
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- java
- 자바
- 스레드
- Docker
- 자료구조
- SQL
- 실전 자바 고급 1편
- 도커 엔진
- 쿠버네티스
- lambda
- container
- 알고리즘
- 함수형 인터페이스
- 인프런
- mysql
- 시작하세요 도커 & 쿠버네티스
- 람다
- 김영한
- 도커
- Java IO
- Thread
- 동시성
- db
- 쓰레드
- RDB
- 자바 입출력 스트림
- 데이터베이스
- 컨테이너
- 멀티 쓰레드
- Kubernetes
- Today
- Total
쌩로그
Jpa기본 10. 객체지향 쿼리 언어(인프런 + 자바 ORM 표준 JPA 프로그래밍) 본문
포스팅 개요
- 포스팅 개요
- 본론
2-1. 객체지향 쿼리 소개
2-2. JPQL
2-3. 객체지향 쿼리 심화(일부) - 요약
1. 포스팅 개요
스압에 주의하시고 , 필요한 키워드를 검색해서 보시는 걸 추천합니다.
해당 포스팅은 인프런에서 영한님의 JPA기본 강의에서 JPQL 파트와 해당 파트에 맞는 책의 챕터를 보고 학습한 내용을 요약 및 정리하는 포스팅입니다.
참고로 강의로는 Section 2개가 걸쳐이어지는 내용지만, 책으로는 1챕터로 구성되어있습니다.
본론에 3개의 부제가 있지만, 책에서는 Criteria, QueryDSL, 네이티브 SQL 등 3개의 부제가 더 있습니다.
3개 Section을 제외한 이유는 다음과 같습니다.
- Criteria는 강의 중 소개할 때만 잠깐 보여주고 넘어가서 제외했습니다. QueryDSL이라는 더 좋은 라이브러리가 있기에 제외했습니다.
- QueryDSL은 강의 중 언급만 했습니다. 즉 다루지 않았습니다. 그래서 제외했습니다. QueryDSL은 추후 강의를 수강하며 정리하도록 하겠습니다.
- 네이티브 SQL도 강의에 소개만하고 넘어갔기에 제외했습니다.
그리고 JPA 기본편은 해당 포스팅이 끝입니다.
(최근 경어체를 생략 중인데, JPA 기본편 시리즈 10개 중 이미 9개가 경어체다보니 해당 포스팅까지만, 경어체를 사용하도록 합니다 ^^. 추후 제 기분에 따라 경어체를 다시 사용할 수도, 아닐 수도 있습니다.)
2. 본론
이 장에서 다루는 내용은 다음과 같습니다.
- 객체지향 쿼리 소개
- JPQL
- 객체지향 쿼리 심화
JPA는 복잡한 검색 조건을 사용해서 엔티티 객체를 조회할 수 있는 다양한 쿼리 기술을 지원합니다.
JPQL은 가장 중요한 객체지향 쿼리 언어입니다.
Criteria나 QueryDSL은 결국 JPQL을 편리하게 사용하도록 도와주는 기술이므로 JPA를 다루는 개발자라면 JPQL을 필수로 학습해야 합니다.
그럼 객체지향 쿼리가 무엇인지 본격적으로 보겠습니다.
2-1. 객체지향 쿼리 소개
EntityManager.find()메소드를 사용하면 식별자로 엔티티 하나를 조회할 수 있습니다.
이렇게 조회한 엔티티에 객체 그래프 탐색을 사용하면 연관된 엔티티들을 찾을 수 있습니다.
이 둘은 가장 단순한 검색 방법입니다.
- 식별자로 조회 : EntityManager.find()
- 객체 그래프 탐색(예 : a.getB().agetC())
이 기능만으로 애플리케이션을 개발하기는 어렵습니다.
예를 들어 나이가 30살 이상 회원을 모두 검색하고 싶다면 더 현실적이고 복잡한 검색 방법이 필요합니다.
그렇다고 모든 회원 엔티티를 메모리에 올려두고 애플리케이션에서 30살 이상인 회원을 검색하는 것도 현실성이 업습니다.
결국 데이터는 데이터베이스에 있으므로 SQL로 필요한 내용을 최대한 걸러서 조회해야 합니다.
하지만 ORM을 사용하면 데이터베이스 테이블이 아닌 엔티티 객체를 대상으로 개발하므로 검색도 테이블이 아닌 엔티티 객체를 대상으로 하는 방법이 필요합니다.
JPQL은 이런 문제를 해결하기 위해 만들어졌는데 다음과 같은 특징이 있습니다.
- 테이블이 아닌 객체를 대상으로 검색하는 객체지향 쿼리입니다.
- SQL을 추상화해서 특정 데이터베이스 SQL에 의존하지 않습니다.
SQL이 데이터베이스 테이블을 대상으로 하는 데이터 중심의 쿼리라면 JPQL은 엔티티 객체를 대상으로 하는 객체지향 쿼리입니다.
JPQL을 사용하면 JPA는 이 JPQL을 분석한 다음 적절한 SQL을 만들어 데이터베이스를 조회합니다.
그리고 조회한 결과로 엔티티 객체를 생성해서 반환합니다.
JPQL을 한마믿로 정의하면 객체지향 SQL입니다.
처음 보면 SQL로 오해할 정도로 문법이 비슷합니다. 따라서 SQL에 익숙한 개발자는 몇 가지 차이점만 이해하면 쉽게 적용할 수 있습니다.
JPA는 JPQL뿐만 아니라 다양한 검색 방법을 제공합니다.
다음은 JPA가 공식 지원하는 기능입니다.
JPQL(Java Persistence Query Language)
Criteria 쿼리(Criteria Query) : JPQL을 편하게 작성하도록 도와주는 API, 빌더 클래스 모음
네이티브 SQL(Native SQL) : JPA에서 JPQL 대신 직접 SQL을 사용할 수 있습니다.
다음은 JPA가 공식 지원하는 기능은 아니지만 알아둘 가치가 있는 것입니다.
- QueryDSL : Criteria 쿼리처럼 JPQL을 편하게 작성하도록 도와주는 빌더 클래스 모음, 비표준 오픈소스 프레임워크입니다.
- JDBC 직접 사용, MyBatis 같은 SQL 매퍼 프레임워크 사용 : 필요하면 JDBC를 직접 사용할 수 있습니다.
가장 중요한 건 JPQL입니다.
Criteria나 QueryDSL은 JPQL을 편하게 작성하도록 도와주는 빌더 클래스일 뿐입니다.
따라서 JPQL을 이해해야 나머지도 이해할 수 있습니다.
JPQL 소개
JPQL(Java Persistence Query Language)은 엔티티 객체를 조회하는 객체지향 쿼리입니다.
문법은 SQL과 비슷하고 ANSI 표준 SQL이 제공하는 기능을 유사하게 지원합니다.
JPQL은 SQL을 추상화해서 특정 데이터베이스에 의존하지 않습니다. 그리고 데이터베이스 방언(Dialect)만 변경하면 JPQL을 수정하지 않아도 자연스럽게 데이터베이스를 변경할 수 있습니다.
예를 들어 같은 SQL 함수라도 데이터베이스마다 사용 문법이 다른 것이 있는데, JPQL이 제공하는 표준화된 함수를 사용하면 선택한 방언에 따라 해당 데이터베이스에 맞춘 적절한 SQL함수가 실행됩니다.
JPQL은 SQL보다 간결합니다.
회원 엔티티를 대상으로 JPQL을 사용하는 간단한 예제를 보겠습니다.
// Member
public class Member {
@Id @GeneratedValue
private Long id;
private String username;
//...
// Member 조회(main 메서드)
String query = "select m from Member as m where m.username = 'kim'";
List<Member> resultList = em.createQuery(query, Member.class)
.getResultList();위 예시 코드는 회원이름이 kim인 엔티티를 조회합니다.
JPQL에서 Member는 엔티티 이름입니다.
그리고 m.username은 테이블 컬럼명이 아니라 엔티티 객체의 필드명입니다.
em.creatQuery()메소드에 실행할 JPQL과 반환할 엔티티의 클래스 타입인 Member.class를 넘겨주고 getResultList() 메소드를 실행하면 JPA는 JPQL을 SQL로 변환해서 데이터베이스를 조회합니다. 그리고 조회한 결과로 Member 엔티티를 생성해서 반환합니다.
실행한 JPQL은 위의 query 에 담긴 것과 같으며 실제 실행된 SQL은 다음과 같습니다.
