지 포함하여 생각한다고 합니다.
CPU와 RAM
CPU는 말 그대로 연산하는 장치이고,
RAM은 저장용도로 쓰입니다.
그래서 CPU는 비메모리, RAM은 메모리라고 합니다.
메모리는 공간마다 메모리 주소가 있고 각 메모리 주소마다 값들을 가지고 있습니다.
마치 자료구조의 map과 같은 구조입니다.
메모리 주소는 key에, 값이 value에 있다고 생각하면 될것 같습니다.
그리고, 메모리 주소에 해당하는 값을 가져와서 cpu의 레지스터에 담습니다.
※참고로 레지스터마다 이름들이 있습니다.메모리에서 불러온 값들을 가지고 ALU(Arithmetic Logical Unit)에서 연산을 수행하고, 주어진 메모리(주소)의 값으로 저장되는 방식으로 연산을 수행합니다.
정리하자면, 다음과 같습니다.
- 메모리에서 값들을 참조하여 레지스터에 담는다.
- 메모리로부터 불러와서 레지스터에 저장된 값들을 ALU를 가지고 연산을 수행한다.
- 운영체제나 CPU의 로직에 의해서 주어진 메모리(주소)의 공간에 값을 담는다.
2-5. 컴퓨터가 기억공간을 관리하는 방법
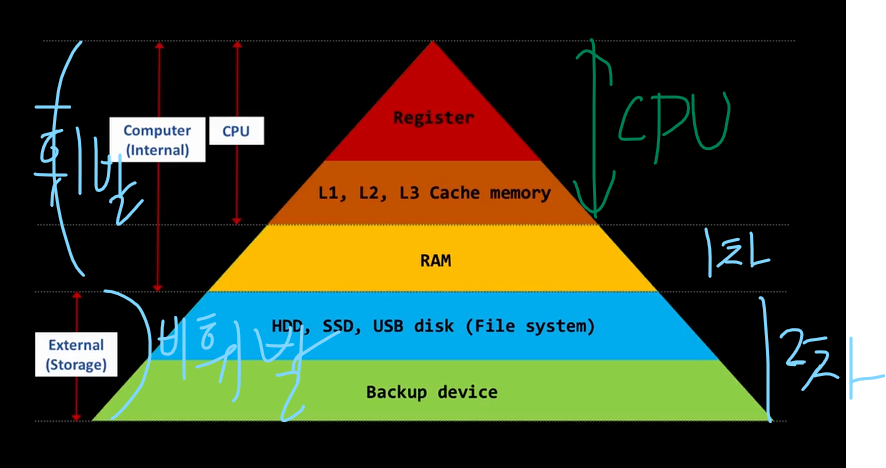
컴퓨터는 혼자 작동을 하지 못합니다.
메모리와 함께 있어야 작동할 수 있습니다.
메모리에는 1차 메모리와 2차 메모리가 있는데, RAM 정도 수준의 메모리를 1차 메모리, HDD, SSD 와 같은 저장 장치들을 2차 메모리라고 합니다.
2차 메모리부터 External Storage라고 하는데, 이들을 주변기기라고 보시면 됩니다.
CPU가 연산을 할 떄는 Register까지 메모리에 있는 정보를 가지고와야 그때부터 연산을 하게됩니다.
문제는 CPU의 연산이 정~마알 빠르다는 겁니다.
CPU의 연산 속도가 4점대의 기가헤르츠(GHz)입니다.
RAM은 1점대 기가헤르츠(GHz)의 속도로 디스크에서 파일을 읽어오거나 저장합니다.
그런데 2차 메모리 영역은 겁나게 느립니다..
비유를 하자면 CPU가 비행기의 속도라면, 2차메모리는 사람이 기어가는 정도입니다. 갭이 어마무시하죠...
2차 메모리와 CPU 속도의 간극을 메우기 위해서 1차 메모리의 영역이 있습니다.
그리고, CPU(Register)로부터 1차 메모리의 RAM까지의 영역은 휘발성이 있습니다. 즉, 전원을 끄면 다 날라갑니다.
반면에, 2차 메모리 영역은 휘발되지 않습니다.
