
쌩로그
실전! 스프링 부트와 JPA 활용 1편 본문
목록
- 포스팅 개요
- 본론
2-1. 생각 정리
2-2. 개념 정리
2-3. 이후에 어떻게 뭘 해볼지 - 요약
1. 포스팅 개요
인프런에서 영한님의 실전! 스프링 부트와 JPA 활용 1편과 책 내용을 보고 생각 정리와 개념 정리, 그리고 이후에 어떻게 뭘 해볼지에 대한 내용을 기록 한 포스팅이다.
| 참고 책 내용과 강의내용의 차이점은 다음과 같다.
책 : 스프링 + Maven + JSP + JUnit4
강의 : 스프링 부트 2.1 + gradle + Thymeleaf + JUnit4
(번외로 나는 : 스프링 부트 3.x + gradle + Thymeleaf + JUnit5)
2. 본론
2-1. 생각 정리
먼저 여기서는 생각 정리도 생각 정리지만, 강의 중에 봤던 노하우와 팁, 그리고 내가 의문점을 가졌던 것, 강의 중에 만났던 오류들 다 이 부제에서 풀것이다.
오류들은 개념때문에 발생한 것들이 아니었기 때문이다.
Setter에 대해서
뭐 여러 얘기들을 찾다가 커뮤니티마다 올라오는 글을 한 번씩 보는데,
(커뮤니티에서도 다양한 사람들의 질문과 답을 볼 수 있어서 좋았다. 물론 오류가 발생해야 들여다보는데....여튼.. 그렇다...)
영한님이 Setter에 대해서 강박관념을 가질 필요는 없다는 얘기를 하셨다. 물론 강의 후반에서 본인은 Setter를 다 닫아놓는다고 했지만..
내가 여기에서 느낀 것은 뭔가 이유없이 "이렇다고 하니깐 이렇게 해야 한다"라기보단 "그럼에도 불구하고 난 필요할 거 같다."고 생각하면 쓰는 것이다.
Setter뿐만 아니라, 다른 것들도 마찬가지라고 생각한다.(지금 이렇게 글을 쓰면서도 막상 가면 그냥 "아 이걸 어떻게 xxx를 안 쓰고 하지..?"라고 생각할 것 같긴한데.. ㅋㅋㅋ)
막연한 이유없이 그냥 "이렇게 하래! 그래서 이렇게 해야 해!" 라기보단, "음.. 나는 지금 이게 베스트일 거 같은데...?"라고 생각되면 사용하면 된다는 것..
참고로 Setter 없이 데이터 변경 할 수 있다.
그리고 Setter 메서드 코드 자체가 그냥 필드에 냅다 직접 접근해서 변경한다.
그래서 데이터 변경이 이뤄져야 할 경우에는 의미있는 메서드 이름을 사용해서 그 메서드 내부에서 데이터 변경이 이루어지도록 하면 된다.
도메인 모델 패턴 , 트랜잭션 스크립트 패턴
도메인 모델 패턴
엔티티가 비즈니스 로직을 가지고 객체지향의 특성을 적극 활용하는 것
트랜잭션 스크립트 패턴
엔티티에는 비즈니스 로직이 없고 서비스 계층에서 대부부의 비즈니스 로직을 처리하는 것
강의 중간에서 보면 도메인 모델 패턴을 자주 사용하였다.
즉 비즈니스 로직이 서비스 계층에 있는 것이 아니라, 엔티티에 있는 것이다.
나는 비즈니스 로직은 무조건 서비스에 있어야 한다고 막연하게 생각해왔는데, 엔티티에 비즈니스 로직을 넣어둔다고는 생각을 못 했던 거 같다..
그리고 전부 해왔던 프로젝트가 따져보자면 트랜잭션 스크립트 패턴이다.
그러나 무조건 엔티티에 비즈니스 로직을 넣는 것은 아니다.
그 엔티티와 관련된 로직만 해당 엔티티에 비즈니스로직을 작성하는 것이다.
이렇게 함에 따라서 결합도는 낮아지고, 응집도는 커진다고 했다.(이게 객체지향이다...)
개념 정리가 더 가까운 거 같지만, 아무튼.. 도메인 모델 패턴도 적극 활용 해보려고 한다.
컨트롤러에서 어설프게 엔티티 생성하지 않기
흠.. 부트캠프 프로젝트에서 DTO로 들어온 데이터를 컨트롤러 계층에서 엔티티로 만들어서 서비스 계층으로 넘겼었다.
지금 생각해보니 이건 그닥 좋지 않았던 거 같다.