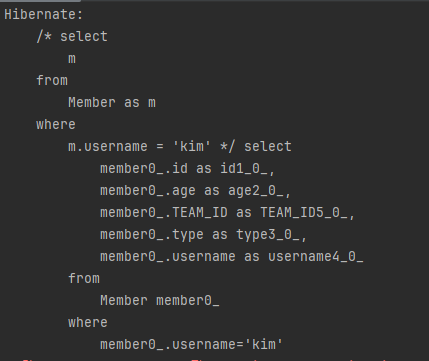
참고로 하이버네이트 구현체가 생성한 SQL은 별칭이 좀 복잡합니다.
Criteria 쿼리 소개
(포스팅에 제외된 부제라고 했지만, 강의 내용 중 해당되는 내용이므로 잠깐 보고 넘어갑니다.)
Criteria는 JPQL을 생성하는 빌더 클래스입니다.
Criteria의 장점은 문자가 아닌 query.select(m).where(...)처럼 프로그래밍 코드로 JPQL을 작성할 수 있다는 점이 있습니다.
예를 들어 JPQL에서 select m from Membeeee m처럼 오타가 있다고 햇을 때,
컴파일은 성공하고 애플리케이션을 서버에 배포할 수 있습니다.
문제는 해당 쿼리가 실행되는 런타임 시점에 오류가 발생한다는 점입니다.
이것이 문자기반 쿼리의 단점입니다.
반면에 Criteria는 문자가 아닌 코드로 JPQL을 작성합니다.
따라서 컴파일 시점에 오류를 발견할 수 있습니다.
문자로 작성한 JPQL보다 코드로 작성한 Criteria의 장점은 다음과 같습니다.
- 컴파일 시점에 오류를 발견할 수 있습니다.
- IDE를 사용하면 코드 자동완성을 지원합니다.
- 동적 쿼리를 작성하기 편합니다.
하이버네이트를 포함한 몇몇 ORM 프레임워크들은 이미 오래 전부터 자신만의 Criteria를 지원했습니다. JPA는 2.0부터 Criteria를 지원합니다.
간단하게 Criteria 사용 코드를 보도록 하겠습니다.
앞서 보앗던 JPQL을 Criteria로 작성해보겠습니다.
select m from Member as m where m.username = 'kim'
// Criteria 사용 준비
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Member> query = cb.createQuery(Member.class);
// 루트 클래스(조회를 시작할 클래스)
Root<Member> m = query.from(Member.class);
// 쿼리 생성
CriteriaQuery<Member> cq = query.select(m).where(cb.equal(m.get("username"), "kim"));
List<Member> resultList = em.createQuery(cq).getResultList();다음은 실행 SQL문입니다.
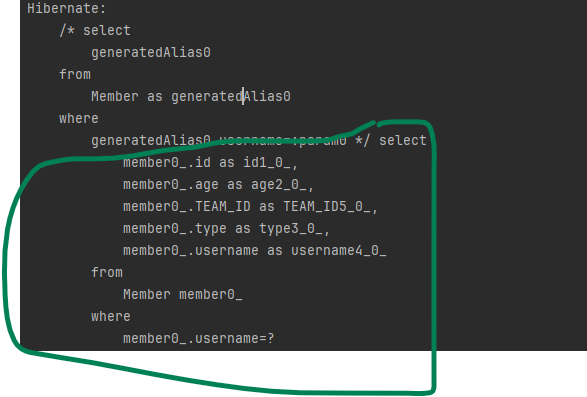
예시 코드를 보면 쿼리를 문자가 아닌 코드로 작성한 것을 확인할 수 있습니다.
아쉬운 점은 m.get("username")을 보면 필드 명을 문자로 작성했습니다.
만약 이 부분도 문자가 아닌 코드로 작성하고 싶으면 메타 모델(MetaModel)을 사용하면 됩니다.
메타 모델 API에 대해 알아보겠습니다. 자바가 제공하는 어노테이션 프로세서(Annotation Processor)기능을 사용하면 어노테이션을 분석해서 클래스를 생성할 수 있습니다. JPA는 이 기능을 사용해서 Member 엔티티 클래스로부터 Member_라는 Criteria 전용 클래스를 생성하는데 이것을 메타 모델이라고 합니다.
(어노테이션 프로세서 기능을 사용해서 메타 모델을 사용하는 자세한 방법은 있지만, 여기 포스팅에선 생략합니다. 책의 Criteria 챕터에 있습니다.)
메타 모델을 사용하면 온전히 코드만 사용해서 쿼리를 작성할 수 있습니다.
// 메타 모델 사용 전 -> 사용 후
m.get("username") -> m.get(Member_.username)이 코드를 보면 "username"이라는 문자에서 Member_.username이라는 코드로 변경된 것을 확인할 수 있습니다. 참고로 Criteria는 코드로 쿼리를 작성할 수 있어서 동적 쿼리를 작성할 때 유용합니다.
Criteria가 가진 장점이 많지만 모든 장점을 상쇄할 정도로 복잡하고 장황합니다. 따라서 사용하기 불편한 건 물론이고 Criteria로 작성한 코드도 한눈에 들어오지 않는다는 단점이 있습니다.
QueryDLS 소개
(Criteria와 마찬가지로 포스팅에 제외된 부제라고 했지만, 강의 내용 중 해당되는 내용이므로 잠깐 보고 넘어갑니다.)
QueryDSL도 Criteria처럼 JPQL 빌더 역할을 합니다.
QueryDSL의 장점은 코드 기반이면서 단순하고 사용하기 쉽습니다.
그리고 작성한 코드도 JPQL과 비슷해서 한눈에 들어옵니다.
QueryDSL과 Criteria를 비교하면 Criteria는 너무 복잡합니다.
참고
QueryDLS은 JPA 표준은 아니고 오픈소스 프로젝트입니다. 이것은 JPA뿐만 아니라 JDO, 몽고DB, Java Collection, Lucene, Hibernate Search도 거의 같은 문법으로 지원합니다. 현제 스프링 데이터 프로젝트가 지원할 정도로 많이 기대되는 프로젝트입니다. 영한님은 Criteria보다 QueryDSL을 선호한다고합니다.
(책이 쓰여질 당시의 이야기이니 참고만 해주세요^^)
QueryDSL로 작성한 코드를 살펴보겠습니다.
(실행 결과는 생략합니다. 세팅이 좀 빡세요..^^;;)
// 준비
JPAQuery query = new JPAQuery(em);
QMember member = QMember.member;
// 쿼리, 결과 조회
List<Member> members =
query.from(member)
.where(member.username.eq("kim"))
.list(member);QueryDSL을 사용하는 코드는 특별한 설명을 하지않더라도 코드만으로 대부분 이해가 될 것입니다.
QueryDSL도 어노테이션 프로세서를 사용해서 쿼리 전용 클래스를 만들어야 합니다.
QMember는 Member엔티티 클래스를 기반으로 생성한 QueryDSL 쿼리 전용 클래스입니다.
네이티브 SQL 소개
(앞서 소개한 두 내용과 마찬가지로 포스팅에 제외된 부제라고 했지만, 강의 내용 중 해당되는 내용이므로 잠깐 보고 넘어갑니다.)
JPA는 SQL을 직접 사용할 수 있는 기능을 지원하는데 이를 네이티브 SQL이라고 합니다.
JPQL을 사용해도 가끔은 특정 데이터베이스에 의존하는 기능을 사용해야 할 때가 있습니다. 예를 들어 오라클 데이터베이스만 사용하는 CONNECT BY 기능이나 특정 데이터베이스에서만 동작하는 SQL 힌트 같은 것입니다.
(참고로 하이버네이트는 SQL 힌트 기능을 지원합니다.)
이런 기능들은 전혀 표준화되어 있지 않으므로 JPQL에서 사용할 수 업습니다.
그리고 SQL은 지원하지만 JPQL이 지원하지 않는 기능도 있습니다.
이때는 네이티브 SQL을 사용하면 됩니다.
네이티느 SQL의 단점은 특정 데이터베이스에 의존하는 SQL을 작성해야 한다는 것입니다. 따라서 데이터베이스를 변경하면 네이티브 SQL도 수정해햐 합니다.
String sql = "SELECT ID, USERNAME, AGE, TEAM_ID FROM MEMBER WHERE USERNAME = 'kim'";
List<Member> resultList = em.createNativeQuery(sql, Member.class)
.getResultList();실행 결과는 다음과 같다.
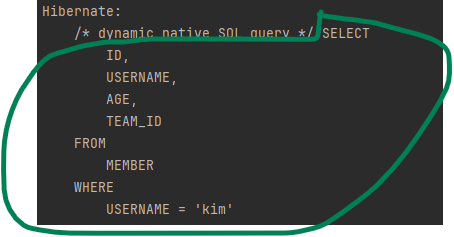
예시 코드를 보면, 네이티브 SQL은 em.createNativeQuery()를 사용하면 된다.
나머지 API는 JPQL과 같습니다.