(만약 2차 메모리의 속도가 빨라진다면 RAM이 아마 필요없을 것이라고 합니다.^^)
그리고 Register와 1차 메모리 중간에 캐시 메모리가 있습니다.
CPU가 연산을 할 때 RAM에서 정보를 읽어와서 레지스터를 통해서 연산을 한다고 하였는데, 사실 레지스터로 정보를 가져와서 연산을 하기 전에 캐시메모리를 거쳐서 레지스터로 오게 됩니다.
CPU가 연산을 빠르게 하고, RAM과의 속도 차이를 줄이기 위해서 캐시 메모리를 이용하는데, 캐시메모리는 CPU가 연산을 하기 위해서 필요한 정보를 미리 예측하여 RAM에서 정보를 가져와 저장해놓습니다.
물론 예측하여 얻어놓은 정보가 예측과 다를 때는 RAM에서 정보를 읽어옵니다. ^^
만약 RAM에도 없다? 그럼 2차 메모리 영역인 HDD, SSD에서 정보를 가져옵니다.
그리고 레지스터, 주 기억장치(RAM), 보조 기억장치(HDD, SSD)를 관리하는 방법은 조금씩 다릅니다.
- 레지스터는 개별 기억공간마다 고유 이름을 붙여 관리합니다.
- 주 기억장치는 일련번호를 붙입니다.
- 보조기억장치는 트랙(Track) 번호와 섹터(Sector)번호를 붙여 관리합니다.
2-6. HDD와 SSD
HDD와 SSD는 위에서 보셨다시피 2차 메모리입니다.
HDD
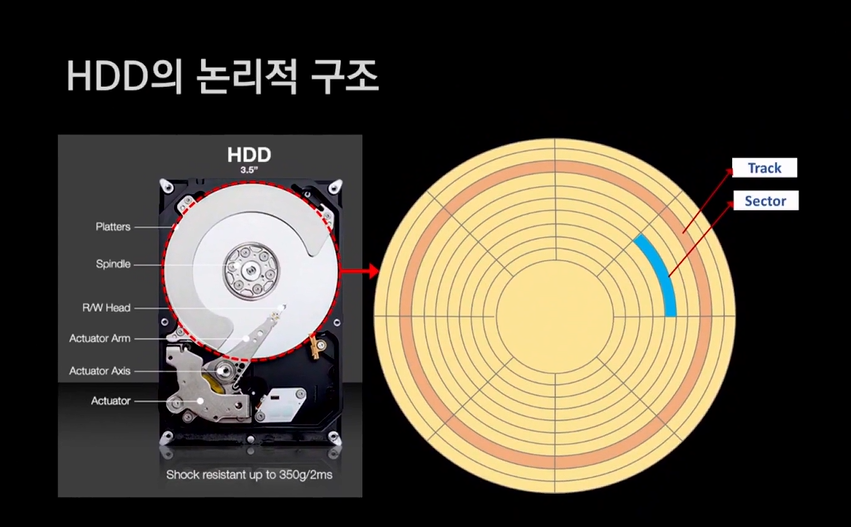
하드 디스크(HDD)의 스펙을 얘기할 때는 회전 속도를 얘기합니다.
하드 디스크의 관리 체계는 Track과 Sector입니다.
비유하자면 Track은 아파트의 동, Sector는 호라고 생각하면 됩니다.
논리적인 얘기지만, 하나의 Sector에 읽기/쓰기가 자주 일어나면 물리적으로 디스크가 손상되고 손상된 Sector를 Bad Sector라고 합니다.
디스크의 조각모음
조각모음이란 것은 보통 윈도우에서 보셨을 겁니다.
한 Sector당 512KB로 가정하겠습니다.
용량이 100KB인 하나의 파일을 Sector에 저장합니다.
그러면 HDD에서 다른 파일을 저장할 때 과연 남은 412KB의 영역에 이어서 저장하게 될까요? 꼭 그렇진 않습니다. 다른 빈 Sector에 저장하게 되겠죠..