트랜잭션이 있는 상태에서 만들었어야 했는데, 트랜잭션이 없는 외부에서 엔티티 객체를 만들어서 서비스로 넘겼었고, 치명적인 것은 엔티티의 데이터를 그대로 반환했다.
최근 프로젝트는 DTO를 서비스로 넘겨서 넘겨진 DTO로 엔티티를 생성하고, 응답 데이터도 엔티티 그래도 반환하지 않고 데이터를 가공해서 반환하거나 하는 식으로 적용했다만,
트랜잭션을 생각지 못하고 우연에 의해서 적용된 것 같다...
그리고 트랜잭션 밖에서 조회하는 엔티티는 JPA와 관련 없는 엔티티이다.
엔티티 관련된 것은 트랜잭션 안에서 이루어지도록 해야 한다는 것을 명심해야겠다.
2-2. 개념 정리
모호했던 개념 정리를 여기서 다 풀것이다.
id에 Long과 long
이 내용은 오류를 마주치고, 해결할 방법을 찾으면서 봤던 글이다.
처음엔 Null값이냐 자바의 long의 기본형은 0이기때문에 Null처리가 안 된다는 것도 보고 "아~ 그냥 래퍼클래스 사용하면 되구나~"하고 무심코 넘겼었다. 이 글을 보면서 같은 맥락이지만, 이 글을 보고 "id를 long타입으로 선언하면 객체 생성시 id는 인스턴스 변수라서 기본 값으로 0으로 들어가는 이유도 있구나"라고 한번 더 상기하게 되었다.
사실 자바의 객체 기초 개념이지만, 연계해서 생각하지 못했던 것 같다.
그리고 지금 생각해보니 "객체 생성시 id를 제외하고, 값들을 채워넣는 생성자를 사용하면 되지않을까?"라고 생각하던 찰나에
그럼에도 불구하고, 인스턴스 변수라서 기본 값인 0으로 들어가버리는 참사가 벌어진다.
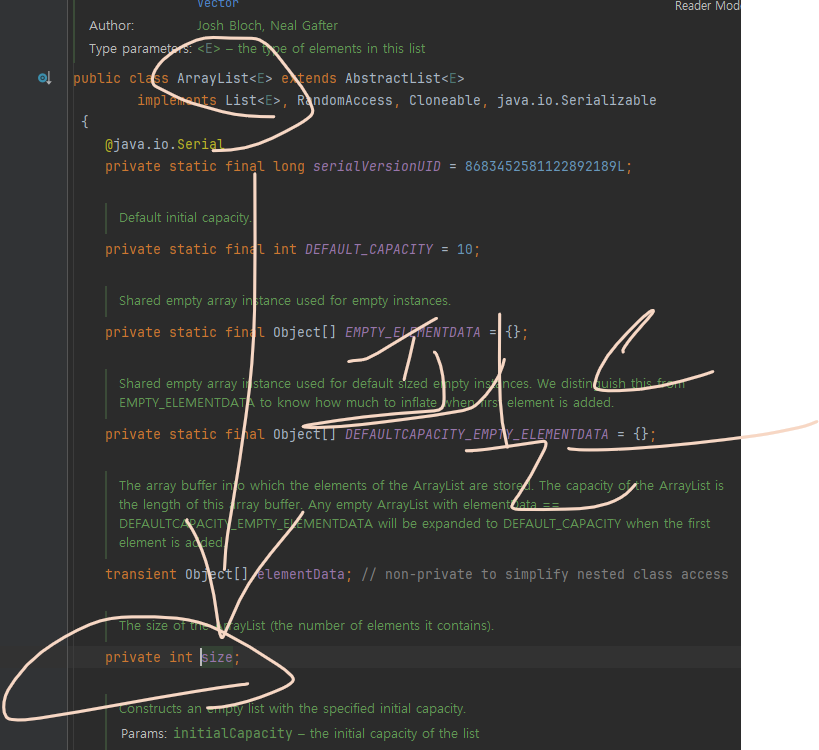
List의 size는 O(1)
누군가 size가 O(n)이 아니냐는 질문을 했고, 공식 서포터즈의 어떤 분이 답을 달아주었는데, size는 List의 필드 값이기 때문에 O(1)이라고 했다.
("지엽적인 거 같지만 이래서 자바도 딥하면 좋구나.."라고 생각하게 되었다.)
@Valid
다음과 같은 코드가 있다.
@PostMapping("/members/new")
public String create(@Valid MemberForm form, BindingResult result) {
if(result.hasErrors()) {
return "members/createMemberForm";
}MemberForm은 다음과 같다.