실행하면 직접 작성한 SQL을 데이터베이스에 전달합니다.
JDB 직접 사용, 마이바이트 같은 SQL 매퍼 프레임워크 사용
이럴 일은 드물겠지만, JDBC 커넥션에 접근하고 싶으면 JPA는 JDBC 커넥션을 획득하는 API를 제공하지 않으므로 JPA 구현체가 제공하는 방법을 사용해야 합니다.
하이버네이트에서 직접 JDBC Connection을 획득하는 방법은 다음과 같습니다.
Session session = em.unwrap(Session.class);
session.doWork(new Work() {
@Override
public void execute(Connection connection) throws SQLException {
// work...
}
});먼저 JPA EntityManager에서 하이버네이트 Session을 구합니다.
그리고 Session의 doWork() 메소드를 호출하면 됩니다.
JDBC나 마이바티스를 JPA와 함께 사용하면 영속성 컨텍스트를 적절한 시점에 강제로 플러시해야 합니다.
JDBC를 직접 사용하든 마이바이트 같은 SQL 매퍼와 사용하든 모두 JPA를 우회해서 데이터베이스에 접근한다. 문제는 JPA를 우회하는 SQL에 대해서는 JPA가 전혀 인식하지 못한다는 점입니다. 최악의 시나리오는 영속성 컨텍스트와 데이터베이스를 불일치 상태로 만들어 데이터 무결성을 훼손할 수 있습니다.
예를 들어 같은 트랜잭션에서 영속성 컨텍스트에 있는 10,000원짜리 상품 A의 가격을 9,000원으로 변경하고 아직 플러시를 하지 않았는데 JPA를 우회해서 데이터 베이스에 직접 상품 A를 조회하면 상품 가격이 얼마일까요?
데이터베이스에 상품 가격은 10,000원이므로 10,000원이 조회됩니다.
이렇 이슈를 해결하는 방법은 JPA를 우회해서 SQL을 실행하기 직전에 영속성 컨텍스트를 수동으로 플러시해서 데이터베이스와 영속성 컨텍스트를 동히과하면 됩니다.
참고로 스프링 프레임워크를 사용하면 JPA와 마이바티스를 손쉽게 통합할 수 있습니다. 또한 스프링 프레임워크의 AOP를 적절히 활용해서 JPA를 우회하여 데이터베이스에 접근하는 메소드를 호출할 때마다 영속성 컨텍스트를 플러시하면서 위에서 언급한 문제도 깜끔하게 해결할 수 있습니다.
2-2. JPQL
방금 전 절에서 엔티티를 쿼리하는 다양한 방법을 소개했습니다.
어떤 방법을 시작하든 JPQL(Java Persistence Query Language)에서 모든 것이 시작됩니다. 이론은 소개 절에서 이미 설명 많이 했으므로 이제는 JPQL의 사용 방법 위주로 설명됩니다.
다시 한번 JPQL의 특징을 정리해보면 다음과 같습니다.
- JPQL은 객체지향 쿼리 언어입니다. 따라서 테이블을 대상으로 쿼리하는 것이 아니라 엔티티 객체를 대상으로 쿼리합니다.
- JPQL은 SQL을 추상화해서 특정 데이터베이스 SQL에 의존하지 않습니다.
- JPQL은 결국 SQL로 변환됩니다.
이번 절에서 예제로 사용할 도메인 모델을 보겠습니다.
샘플 모델 UML입니다.
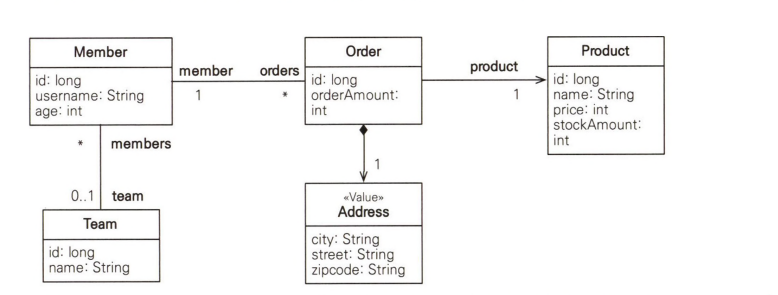
샘플 모델 ERD입니다.
실무에서 사용하는 주문 모델링은 더 복잡하지만 JPQL의 이해가 목적이므로 단순화한 것입니다.
회원 상품은 다대다 관계라는 것을 특히 주의해야합니다.
그리고 Address는 임베디드 타입인데 이는 값 타입이므로 UML에서 스테레오 타입을 사용해 <<Value>>로 정의했습니다.
ERD를 보면 ORDERS 테이블에 포함되어 있습니다.
기본 문법과 쿼리 API
JPQL도 SQL과 비슷하게 SELECT, UPDATE, DELETE 문을 사용할 수 있습니다.
참고로 엔티티를 저장할 때는 앞에서 봐왔던 것처럼 EntityManager.persist()를 사용하면 되기에 INSERT 문은 없습니다.
다음은 JPQL 문법입니다.
select_문 :: =
select_절
from_절
[where_절]
[groupby_절]
[having_절]
[orderby_절]
update_문 :: update_절 [where_절]
delete_문 :: delete_절 [where_절]위의 JPQL 문법을 보면 전체 구조는 SQL과 비슷한 것을 알 수 있습니다.
JPQL에서 UPDATE, DELETE 문은 벌크 연산이라 하는데, 2-3애서 확인할 수 있습니다.
이제 SELECT문을 살펴보겠습니다.
SELECT 문
SELECT 문은 다음과 같이 사용합니다.
SELECT m FROM Member as m where m.username = 'Hello'대소문자 구분
엔티티와 속성은 대소문자를 구분합니다.
예를 들어 Member, username은 대소문자를 구분합니다. 반면에 SELECT, FROM, AS와 같은 JPQL 키워드는 대소문자를 구분하지 않습니다.
엔티티 이름
JPQL에서 사용한 Member는 클래스 명이 아니라 엔티티 명입니다.
엔티티 명은 @Entity(name="XXX")로 지정할 수 있습니다.
엔티티 명을 지정하지 않으면 클래스명을 기본값으로 사용합니다.
기본값인 클래스 명을 엔티티 명으로 사용하는 것을 추천합니다.
별칭은 필수Member As m을 보면 Member에 m이라는 별칭을 주었습니다.
JPQL은 별칭을 필수로 사용해야 합니다. 따라서 다음 코드처럼 별칭 없이 작성하면 잘못된 문법이라는 오류가 발생합니다.
(바로 밑의 참고사항을 봐주세요.)
참고 1
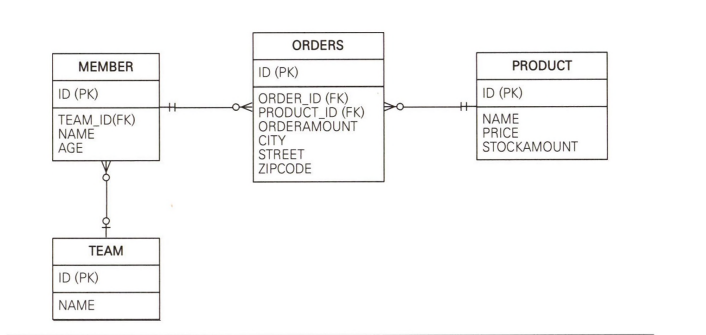
하이버네이트는 JPQL 표준도 지원하지만, 더 많은 기능을 가진 HQL(Hibernate Query Language)을 제공합니다. JPA 구현체로 하이버네이트를 사용하면 HQL도 사용할 수 있습니다. HQL은 SELECT username FROM Member m의 username처럼 별칭 없이 사용할 수 있습니다.
String query = "select username from Member m where username = :username";
List<String> resultList = em.createQuery(query, String.class)
.setParameter("username", "kim")
.getResultList();이 쿼리는 원래 오류가 나야하지만, Hibernate를 구현체로 사용하기 때문에, 오류가 나지 않고, 잘 실행됩니다.
아래는 결과입니다.
참고 2
JPA 표준 명세는 별칭을 식별 변수(Identification variable)라는 용어로 정의했습니다. 하지만 보통 별칭(alias)이라는 단어가 익숙하므로 별칭으로 부릅니다~
TypeQuery, Query
작성한 JPQL을 실행하려면 쿼리 객체를 만들어야 합니다. 쿼리 객체는 TypeQuery와 Query가 있는데, 반환할 타입을 명확하게 지정할 수 있으면 TypeQuery 객체를 사용하고, 반환 타입을 명확하게 지정할 수 없으면 Query 객체를 사용하면 됩니다.
TypeQuery를 사용하는 예시를 보겠습니다.
TypedQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class);
List<Member> resultList = query.getResultList();
for(Member member : resultList) {
System.out.println("member = " + member);
}em.creatQuery()의 두 번째 파라미터에 반환할 타입을 지정하면 TypeQuery를 반환하고, 지정하지 않으면 Query를 반환합니다.
조회 대상이 Member 엔티티이므로 조회 대상 타입이 명확하여 TypeQuery를 사용할 수 있습니다.
다음은 Query 사용 예시입니다.
Query query = em.createQuery("SELECT m.username, m.age FROM Member m");
List resultList = query.getResultList();
for(Object o : resultList) {
Object[] result = (Object[])o; // 결과가 둘 이상이면 Object[]반환
System.out.println("username = " + result[0]);
System.out.println("age = " + result[1]);
}위의 코드는 조회 대상이 String 타입인 회원 이름과 Integer 타입인 나이이므로 조회 대상 타입이 명확하지 않습니다.
이처럼 SELECT 절에서 여러 엔티티나 컬럼을 선택할 때는 반환할 타입이 명확하지 않으므로 Query 객체를 사용해야 합니다.
Query 객체는 SELECT 절의 조회 대상이 예시 코드처럼 둘 이상이면 Object[]를 반환하고 SELECT 절의 조회 대상이 하나면 Object를 반환합니다.
예를 들어 SELECT m.username, from Member m이면 결과를 Object로 반환하고 SELECT m.username, m.age from Member m이면 Object[]를 반환합니다.
두 코드를 비교해보면 타입을 변환할 필요가 없는 TypeQuery를 사용하는 것이 더 편리한 것을 알 수 있습니다.
결과 조회
다음 메소드들을 호출하면 실제 쿼리를 실행해서 데이터베이스를 조회합니다.
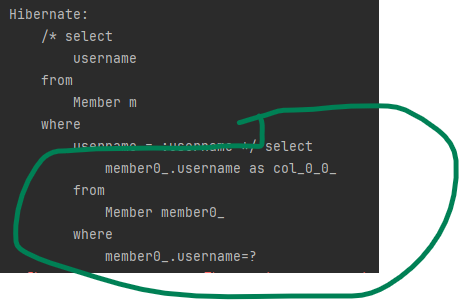
query.getResultList(): 결과를 컬렉션으로 반환합니다. 만약 결과가 없으면 빈 컬렉션을 반환합니다.query.getSingleResult(): 결과가 정확히 하나일 때 사용합니다.결과가 없으면
javax.persistence.NoResultException예외가 발생합니다.결과가 1개보다 많으면
javax.persistence.NonUniqueResultException예외가 발생합니다.Query query = em.createQuery("SELECT m.username, m.age FROM Member m"); Object singleResult = query.getSingleResult(); Object[] result = (Object[])singleResult; // 결과가 둘 이상이면 Object[]반환 System.out.println("username = " + result[0]); System.out.println("age = " + result[1]);다음은 위의 코드 실행결과입니다.
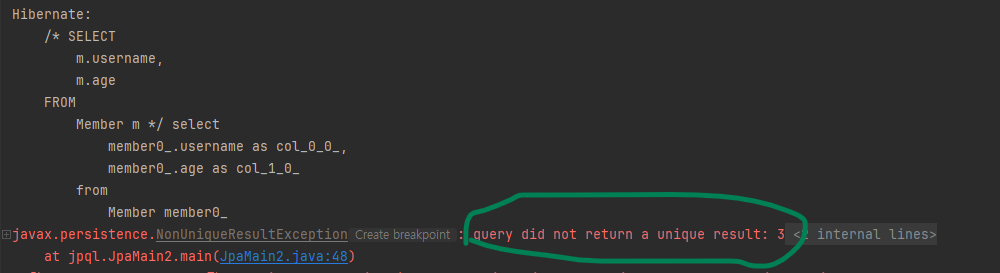
반환 값이 unique하지 않고, 3개가 있다는 의미입니다.
다음은 결과가 없을 때 실행결과입니다.

getSingleResult()는 결과가 정확히 1개가 아니면 예외가 발생한다는 점에 주의해야 합니다.
파라미터 바인딩
JDBC는 위치 기준 파라미터 바인딩만 지원하지만 JPQL은 이름 기준 파라미터 바인딩도 지원합니다.
이름 기준 파라미터
이름 기준 파라미터(Named parameters)는 파라미터를 이름으로 구분하는 방법입니다.
이름 기준 파라미터는 앞에 :를 사용합니다.
String usernameParam = "User1";
TypedQuery<Member> query = em.createQuery("select m from Member m where m.username = :username", Member.class);
query.setParameter("username", usernameParam);
List<Member> resultList = query.getResultList();위 코드의 JPQL을 보면 :username이라는 이름 기준 파라미터를 정의하고 query.setParameter()에서 username이라는 이름으로 파라미터를 바인딩합니다.

참고로 JPQL API는 대부분 메소드 체인 방식으로 설계되어 있어서 다음과 같이 연속해서 작성할 수 있습니다.
List<Member> members =
em.createQuery("SELECT m FROM Member m where m.username = :username", Member.class)
.setParameter("username", usernameParam)
.getResultList();위치 기준 파라미터
위치 기준 파라미터(Positional parameters)를 사용하려면 ? 다음 위치 값을 주면 됩니다. 위치 값은 1부터 시작합니다.
다음 예시를 보겠습니다.
String usernameParam = "회원1";
List<Member> members =
em.createQuery("SELECT m FROM Member m where m.username = ?1", Member.class)
.setParameter(1, usernameParam)
.getResultList();위치 기준 파라미터 방식보다는 이름 기준 파라미터 바인딩 방식을 사용하는 것이 더 명확합니다.
참고
JPQL을 수정해서 다음 코드처럼 파라미터 바인딩 방식을 사용하지 않고, 직접 문자를 더해 만들어 넣으면 악의적인 사용자에 의해 SQL 인젝션 공격을 당할 수 있습니다. 또한 성능 이슈도 있는데 파라미터 바인딩 방식을 사용하면 파라미터의 값이 달라도 같은 쿼리로 인식해서 JPA는 JPQL을 SQL로 파싱한 결과를 재사용할 수 있습니다. 그리고 데이터베이스도 내부에서 실행한 SQL을 파싱해서 사용하는데 같은 쿼리는 파싱한 결과를 재사용할 수 있습니다.
결과적으로 애플리케이션과 데이터베이스 모두 해당 쿼리의 파싱 결과를 재사용할 수 있어서 전체 성능이 향상됩니다.
따라서 파라미터 바인딩 방식은 선택이 아닌 필수입니다.
// 파라미터 바인딩 방식을 사용하지 않고 직접 JPQL을 만들면 위험합니다.
"select m from Member m where m.username = '" + username + "'"프로젝션
SELECT 절에 조회할 대상을 지정하는 것을 프로젝션(projection)이라 하고 [SELECT {프로젝션 대상} FROM]으로 대상을 선택합니다.
프로젝션 대상은 엔티티, 임베디드 타입, 스칼라 타입이 있습니다.
스칼라 타입은 숫자, 문자 등 기본 데이터타입을 뜻합니다.
엔티티 프로젝션
SELECT m FROM Member m // 회원
SELECT m.team FROM Member m // 팀처음은 회원을 조회했고 두 번째는 회원과 연관된 팀을 조회했는데 둘 다 엔티티를 프로젝션 대상으로 사용했습니다.
쉽게 생각하면 원하는 객체를 바로 조회한 것인데 컬럼을 하나하나 나열해서 조회해야 하는 SQL과는 차이가 있습니다. 참고로 이렇게 조회한 엔티티는 영속성 컨텍스트에서 관리합니다.
임베디드 타입 프로젝션
JPQL에서 임베디드 타입은 엔티티와 거의 비슷하게 사용됩니다. 임베디드 타입은 조회의 시작점이 될 수 없다는 제약이 있습니다.
다음은 임베디드 타입인 Address를 조회의 시작점으로 사용해서 잘못된 쿼리입니다.
String query = "SELECT a FROM Address a"; // 에러 : Cannot resolve symbol 'Address'다음 코드에서 Order 엔티티가 시작점입니다.
이렇게 엔티티를 통해서 임베디드 타입을 조회할 수 있습니다.
Product product = new Product("상품이름", 1000, 1);
em.persist(product);
Address address = new Address("city", "street", "zipCode");
Order order = new Order(1, address, product);
em.persist(order);
String query = "select o.address FROM Order o";
List<Address> findAddress = em.createQuery(query, Address.class)
.getResultList();실행된 SQL은 다음과 같습니다.