그리고 반대로 512KB를 넘어가는 파일이 있다면 하나의 Sector를 다 차지하여 저장하고 남은 용량에 대해서 다음 Track에 저장하려하는데...트랙이 이어져서 저장된다면 저~~엉말 좋겠지만, 그것도 그렇지 못 하다는 것입니다.
남은 Sector들을 찾으며 각 Sector들을 뛰어넘어 저장하게 됩니다.
이렇게 디스크에 흩어져서 저장된 파일들을 입/출력을 하게 되면 디스크가 한 번 더 돌아야 파일들을 읽을 수 있습니다.
이는 성능에 문제점이 생길 수 있습니다.
이렇게 흩어진 파일 조각들을 모으는 것이 바로 디스크의 조각 모음입니다.
디스크의 조각모음을 통해서 트랙이 이어져서, 한 번에 전체 파일을 읽을 수 있습니다.
파일 시스템
운영체제마다 File Allocation Table(이하 FAT)가 있는데, 몇 번 트랙에 몇 번 섹터에 어떤 파일이 있는지를 기록하는 표입니다.
그리고, 파일을 삭제하면 실제 디스크에서 파일을 삭제하는 것이 아니라, FAT에서 해당 파일이 삭제한 파일이라는 표시(마킹)만 해놓습니다.
그리고 디스크 복원을 하려할 때, 실제 데이터 지워진 것이 아니고, 마킹만 지워졌다는 표시가 되어있으므로 실제 데이터가 있는 트랙과 섹터를 찾아서 파일을 복원시킵니다.
그리고 0번 트랙, 0번 섹터에 파일이 있습니다.
여기에 해당 되는 파일 시스템이 바로 MBR(Master Boot Record)이라고 하는데 이는 운영체제의 부트 로더 코드입니다.
그리고 컴퓨터 전원을 켤 때 운영체제가 프로그램들을 하나씩 메모리에 적재해서 실행하게 되는데 이 과정이 바로 부팅 입니다.
Format
포맷에는 빠른 포맷과 느린 포맷이 있습니다.
빠른 포맷은 File Allocation Table를 전부 날리는 것이고,
느린 포맷은 전체 트랙과 섹터를 전부 0으로 오버라이드 하는 것입니다.
SSD도 위에 나와있는 HDD와 똑같은 방식으로 작동하는데,
단지 HDD와 다른 것은 디스크가 아니라, 칩으로 관리한다는 것입니다.
그리고 SSD 같은 경우에는 디스크 조각모음 같은 걸 할 필요가 없습니다.
2-7. 동시성과 병렬성
동시성
동시성이란 여러 가지 일이 동시에 진행되는 것입니다.
실생활에서 예를 들면 어떤 프로그램을 다운로드 받으면서 크롬 브라우저에서 유튜브를 보는 것과 같은 것입니다.
이처럼 상호간섭 없이 동시에 연산하고 실행되기 때문에 이런 경우 동시성이 있다고 표현할 수 있습니다.
병렬성
병렬성이란 같은 일을 여러 주체가 함께 동시에 진행되는 것입니다.
실생활에서 예를 들면 인형에 눈 붙이기라는 똑같은 일울 여러 명이 동시에 하는 경우를 생각할 수 있습니다.
2-8. 원자성, 동기화, 교착 상태
화장실에 볼 일을 보러가는 예로 쉽게 이해해볼 수 있습니다.
1. 몸에 신호가 온다.
2. 화장실로 이동한다.
3. 노크로 칸을 누가 쓰고 있는지 확인 한다.
4. 없으면 진입한다. 문을 잠근다(Lock)
5. ~ 6. 생략
7. 칸에서 나온다.(UnLock)
8. 손을 씻는다.
9. 화장실을 나온다.
원자성
위의 화장실의 예시에서 4~7번까지의 예를 보면 문을 잠그고, 7번에선 잠근 문을 열고 있습니다.
즉 화장실이라는 자원을 사용함에 있어서 Lock을 걸고, 수행할 일을 끝내면 Lock을 걸었던 자원에 대해서 UnLock을 하는 것입니다.
이러한 Lock의 구간부터 UnLock까지의 구간을 원자성이 보장되는 구간이라고 합니다.