@Getter @Setter
public class MemberForm {
@NotEmpty(message = "회원 이름은 필수입니다.")
private String name;
private String city;
private String street;
private String zipcode;
}
이처럼 @Valid를 통해서 스프링이 "jakarta(javax)의 validation 기능을 사용하는구나"를 인지하고 memberForm에 있는 validation 기능을 적용해준다.
@Transactional
이 애너테이션이 트랜잭션 처리란 것을 알았지만 애매하게 알고 있었고 이번에 조금 더 명확하게 알게되었다.
강의 중에는 다음과 같이 정리했다.
// 메서드가 끝나는 시점에 스프링의 Transactional에 의해서 commit이 일어남. 변경감지에 의해서 flush가 일어남.책에서는 다음과 같이 정리되어있다.
: 스프링 프레임워크는 이 어노테이션이 붙어 있는 클래스나 메소드에 트랜잭션을 적용한다. 외부에서 이 클래스의 메소드를 호출할 때 트랜잭션을 시작하고 메소드를 종료할 때 트랜잭션을 커밋한다. 만약 예외가 발생하면 트랜잭션을 롤백한다.
라고 되어있다.
즉, 메서드를 호출할 때 트랜잭션이 시작되고, 메서드가 끝나면 커밋한다. 중간에 예외가 터지면 롤백한다.
그리고 보통 서비스 계층에서는 조회하는 메서드가 많은데, 이 때는 클래스레벨에 readOnly = true 속성을 가진 @Transactional을 선언하고 데이터의 생성, 변경이 일어나는 메서드마다 @Transactional을 붙이면 된다.
참고로 클래스 레벨에 붙였는데, 메서드에 붙이면 우선순위에 문제가 있을 거라고 생각할 수 있지만, 메서드에 붙어있으면 메서드에 있는 @Transactional이 우선된다.
그리고 readOnly = true를 하면 스프링이 조회하는 경우에 대해서 읽기에 최적화를 해준다고 한다.
또한 @Transactional은 RuntimeException과 그 자식들인 언체크(Unchecked) 예외만 롤백한다. 체크 예외가 발생해도 롤백하고 싶다면 @Transactional(robackFor = Exception.class)처럼 롤백할 예외를 지정해야 한다.
언체크/체크 예외는 자바의 정석 8장에 잘 나와있다.
테스트 코드에서의 @Transactional
테스트 코드에서 @Transactional은 기본이 롤백처리다.
그래서 클래스 레벨에 선언해두면 된다.
만약 롤백 처리를 비활성화하려면 테스트 메서드마다 @Rollback(false) 어노테이션을 선언하므로 비활성화시킬 수 있다.
그런데 이렇게 하면 JPA에서 Insert 쿼리를 볼 수 없다.
만약에 보고 싶다면 다음과 같이 쿼리가 나가도록 강제하면 된다.
그럼 @Rollback(false)처리없이 insert 쿼리가 나가는 것을 확인하고 롤백시킬 수 있다.(물론 클래스 레벨에 @Transactional이 있어야 한다.)
em.flush();테스트 코드에서의 application.yml
테스트 코드에도 다음과 같이 yml을 생성해놓을 수 있다.
TMI로 예전에 Test에 yml을 독립적으로 적용하지 못해서 메인 코드의 yml을 가지고 지지고 볶고 하다가 결국 못 하고 숙제로 그냥 남겨뒀던 것이 있었는데, 이번에 살짝 풀렸다.
테스트의 yml은 다음과 같다.
spring:
logging.level:
org.hibernate.SQL: debug적용한 것만 보면 이와 같다는 것이다.
사실은 다음과 같다.
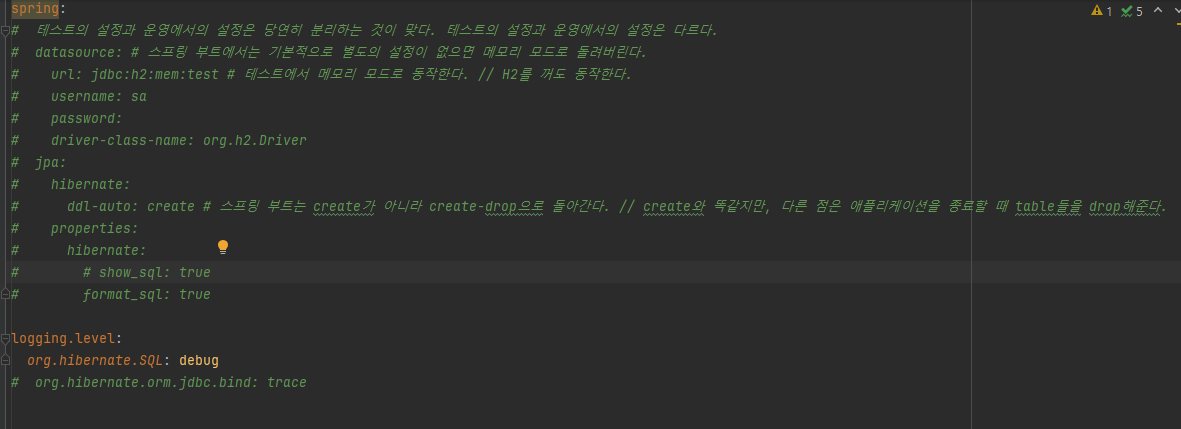
주석에 나와있지만, 내용은 다음과 같다.