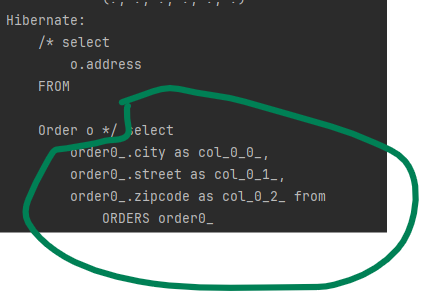
임베디드 타입은 엔티티 타입이 아닌 값 타입입니다.
따라서 이렇게 직접 조회한 임베디드 타입은 영속성 컨텍스트에서 관리되지 않습니다.
스칼라 타입 프로젝션
숫자, 문자, 날짜와 같은 기본 데이터 타입들을 스칼라 타입이라고 합니다.
예를 들어 전체 회원의 이름을 조회하려면 다음처럼 쿼리하면 됩니다.
List<String> username = em.createQuery("select username from Member m", String.class)
.getResultList();중복 데이터를 제거하려면 DISTINCT를 사용하면 됩니다.
"select distinct username from Member m"다음과 같은 통계 쿼리도 주로 스칼라 타입으로 조회합니다.
통계 쿼리용 함수들은 뒤에서 설명합니다.
Double orderAmountAvg =
em.createQuery("SELECT AVG(o.orderAmount) FROM Order o", Double.class)
.getSingleResult();여러 값 조회
엔티티를 대상으로 조회하면 편리하겟지만, 꼭 필요한 데이터들만 선택해서 조회해야 할 때도 있습니다.
프로젝션에 여러 값을 선택하면 TypeQuery를 사용할 수 없고 대신에 Query를 사용해야 합니다.
다음 예시를 보겠습니다.
Query query = em.createQuery("select m.username, m.age FROM Member m");
List resultList = query.getResultList();
Iterator it = resultList.iterator();
while(it.hasNext()) {
Object[] row = (Object[]) it.next();
String username = (String) row[0];
Integer age = (Integer) row[1];
}제너릭에 Object[]를 사용하면 다음 코드처럼 조금 더 간결하게 개발할 수 있습니다.
List<Object[]> resultList = em.createQuery("select m.username, m.age FROM Member m")
.getResultList();
for(Object[] row: resultList) {
String username = (String) row[0];
Integer age = (Integer) row[1];
}실행결과입니다.
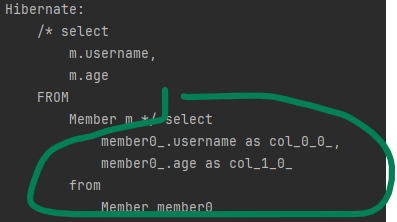
스칼라 타입 뿐만 아니라 엔티티 타입도 여러 값을 함꼐 조회할 수 있습니다.
List<Object[]> resultList = em.createQuery("select o.member, o.product, o.orderAmount FROM Member m")
.getResultList();
for(Object[] row: resultList) {
Member member = (Member) row[0];
Product findProduct = (Product) row[1];
Integer age = (Integer) row[2];
}실행 결과는 다음과 같네요
내부 조인이 꽤 일어납니다.
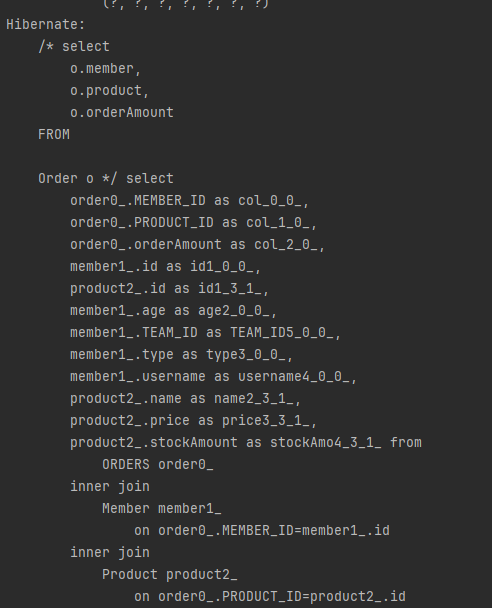
물론 이때도 조회한 엔티티는 영속성 컨텍스트에서 관리됩니다.
NEW 명령어
다음에 볼 예제 코드는 username, age 두 필드를 프로젝션해서 타입을 지정할 수 없으므로 TypeQuery를 사용할 수 없습니다. 따라서 Object[]를 반환받았는데,
실제 애플리케이션 개발시에는 Object[]를 직접 사용하지 않고 MemberDTO처럼 의미있는 객체로 변환해서 사용합니다.
List<Object[]> resultList = em.createQuery("select m.username, m.age FROM Member m")
.getResultList();
// 객체 변환 작업
List<MemberDTO> memberDTOs = new ArrayList<>();
for(Object[] row: resultList) {
MemberDTO memberDTO = new MemberDTO((String) row[0], (Integer) row[1]);
memberDTOs.add(memberDTO);
}
// MemberDTO
public class MemberDTO {
private String username;
private int age;
public MemberDTO(String username, int age) {
this.username = username;
this.age = age;
}
public String getUsername() {
return username;
}
public int getAge() {
return age;
}
}이런 객체 변환 작업은 지루합니다.
이번에는 다음 예시처럼 NEW 명령어를 사용해보겠습니다.
TypedQuery<MemberDTO> query =
em.createQuery("SELECT new jpql.MemberDTO(m.username, m.age) FROM Member m", MemberDTO.class);
List<MemberDTO> resultList = query.getResultList();SELECT 다음에 NEW 명령어를 사용하면 반환받을 클래스를 지정할 수 있는데 이 클래스의 생성자에 JPQL 조회 결과를 넘겨줄 수 있습니다.
그리고 NEW 명령어를 사용한 클래스로 TypeQuery를 사용할 수 있어서 지루한 객체 변환 작업을 줄일 수 있습니다.
NEW 명령어를 사용할 때는 다음 2가지를 주의해야 합니다.
- 패키지 명을 포함한 전체 클래스 명을 입력해야 합니다.
- 순서와 타입이 일치하는 생성자가 필요합니다.
페이징 API
페이징 처리용 SQL을 작성하는 일은 지루하고 반복적입니다.영한님은 강의에서 "거지 같다고 표현까지 하셨습니다."
더 큰 문제는 데이터베이스마다 페이징을 처리하는 SQL 문법이 다르다는 점입니다.
JPA는 페이징을 다음 두 API로 추상화했습니다.
- setFirstResult(int startPosition) : 조회 시작 위치(0부터 시작한다.)
- setMaxResults(int maxResult) : 조회할 데이터 수
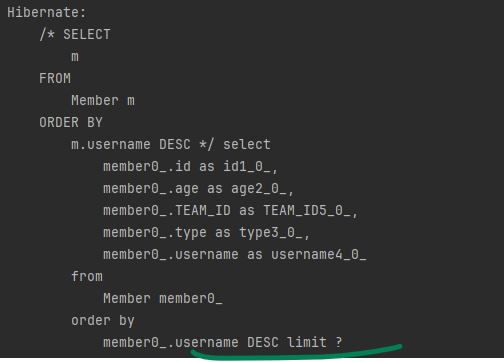
TypedQuery<Member> query =
em.createQuery("SELECT m FROM Member m ORDER BY m.username DESC", Member.class);
query.setFirstResult(0);
query.setMaxResults(1);
query.getResultList();위의 예제를 분석하면 FirstResult의 시작은 0이므로 1번째부터 시작하여 총 1간의 데이터를 조회합니다. 따라서 1번의 데이터를 조회하는데요.
데이터베이스마다 다른 페이징 처리를 같은 API로 처리할 수 있는 것은 데이터베이스 방언(Dialect) 덕분입니다.
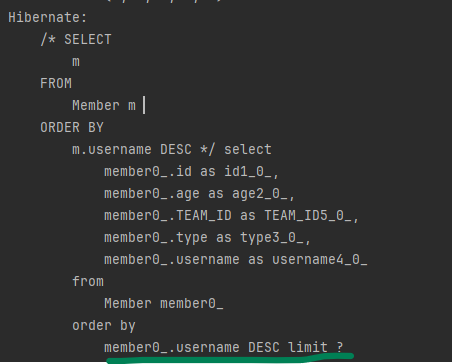
이 JPQL이 방언에 따라 어떤 SQL로 변환되는지 확인해보겟습니다.
(참고로 페이징 쿼리는 정렬조건이 중요하므로 예제에 포함되었습니다.)