앞에서 살펴본 동시성처럼 여러 가지의 일이 동시에 진행되는데,
여러 가지의 일을 동시에 수행하는데 필요한 자원이 하나일 때 단 하나의 일만 그 자원을 선점해서 사용할 수 있습니다.
그러한 선점 과정에서 하나의 일이 자원을 선점하여 Lock ~ UnLock 되는 구간까지를 원자성이 보장된다고 표현합니다.
마치 여러 일이 일어나더라도 화장실에 들어간 사람만이 승자와 같은 여유를 느낄 수 있는 것(?)처럼 말입니다...?
동기화
동기화는 원본과 사본이 있을 때 원본이 바뀌면 사본도 바꿔주는 부분 또한 동기화라고 할 수 있지만,
운영체제와 컴퓨터 구조에서의 동기화는 자원의 통제 같은 개념입니다.
마치 신호등을 통해서 교통을 정리하거나, 화장실에 들어간 사람이 곧바로 Lock을 걸고 나갈 때 UnLock을 하는 것처럼 말입니다.
※ 참고로 Lock과 같이 잠금장치 같은 경우는 운영체제에서 제공합니다.
교착 상태
교착 상태는 영어로 Deadlock입니다.
교착 상태는 사자성어로 진퇴양난 같은 느낌입니다.
이러지도 못하고 저러지도 못하는 것입니다.
예를 들면, 철수라는 사람이 화장실을 들어갔습니다.
그런데 화장실에 보니깐 휴지가 없습니다...
휴지가 없어서 못 나가는데 밖에는 사람이 겁나게 기다리고 있습니다.
그리고, 겁나게 기다리고 있는 사람들 중, 한 사람은 휴지를 가지고 있습니다.
휴지가 있지만, 철수가 나와야 그 분들은 볼일을 볼 수 있습니다.
이러지도 못하고 저러지도 못하는 화장실이라는 자원에 대해서 Deadlock이 걸린 것입니다.
교착상태 Deadlock은 프로그램을 잘 못 설계한 것에서 기인한 논리적인 오류입니다.
이런 교착상태를 막기 위해 Lock도 걸고, 동기화를 하는 것입니다.
하지만 원자성을 보장 받았지만 외부 자원에 대해 의존성이 존재하는 일들이 동시에 발생될 때 교착상태가 발생할 수도 있습니다.
마치 화장실 칸은 잘 정리가 되었지만, 휴지 때문에 이러지도 저러지도 못하는 상황이 발생한 것처럼 말입니다.
이 예시에선 휴지가 외부 자원에 해당됩니다.
2-9. 컴퓨터의 구성요소와 아바타
컴퓨터는 H/W와 S/W로 구성됩니다.
S/W는 Application과 System S/W로 구분되고, System S/W의 가장 대표적인 S/W는 OS(Operation System)입니다.
OS를 보기 전에 간단히 어휘정리를 해보겠습니다
프로그램, 프로세스, 스레드
- 프로그램은 설치하는 것입니다.
- 설치된 프로그램을 실행하면 프로세스가 생성됩니다.
- 프로세스는 프로세스 아이디라는 PID를 가집니다(마치 주민등록번호와 유사합니다).
- 스레드는 프로세스 속에 존재하는 실행단위 입니다.
- 스레드는 프로세스에게 할당된 자원을 공유합니다.
- 여기서 자원은 기본적으로 메모리를 사용하면 됩니다.
메모리는 공간에 따라 여러 형태로 나뉘는데 대표적으로 Stack, Heap 등이 있습니다.
Stack은 스레드가 Heap은 프로세스 전체가 사용합니다.
Heap은 공유되는 메모리공간입니다. 마치 집에서 거실과 같은 공간입니다.
반면에, Stack은 스레드 하나만 사용할 수 있습니다. 마치 집에서 각자의 방이 있는 것처럼 말입니다.
그리고 컴퓨터의 세상에서 프로세스의 형태로 기본적으로 존재하는 것이 있습니다. 바로 쉘(Shell)입니다.