- 테스트의 설정과 운영에서의 설정은 당연히 분리하는 것이 맞다. 테스트의 설정과 운영에서의 설정은 다르다. 따라서 테스트에 yml을 따로 분리하여 설정해주면 된다.
- 스프링 부트에서는 기본적으로 별도의 설정이 없으면 DB에 대해서 내장 메모리 모드로 돌려버린다. 즉 DB에 대해 테스트 환경에서 메모리 모드로 동작한다는 의미다. 이는 H2를 꺼도 동작한다.
H2가 꺼져있다.
하지만 테스트는 통과한다.
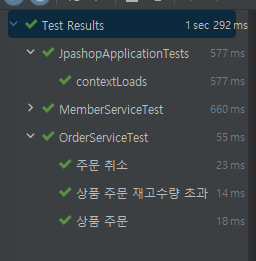
- 스프링 부트는 ddl-auto 옵션에 대해서 기본적으로 create가 아니라 create-drop으로 돌아간다. 이는 애플리케이션을 실행할 때 엔티티 클래스에 따라 테이블들을 생성하고, 애플리케이션 종료시에 테이블을 DROP한다. create는 종료해도 테이블을 DROP하지 않는다.
@PersistenceContext와 @PersistenceUnit
@PersistenceContext
엔티티 매니저 팩토리에서 엔티티 매니저를 직접 생성해서 사용하는 것이 아니라 컨테이너가 제공하는 엔티티 매니저를 사용한다.
컨테이너가 관리하는 엔티티 매니저를 주입하는 어노테이션이다.
@PersistenceUnit
@PersistenceContext를 사용해서 컨테이너가 관리하는 엔티티 매니저를 주입받을 수 있어서 엔티티 매니저 팩토리를 직접 사용할 일은 거의 없겠지만, 엔티티 매니저 팩토리를 주입받으려면 해당 어노테이션을 사용하면 된다.
사실 그냥 Repository 클래스에서
@RequiredArgsConstructor 와 동시에
private final EntityManager em;이 코드 사용하면 된다.
(그냥 저런 어노테이션이 있다는 것을 기록하고 싶었다.)
준영속
준영속에 대해서 여기에서는 단순히 영속성 컨텍스트에서 저장되었다가 분리된 상태라고 했는데,
다음과 같은 경우도 준영속 상태의 객체라고 볼 수 있다.
- 객체는 new로 생성된 새로운 객체인데 id가 세팅이 되어있는 객체
- 이는 DB에 한번 들어갔다 나왔다는 의미다.
- 데이터베이스에 갔다 온 상태로 식별자가 정확하게 데이터베이스에 있으면 준영속 상태의 객체라고 한다.
- JPA가 식별할 수 있는 아이디를 가지고 있고, 실제로 데이터베이스에 저장되었다가 왔기 때문에 해당 객체는 이 식별자를 기반으로 JPA가 관리를 했었다. 그리고 더 이상 영속성 컨텍스트가 관리하지 않는 엔티티이기 때문이다.
- id를 기반으로 생각을 해보면 new로 생성을 하긴 했지만 이미 JPA에서 DB로 한번 저장되고 불러온 것이다.
- 따라서 이 객체는 준영속 엔티티라고 볼 수 있다.
- 또한 해당 객체는 이미 한번 DB에 저장이 되어서 식별자가 존재한다
결론은 임의로 만들어낸 엔티티라도 기존의 식별자를 가지고 있으면 준영속 엔티티로 볼 수 있다.
Dirty Checking VS merge
바로 위의 준영속 개념과 이어지는 내용인데 엔티티의 저장이나 변경에 대한 내용이다.
변경에 더 가까운 내용이다.
merge()와 Dirty Checking은 뭘까
merge()
merge()는 준영속 상태의 엔티티를 영속성 컨텍스트에서 관리하게 하는 것이다.