H2
오라클12
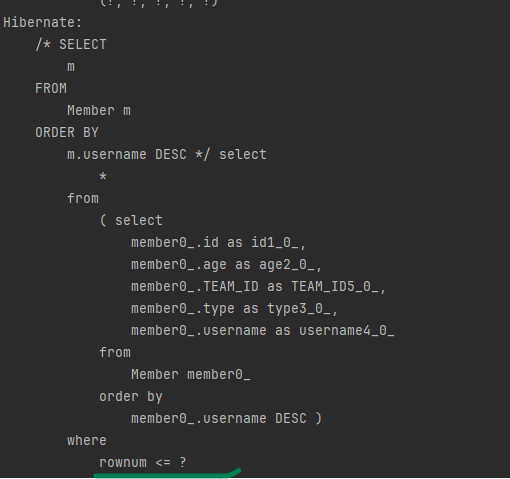
Postgre-s9
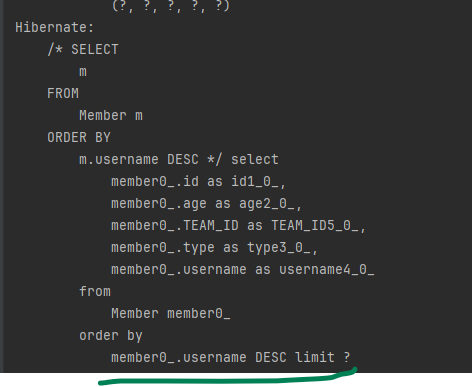
SQLSERVER20012
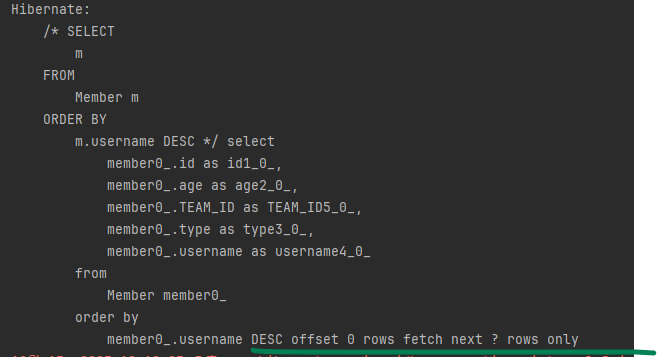
SQLSERVER2008
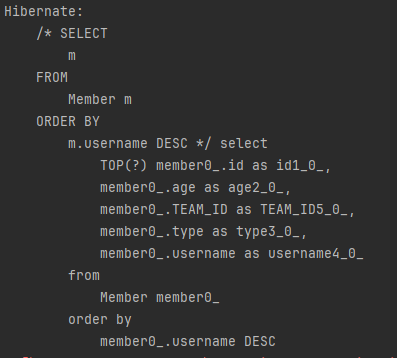
MySQL
데이터베이스마다 SQL이 다른 것은 물론이고 오라클과 SQLServer는 페이징 쿼리를 따로 공부해야 SQL을 작성할 수 있을 정도로 복잡합니다.
참고로 ?에 바인딩하는 값도 데이터베이스마다 다른데 이 값도 적절한 값을 입력합니다.
실행된 페이징 SQL을 보면 실무에서 작성한 것과 크게 다르지 않을 것입니다.
페이징 SQL을 더 최적화하고 싶다면 JPA가 제공하는 페이징 API가 아닌 네이티브 SQL을 직접 사용해야 합니다.
집합과 정렬
집합은 집합함수돠 함께 통계 정보를 구할 때 사용합니다.
예를 들어 다음 코드는 순서대로 회원수, 나이 합, 평균 나이, 최대 나이, 최소 나이를 조회합니다.
select
count(m), // 회원수
SUM(m.age), // 나이 합
AVG(m.age), // 평균 나이
MAX(m.age), // 최대 나이
MIN(m.age), // 최소 나이
from Member m집합 함수
| 함수 | 설명 |
|---|---|
| COUNT | 결과 수를 구합니다. 반환 타입 => Long |
| MAX, MIN | 최대, 최소 값을 구합니다. 문자, 숫자, 날짜 등에 사용합니다. |
| AVG | 평균값을 구합니다. 숫자타입만 사용할 수 있습니다. 반환 타입 => Double |
| SUM | 합을 구합니다. 숫자타입만 사용할 수 있습니다. 반환 타입 => 정수합: Long, 소수합: Double, BigInteger합: BigInteger, BigDecimal합: BigDecimal |
집합 함수 사용 시 참고사항
- NULL 값은 무시하므로 통계에 잡히지 않는다. (DISTINCT가 정의되어 있어도 무시됩니다.)
- 만약 값이 없는데 SUM, AVG, MAX, MIN 함수를 사용하면 NULL 값이 됩니다. 단 COUNT는 0dl ehlqslek.
- DISTINCT를 집합 함수 안에 사용해서 중복된 값을 제거하고 나서 집합을 구할 수 있습니다.
- 예
select COUNT(DISTINT m.age) FROM Member m
- 예
- DISTINCT를 COUNT에서 사용할 때 임베디드 타입은 지원하지 않습니다.
GROUP BY, HAVING
GROUP BY는 통계 데이터를 구할 때 특정 그룹끼리 묶어줍니다.
다음은 팀 이름을 기준으로 그룹별로 묶어서 통계 데이터를 구합니다.
select t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age), MIN(m.age)
FROM Member m LEFT JOIN m.team t
GROUP BY t.nameHAVING은 GROUP BY와 함께 사용하는데 GROUP BY로 그룹화한 통계 데이터를 기준으로 필터링합니다.
다음 코드는 방금 구한 그룹별 통계 데이터 중에서 평균나이가 10살 이상인 그룹을 조회합니다.
select t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age), MIN(m.age)
FROM Member m LEFT JOIN m.team t
GROUP BY t.name
HAVING AVG(m.age) >= 10문법은 다음과 같습니다.
groupby_절 ::= GROUP BY {단일 값 경로 | 별칭} +
having_절 ::= HAVING 조건식이런 쿼리들을 보통 리포팅 쿼리나 통계 쿼리라고 합니다.
이러한 통계 쿼리를 잘 활용하면 애플리케이션으로 수십 라인을 작성할 코드도 단 몇 줄이면 처리할 수 있습니다.
하지만 통계 쿼리는 보통 전체 데이터를 기준으로 처리하므로 실시간으로 사용하기엔 부담이 많습니다.
결과가 아주 많다면 통계 결과만 저장하는 테이블을 별도로 만들어 두고 사용자가 적은 새벽에 통계 쿼리를 실행해서 그 결과를 보관하는 것이 좋습니다.
정렬(ORDER BY)
ORDER BY는 결과를 정렬할 때 사용합니다.
다음은 나이를 기준으로 내림차순으로 정렬하고 나이가 같으면 이름을 기준으로 오름차순으로 정렬합니다.
select m from Member m order by m.age DESC, m.username ASC문법은 다음과 같습니다.
orderby_절 ::= ORDER BY { 상태필드 경로 | 결과 변수 [ASC | DESC]} +- ASC : 오름차순(기본값)
- DESC : 내림차순
문법에서 이야기하는 상태필드는 t.name 같이 객체의 상태를 나타내는 필드를 말합니다. 그리고 결과 변수는 SELECT 절에 나타나는 값을 말합니다. 다음 예에서는 cnt가 결과 변수입니다.
select t.name, COUNT(m.age) as cnt
from Member m LEFT JOIN m.team t
GROUP BY t.name
ORDER BY cntJPQL 조인
JPQL도 조인을 지원하는데 SQL 조인과 기능은 같고 문법만 약간 다르다
내부 조인
내부 조인은 INNER JOIN을 사용합니다.
참고로 INNER는 생략할 수 있습니다.
다음 예시를 봅시다.
String teamName = "팀A";
String query = "SELECT m FROM Member m INNSER JOIN m.team t "
+ "WHERE t.name = :teamName";
List<Member> members = em.createQuery(query, Member.class)
.setParameter("teamName", teamName)
.getResultList();회원과 팀을 내부 조인해서 '팀A'에 소속된 회원을 조회하는 JPQL을 보겠습니다.
select m
FROM Member m INNER JOIN m.team t
where t.name = :teamName생성된 내부 조인 SQL은 다음과 같습니다.
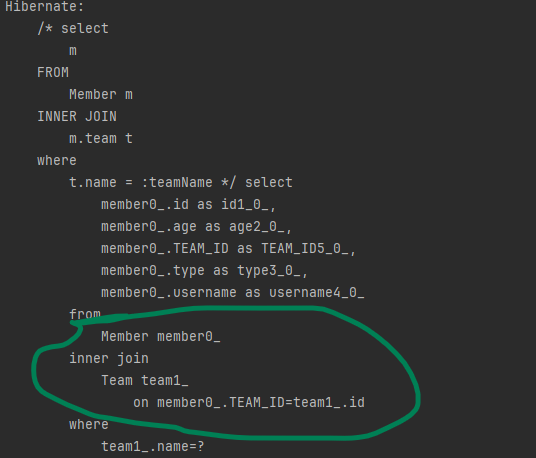
JPQL 내부 조인 구문을 보면 SQL의 조인과 약간 다른 것을 확인할 수 있습니다.