2-10. 국가와 국민으로 이해하는 컴퓨터 세상
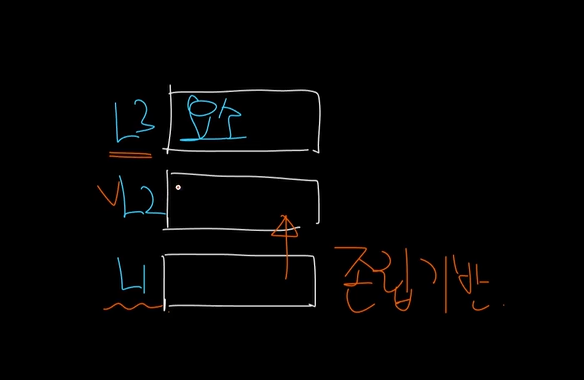
위의 그림은 계층에 대한 설명을 위한 그림입니다.
위에서부터 차례로 L3, L2, L1이 있다고 가정했을 때,
L1은 L2에 대한 존립 기반이 됩니다.
즉 L1이 없으면 L2가 존재하지 않습니다.
마치 건물에서 1층이 없으면 2층이 있을 수 없는 것처럼 말이죠..
존립 기반을 다르게 얘기하면, 전제 조건이라고도 표현할 수 있습니다.
그리고 L2는 L1에 대해서 존립의존적이라고 할 수 있습니다.(실제 의존적입니다.)
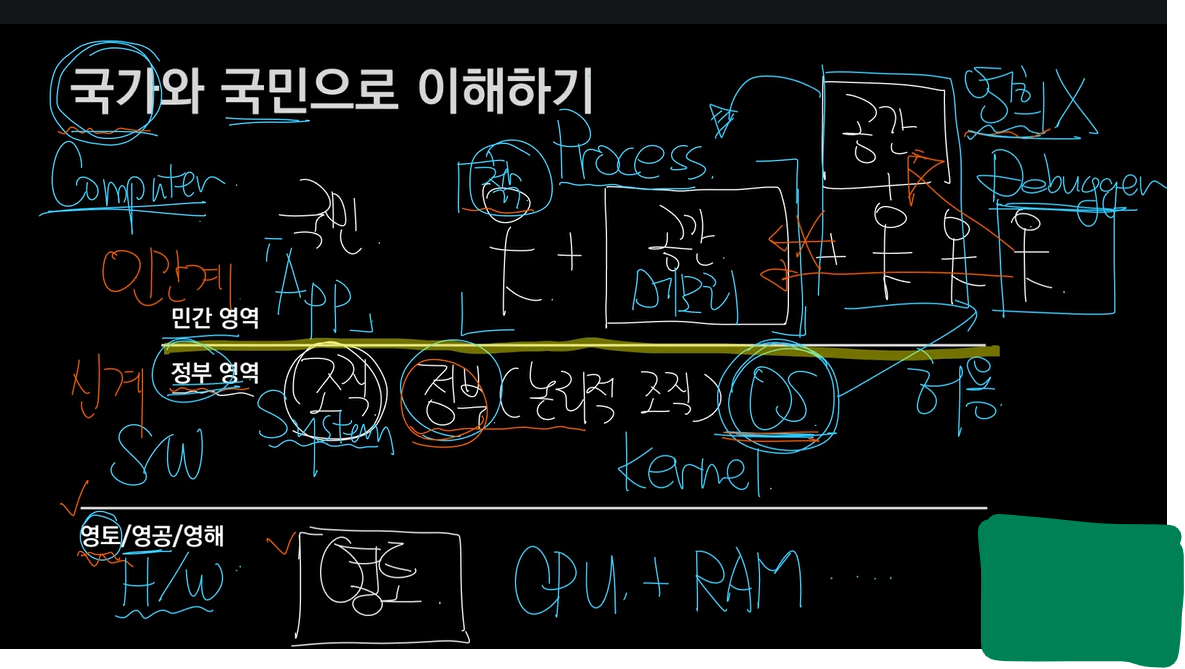
위의 그림은 국가와 국민으로 H/W, System S/W, Application을 비유한 그림입니다.
국가가 세워지기 위한 3요소로 영토, 영공, 영해가 있습니다.