JPA는 엔티티를 식별자로 구분하는데,
새로 생성된 객체이지만, 기존의 데이터의 id를 주입받아 준영속 상태가 된 객체를 영속성 컨텍스트에 관리하고, 그 값을 모두 update 시키는 것이다.
Dirty Checking
하지만 Dirty Checking은 영속성 컨텍스트에서 엔티티의 데이터가 변경했는지를 감지하고 변경된 데이터를 update 시키는 것이다.
결론적으로는 Dirty Checking을 사용하면 된다.
다음 코드를 보자.
@Repository
@RequiredArgsConstructor
public class ItemRepository {
private final EntityManager em;
public void save(Item item) {
if(item.getId() == null) {
em.persist(item);
} else {
Item merge = em.merge(item);
}
}
이 코드를 보면 id가 있냐 없냐에 따라 em.persist()를 호출할지 em.merge()를 호출할지 나와있다.
즉 id가 있으면 이미 DB에 저장되어있는 객체란 것이다.
지금은 이렇게 merge()를 사용하고 있다.
그리고 Item merge = em.merge(item); 이 코드를 보자.
// 매개변수의 item은 영속성 컨텍스트에서 관리되지 않고, 그 반환된 merge는 영속성 컨텍스트에서 관리된다.
// 변경감지 기능은 원하는 속성만 변경가능하지만, 병합(merge)의 주의점은 모든 속성이 변경된다.
// 병합시 값이 없으면 null로 update가 일어난다.
그냥 Dirty Checking하라는 것이다.
그리고 Hibernate에서도 Dirty Checking이 best practice라고 한다.
물론 간단한 데이터 변경은 merge()를 사용해도 되지만,Dirty Checking이 더욱 안전한 방법이다.
2-3. 이후에 어떻게 뭘 해볼지
일단 나는 원숭이 중의 원숭이였다.
조금은 나아졌던 게 아닐까 하고 있었지만, 개뿔이었다...
하지만 그만큼 또 채워진 것에 감사하다.
이후 나는 위에 정리했던 생각과 개념을 6월에 진행했던 여행 커뮤니티 서비스 프로젝트와 이번 해 2월에 부트캠프 때 진행했던 책 공유 커뮤니티 서비스의 코드들에 적용해 볼 것이다.
(내가 적용해볼 프로젝트가 2개가 있다는 것 또한 나름 감사한 환경인 것 같다.)
결론 : 위에 사항들과 이전 프로젝트 코드를 리팩터링하면서 적용할 것이다.
위에서 다 말한 것이지만, 다음 내용들을 주의하면서 리패터링 해볼것이다.
// 원더허브 나 북빌리지 도메인 패턴 적용하기
// Transactional 바꾸기
// 조금 더 객체지향적으로..
// Cacade 확인 한 번 더하기
// Entity 생성자 protected로 , AllArguments 빼기
// API 반환 시엔 이유를 불문하고, 엔티티를 반환하지 않기 : SSR이야 서버의 데이터를 렌더링하지만,, (그럼에도 불구하고, DTO 넘기기)
// 준영속 엔티티 수정
// 영속성 컨텍스트에 의해서 관리되는지 고민해보고, 더티체킹에 의해서 update가 알아서 나가도록 수정
// 컨트롤러에서 어설프게 엔티티 생성하지 않기
// 트랜잭션이 있는 서비스 계층에 식별자 id와 변경할 데이터를 명확하게 전달
// 트랜잭션이 있는 서비스 계층에서 영속 상태의 엔티티를 조회하고, 엔티티의 데이터를 직접 변경하기.
// 그럼 커밋시점에 변경된다.
// 트랜잭션 밖에서 조회하는 엔티티는 JPA와 관련 없는 엔티티이다.
// 생성자 접근 레벨 protected로3. 요약
JPA 활용 1편을 들으면서 들었던 생각, 개념, 적용에 대한 얘기였다.
추후에 리팩터링 과정도 포스팅하겠다. (물론 공부 좀 더하고 ^^)
'Spring > JPA' 카테고리의 다른 글
| JPA로 Entity ID에 UUID 타입 사용하기(with. MySQL 8.x) (4) | 2024.01.24 |
|---|---|
| 실전! 스프링 부트와 JPA 활용 2편 (0) | 2024.01.14 |
| Jpa기본 10. 객체지향 쿼리 언어(인프런 + 자바 ORM 표준 JPA 프로그래밍) (0) | 2023.12.13 |
| Jpa기본 09. 값 타입(인프런 + 자바 ORM 표준 JPA 프로그래밍) (0) | 2023.12.03 |
| Jpa기본 08. 프록시와 연관관계 관리(인프런 + 자바 ORM 표준 JPA 프로그래밍) (2) | 2023.12.01 |