JPQL 조인의 가장 큰 특징은 연관 필드를 사용하는 것입니다.
여기서 m.team이 연관 필드인데 연관 필드는 다른 엔티티와 연관관계를 가지기 위해 사용하는 필드를 말합니다.
FROM Member m: 회원을 선택하고 m 이라는 별칭을 주었습니다.Member m JOIN m.team t: 회원이 가지고 있는 연관 필드로 팀과 조인합니다. 조인한 팀에는 t라는 별칭을 주었습니다.
혹시라도 JPQL 조인을 SQL 조인처럼 사용하면 문법 오류가 발생합니다.
JPQL은 JOIN 명령어 다음에 조인할 객체의 연관 필드 사용한다.
다음은 잘못된 예입니다.
FROM Member m JOIN Team t // 잘못된 JPQL 조인, 오류!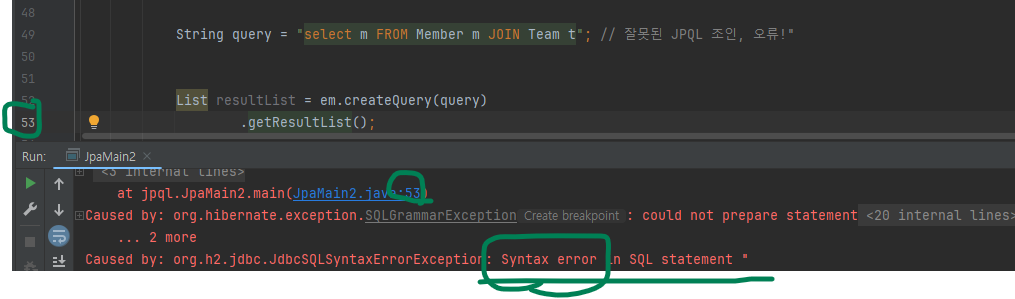
조인 결과를 활용해보겠습니다.

쿼리는 '팀A' 소속인 회원을 나이 내림차순으로 정렬하고 회원명과 팀명을 조회합니다.
만약 조인한 두 개의 엔티티를 조회하려면 다음과 같이 JPQL을 작성하면 됩니다.
select m, t
from Member m join m.team t서로 다른 타입의 두 엔티티를 조회했으므로 TypeQuery를 사용할 수 없습니다.
따라서 다음처럼 조회해야 합니다.
List<Object[]> result = em.createQuery(query).getResultList();
for(Object[] row : result) {
Member member = (Member) row[0];
Team team = (Team) ros[1];
}외부 조인
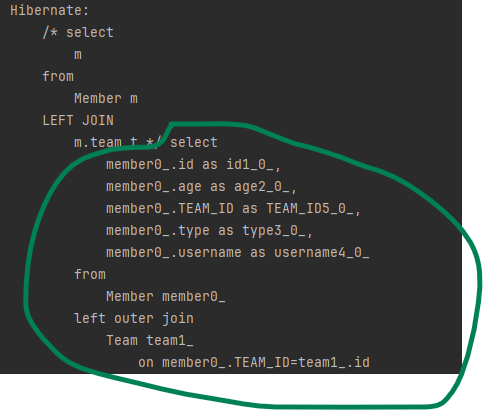
JPQL의 외부 조인은 다음 예와 같이 사용합니다.
select m
from Member m LEFT [OUTER] JOIN m.team t외부 조인은 기능상 SQL의 외부 조인과 같습니다.
OUTER는 생략 가능해서 보통 LEFT JOIN으로 사용합니다.
위의 JPQL을 실행하면 다음 SQL이 실행됩니다.
컬렉션 조인
일대다 관계나 다대다 관계처럼 컬렉션을 사용하는 곳에 조인하는 것을 컬렉션 조인이라고 합니다.
[회원 -> 팀]으로의 조인은 다대일 조인이며 단일 값 연관 필드(m.team)를 사용합니다.[팀 -> 회원]은 반대로 일대다 조인이면서 컬렉션 값 연관 필드(m.members)를 사용합니다.
다음 코드를 보겠습니다.
SELECT t, m FROM Team t LEFT JOIN t.members ,여기서 t LEFT JOIN t.members는 팀과 팀이 보유한 회원 목록을 컬렉션 값 연관 필드로 외부 조인했습니다.
컬렉션 조인 - 참고
컬렉션 조인시 JOIN 대신에 IN을 사용할 수 잇는데, 기능상 JOIN과 같지만 컬렉션일 때만 사용가능합니다. 과거 EJB 시절의 유물이고 특별한 장점도 없기때문에 그냥 JOIN명령어를 사용합시다. ^^
select t, m FROM Team t, IN(t.members) m세타 조인
WHERE 절을 사용해서 세타 조인을 할 수 있습니다.
참고로 세타 조인은 내부 조인만 지원합니다.
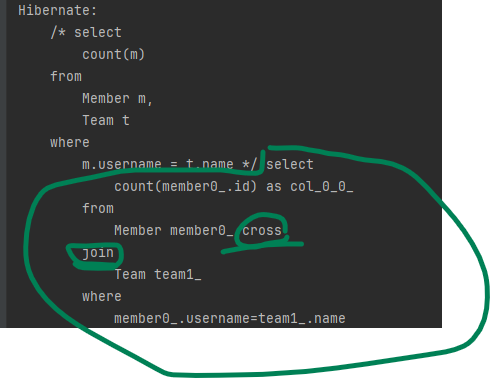
세타 조인을 사용하면 다음 예시처럼 전혀 관계없는 엔티티도 조인할 수 있습니다.
다음 예를 보면 전혀 관련없는 Member.username과 Team.name을 조인합니다.
// JPQL
select count(m) from Member m, Team t
where m.username = t.name다음은 결과 입니다.
JOIN ON 절(JPA 2.1)
JPA 2.1부터 조인할 ON 절을 지원합니다. ON 절을 사용하면 조인 대상을 필터링하고 조인할 수 있습니다.
참고로 내부 조인의 ON 절은 WHERE 절을 사용할 때와 결과가 같으므로 보통 ON 절은 외부 조인에서만 사용합니다.
다음 예시를 보면, 모든 회원을 조회하면서 회원과 연관된 팀도 조회합니다.
이때 이름이 A인 팀만 조회합니다.
// JPQL
select m,t from Member m
left join m.team t on t.name = 'A'다음은 실행 결과입니다.
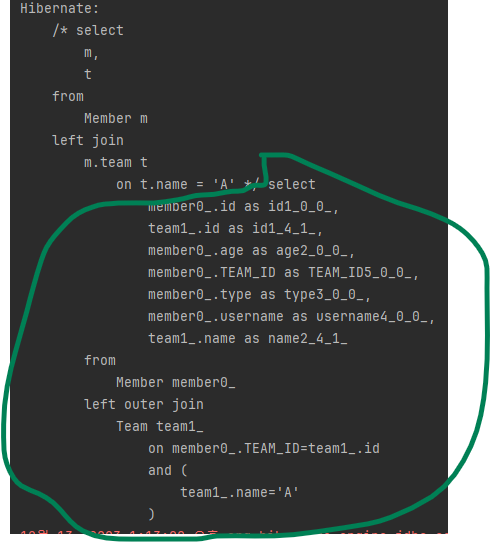
마치 m.*, t.*을 한 것과 같습니다.
SQL 결과를 보면 and t.name='A'로 조인 시점에 조인 대상을 필터링합니다.
페치 조인
페치(fetch) 조인은 SQL에서 이야기하는 조인의 종류른 아니고 JPQL에서 성능 최적화를 위해 제공하는 기능입니다. 이것은 연관된 엔티티나 컬렉션을 한 번에 같이 조회하는 기능인데 join fetch 명령어로 사용할 수 있습니다.
JPA 표준 명세에 정의된 페치 조인 문법은 다음과 같습니다.
페치조인 ::= [ LEFT [OUTER] | INNER ] JOIN FETCH 조인경로
페치 조인에 대해 자세히 알아보겠습니다.
엔티티 페치 조인
페치 조인을 사용해서 회원 엔티티를 조회하면서도 연관된 팀 엔티티도 함께 조회하는 JPQL을 보겠습니다.