그리고 그 위에 정부가 수립되고, 수립된 정부 조직 안에서 국민이 존재하게 됩니다.(사회가 아닙니다. 비유이니 참고만 해주세요.)
그럼 위의 그림(비유)은 과연 무엇을 말하는 것인가..
영토, 영공, 영해는 컴퓨터에서 H/W를 의미합니다.
그리고 영토, 영공, 영해를 기반으로 한 국가에서 정부가 수립되는 것은 컴퓨터에서 H/W 기반 위에 실행되는 System S/W 즉 운영체제를 의미합니다.
그리고 국가 안에서 국민들이 국가의 법과 질서로 공간(집)을 가지고 사는 것은 컴퓨터에서 운영체제의 시스템 통제하에 메모리를 가지고 실행되는 각 Application을 비유합니다.
조금 더 자세히 말하자면, 프로그램이 실행되면 메모리에서 공간을 가지며 프로세스가 생성되는데, 집을 가진 국민들을 프로세스에 비유할 수 있습니다.
그런데 만약 집을 가진 두 사람 A, B가 있습니다.
B가 A집에 함부러 드나들 수 없듯이 하나의 프로세스가 다른 프로세스의 메모리를 넘볼 수 없습니다.
만약 메모리를 넘보게 되면 운영체제는 Access Violation 오류를 일으키는데, 이 오류는 흔히 얘기하는 "프로그램이 죽었다"라고 표현하는 그 오류입니다.
(그렇다고 합니다..)
그러나 실상은 프로그램이 죽은 것이 아니라, 운영체제가 프로그램을 멈추는 것입니다.
그리고 이렇게 프로세스가 여러 개 동시에 존재하는 것을 멀티태스킹 환경이라고 합니다.
각 프로세스마다 동시성이 있는 것입니다.
참고로 OS가 프로세스의 자원을 접근하려 할 때 막는다고 했는데, OS가 특별히 허락하는 프로그램이 있습니다.
바로 디버거(Debugger)입니다.
그리고 운영체제의 핵심은 Kernel입니다.
위의 그림에서 민간 영역과 정부 영역이 줄로 나눠져있습니다.
즉 OS와 Application의 영역이 나눠져있는데, 얼마만큼 차이가 날 정도로 나누어져있는가...비유하기를 인간계와 신계의 차이라고 합니다.
즉 그만큼 차이가 크다는 것입니다.
2-11. User mode와 Kernel mode 그리고 가상화까지!
운영 체제의 핵심은 Kernel입니다.
Kernel
커널의 특징은 다음과 같습니다.
- 정보의 입출력을 제어합니다.
- 자원을 관리합니다.
- 여기서 자원이란 CPU와 메모리를 포함합니다.
- 이 CPU를 어떤 프로세스가, 어떤 스레드가 얼마나 쓸 것인지를 통제합니다.
- 접근 통제를 합니다.
운영체제의 핵심은 kernel인데, 이를 계층인 동시에 mode라고도 표현합니다.
보통 S/W가 작동한다는 것은 일반적으로 user mode Application 계층에서 작동하는 것을 의미합니다.
만약 kernel모드에서 작동을 한다고 하면, 운영 체제의 일부에서 작동한다고 보면 됩니다.
※참고로 Kernel 영역에서 작동하는 소프트웨어 중, OS가 아닌 부분에는 보안과 관련된 부분이 있습니다.
컴퓨터는 H/W와 S/W가 있고, S/W는 OS영역의 Kernel mode와 Application 영역의 User mode가 있습니다.
H/W는 물리적이기 때문에, Physical하다고 합니다.
S/W는 H/W와는 다르게 논리적이기때문에, Logical이라고도 하는데, Logical은 다른 표현으로 Virtual이라고도 합니다.
그리고 운영체제는 H/W에 의존적입니다.
그래서 나오는 말이 Platform인데, 이 단어는 OS에서도 하고, H/W에서도 합니다.
Platform이라는 것은 다른 것들이 일을 수행할 수 있도록 환경을 제공하는 것인데, H/W에서도, S/W에서도 쓰입니다.
예를 들어 64비트 플랫폼이라고하면, CPU도 64비트, OS도 64비트가 되는 것입니다.
컴퓨터에는 메인보드에 장착할 수 있도록 하는 디바이스 장치가 있습니다.
그리고 OS가 어떤 OS냐에서 상관없이 디바이스에 접근하기위해 커널에서 작동하는 소프트웨어가 있는데, 이를 디바이스 드라이버(Device Driver)라고 합니다.
또, User mode 즉 Application 영역에서 Kernel mode로 접근하는 추상화된 interface가 있는데, 컴퓨터에서 이 interface는 파일형태로 제공합니다.
(여기서 말하고 있는 파일은 Device파일을 의미합니다.)
그리고 이 파일형태로 제공되는 interface에 접근을 허용할지 말지에 대한 권한은 OS가 제어합니다.
(그래서 운영체제가 접근 통제를 제어한다고 생각하면 됩니다.)
그리고 하드웨어를 소프트웨어화 할 수 있는데, 이를 virtualization, 가상화라고 합니다.
2-12. 가상 메모리
페이징 파일은 Windows에서 RAM처럼 사용하는 하드디스크의 영역입니다.
운영체제에서 프로그램이 하나 실행 되면 프로세스한테 공간을 부여하는데, 이 부여된 (메모리)공간을 VMS(Virtual Memory Space)입니다.
Page-out(=Swap-out)
페이지 아웃이란, Ram에서 쓰던 페이지가 2차 메모리로 옮겨지는 현상입니다.
Page-in(=Swap-in)
페이지 아웃과 반대로 2차 메모리에서 사용되던 Page가 다시 RAM으로 돌아오는 현상입니다.
프로세스가 쓰고 있는 공간이 RAM일지, HDD와 같은 External Storage인지는 따라가서 확인해봐야합니다.
프로세스 A와 B가 있을 때, 운영체제에 의해서 A가 쓸 공간, B가 쓸 공간을 부여받습니다.
공간을 부여받고 각 페이지마다 RAM 혹은 디스크에 운영체제가 매핑해줍니다.
이렇게 되면 A, B 프로세스가 서로 침범할 일이 없습니다.
그런데 만약 A 프로세스가 메모리를 많이 쓰고 있었고, 램이 대부분 찬 상태에서 B 프로그램을 실행하려고 할 때, 램에 있는 안 쓰는 페이지를 2차메모리(ex: HDD)에 옮깁니다.(페이지 아웃)
이 때 운영체제는 프로세스들을 멈추게 되고, HDD에 쓰기가 발생합니다.
그리고 또 A를 사용하려고 할 때, 디스크에 쓰기가 마아아~악 일어납니다.
역시 페이지 아웃이 또 발생합니다.
가상 메모리의 장점은 공간이 확보되고, 작동도 되고, 각자의 영역이 보호되지만, 부족한 공간을 하나의 메모리로 쓰다보니 프로그램이 작동은 되지만서도 매우 느리다는 단점이 있습니다.
만약에 이렇게 하다가 프로그램이 죽어버리면, OS가 죽은 프로그램에 부여한 메모리 공간을 회수하게 됩니다. 회수하고 죽은 프로그램은 유저모드에서 제거됩니다.
그리고 회수된 메모리 공간은 다시 쓸 수 있게 됩니다.
정리해보자면,
가상 메모리 시스템을 사용하는 이유는
- 각 프로세스 공간을 완벽하게 분리하고 통제할 수 있습니다.
- 프로세스 오류가 운영체제에 까지 영향을 주지 못하도록 차단할 수 있습니다.
- 메모리가 부족해도 여러 프로그램들이 작동하는 등 자원을 효율적으로 활용할 수 있습니다.
2-13. 고급어와 저급어
- 고급어와 저급어는 High level과 Low level의 직역입니다.
- 저급어는 기계어(Machine code)입니다.
- 기계어는 알아보기 매우 어렵고 고급어는 인간이 이해하기 쉬운 언어입니다.
- 고급어의 코드는 보통 함수 단위로 묶어 표시합니다.
- 고급어를 기계어로 바꾸는 것이 번역입니다.
- 언어가 번역되어야 CPU가 읽어서 프로그램이 실행될 수 있습니다.
- High level언어를 Low level언어로 번역하는 과정을 컴파일(Compile)이라고 하고, 컴파일을 해주는 것이 컴파일러(Compiler)입니다.
2-14. 인터프리터(Interpreter)
- 고급어 소스코드를 직접 실행하는 프로그램이나 환경을 의미합니다.
- 보통 한 번에 한 줄 단위로 실행됩니다.
- 성능(특히 속도)면에서 컴파일러 방식보다 느립니다.
- 하지만 유연성은 월등합니다.
- JavaScript나 Python등이 여기에 해당합니다.
2-15. API와 SDK
- API는 Application Programming Interface입니다.
- 여기서의 Interface는 코드 묶음 단위를 가리키는 함수를 의미합니다.
- Software Development Kit
- 함수와 함수세트를 의미합니다.
- 공구(API)와 (가정용)공구세트(SDK)로 비유할 수 있습니다.
2-16. 자료구조와 알고리즘
자료구조는 일정규칙으로 자료를 나열(혹은 정리)하는 것이고,
알고리즘은 구조화된 자료에서 원하는 것을 빨리 찾아내는 방법입니다.
선형 구조(1차원)
선형 구조로는 Stack과 Queue가 있습니다.
Stack
- Last In First Out 구조(후입선출)입니다.
- 처음 넣은 것은 맨 아래 바닥에 깔립니다.
- 두 번째부터는 처음 넣은 것 위에 쌓입니다.
- 바닥에 있는 것을 꺼내려면 위에 쌓인 것들을 모두 치울 수 밖에 없습니다.
- Stack은 순서 뒤집기 혹은 되돌아가기(ctrl + z)에 많이 사용됩니다.
Queue
- First In First Out(선입선출) 구조입니다.
- 버스를 타기 위해 줄을 서는 것과 같습니다.
- 은행에서도 비슷한 경험을 할 수 있습니다.
- Enqueue는 Queue에 무언가가 들어가는 것입니다.
- Dequeue는 Queue에 무언가가 빠져나가는 것입니다.
비선형 구조(2차원)
비선형 자료구조의 대표적으로 Tree가 있습니다.
2진 트리
- 자료당 두 개의 위치정보(링크)를 이용해 셋을 하나 묶습니다.
- 맨 꼭대기를 기준으로 왼쪽에는 작은 숫자, 오른쪽에는 큰 숫자 카드가 있다고 가정합니다.
선형 구조와 비선형 구조 중 2차원 구조인 비선형 구조의 성능이 더욱 좋습니다.
대신 비선형 구조는 선형 구조에 의해서 구조가 많이 복잡합니다.
그래서 성능을 중요시하는 Database는 비선형 자료구조인 트리 구조로 정보를 보관해서 관리합니다.
3. 요약
강의 주제처럼 겁나게 넓게, 겁나게 얇게 컴퓨터라는 기계에 대해서 전반적으로 알아보았습니다.
H/W에서부터 운영체제까지의 컴퓨터 그리고 프로그래밍에 대해 전반적으로 알아보았습니다.
그리고 프로그래밍에 대해서 프로그래밍은 글쓰기다라는 강조를 많이 해주셨습니다.
그리고, 고급어 저급어, API, SDK, 자료구조, 알고리즘 등등 정말 넓고, 얇게 배웠습니다.
이번에 해당 강의를 들으면서, 전가산기, 16비트 체계 등 평소에 넘겨짚었던 내용들을 이해하게 되었습니다.
그리고 단어에 대해서도 얻은 내용과 지식들이 많네요...ㅎㅎ;;
저는 그럼 이후에 다른 강의 포스팅을 가지고 오겠습니다.
※ 참고로 이 포스팅은 순전히 저를 위한 정리입니다.
'CS > 컴퓨터 구조' 카테고리의 다른 글
| 전가산기 (0) | 2023.09.22 |
|---|---|
| 16비트 체계에 대하여 (0) | 2023.09.22 |
| 2의 보수법 (0) | 2023.05.05 |