Team teamA = new Team();
teamA.setName("팀A");
em.persist(teamA);
Team teamB = new Team();
teamB.setName("팀B");
em.persist(teamB);
Team teamC = new Team();
teamC.setName("팀C");
em.persist(teamC);
Member member1 = new Member();
member1.setUsername("회원1");
member1.setAge(11);
member1.setTeam(teamA);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("회원2");
member2.setAge(22);
member2.setTeam(teamA);
em.persist(member2);
Member member3 = new Member();
member3.setUsername("회원3");
member3.setAge(33);
member3.setTeam(teamB);
em.persist(member3);
Member member4 = new Member();
member4.setUsername("회원4");
member4.setAge(44);
// member4.setTeam(teamB);
em.persist(member4);
String query = "select m from Member m join fetch m.team";
em.createQuery(query)
.getResultList();
위의 코드를 보면 join 다음에 fetch라 적었습니다.
이렇게 하면 연관된 엔티티나 컬렉션을 함께 조회하는데 여기서는 회원(m)과 팀(m.team)을 함께 조회합니다.
참고로 일반적인 JPQL 조인과는 다르게 m.team 다음에 별칭이 없는데 페치 조인은 별칭을 사용할 수 없습니다.
| 참고로 하이버네이트는 페치 조인에도 별칭을 허용합니다.
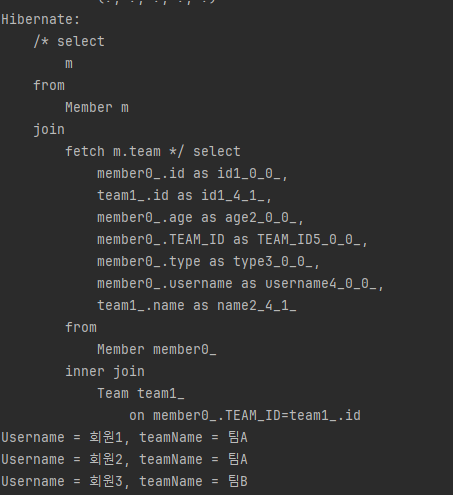
실행된 SQL은 다음과 같습니다.
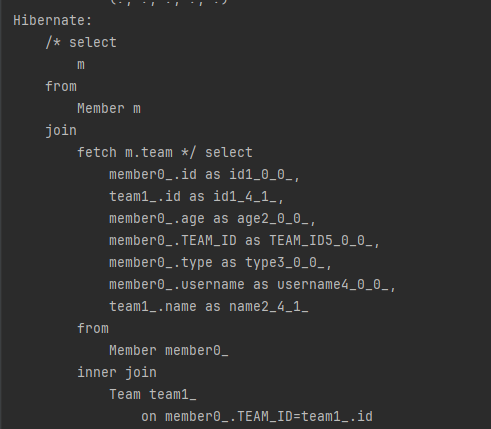
페치 조인을 사용하면 다음 그림처럼 SQL 조인을 시도합니다.
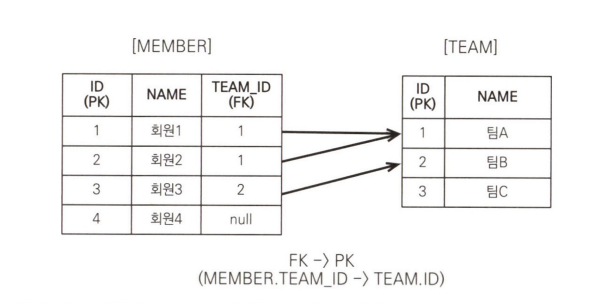
다음은 SQL에서 조인의 결과입니다.
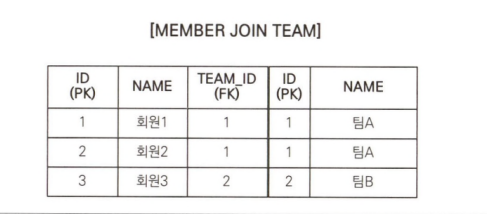
다은은 엔티티 페치 조인 결과를 객체로 표현한 것입니다.
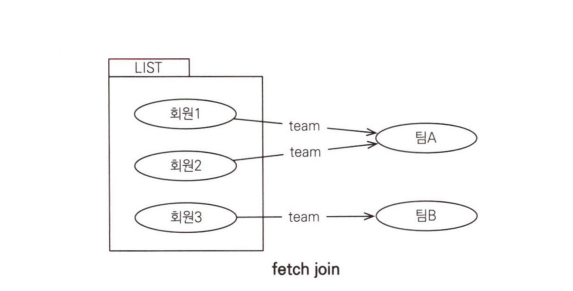
엔티티 페치 조인 JPQL에서 select m으로 회원 엔티티만 선택했는데 실행된 SQL을 보면 SELECT M.*, T.*로 연관된 팀도 함께 조회된 것을 확인할 수 있습니다. 그리고 객체로 표현한 그림을 보면 회원과 팀 객체가 객체 그래프를 유지하면서 조회된 것을 확인할 수 있습니다. 다음 예는 JPQL을 사용하는 코드입니다.
String query = "select m from Member m join fetch m.team";
List<Member> members = em.createQuery(query, Member.class)
.getResultList();
for(Member member : members) {
// 페치 조인으로 회원과 팀을 함께 조회해서 지연로딩 발생 안 함
System.out.println("Username = " + member.getUsername());
System.out.println("teamName = " + member.getTeam().getName());
}다음은 실행 결과입니다.
회원과 팀을 지연 로딩으로 설정했다고 가정해봅시다. 회원을 조회할 때 페치 조인을 사용해서 팀도 함께 조회했으므로 연관된 팀 엔티티는 프록시가 아닌 실제 엔티티입니다. 따라서 연관된 팀을 사용해서 지연 로딩이 일어나지 않습니다. 그리고 프록시가 아닌 실제 엔티티이므로 회원 엔티티가 영속성 컨텍스트에서 분리되어 준영속 상태가 되어도 연관된 팀을 조회할 수 있습니다.
컬렉션 페치 조인
이번에는 일대다 관계인 컬렉션을 페치 조인해보겠습니다.
select t from Team t join fetch t.members where t.name = '팀A'다음은 실행 결과입니다.
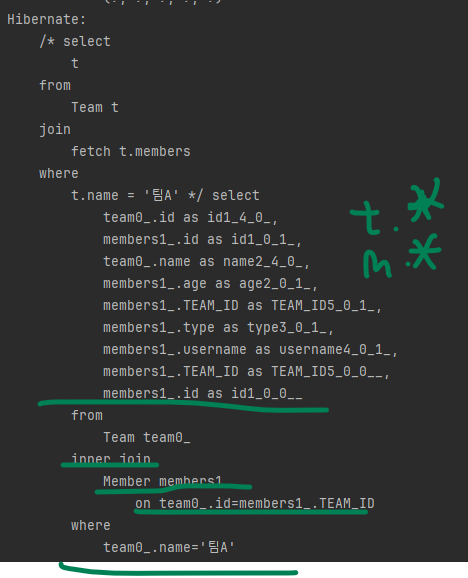
컬렉션 페치 조인 시도 그림입니다.
컬렉션 페치 조인 결과 테이블입니다.
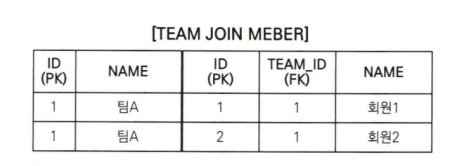
컬렉션 페치 조인 결과를 객체로 표현한 것입니다.
컬렉션 페치 조인 JPQL에서 select t로 팀만 선택했는데, 실행 결과 SQL을 보면, T.*, M.*로 팀과 연관된 회원도 함꼐 조회한 것을 확인할 수 있습니다.
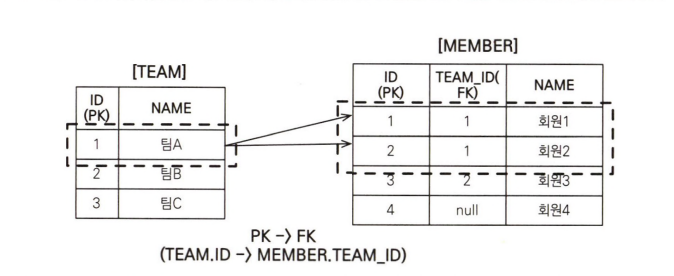
그리고 컬렉션 페치 조인 시도 그림을 보면 TEAM 테이블에서 '팀A'는 하나지만 MEMBER 테이블과 조인하면서 결과가 증가해서 컬렉션 페치 조인 결과 테이블 그림을 보면 같은 팀A가 2건 조회되었습니다.
따라서 객체로 표현한 그림에서 teams 결과 예제를 보면 주소가 0x100으로 같은 '팀A`를 2건 가지게 됩니다.
컬렉션 페치 조인을 사용하는 다음 예를 보겠습니다.
| 참고로 일대다 조인은 결과가 증가할 수 있지만 일대일, 다대일 조인은 결과가 증가하지 않습니다.
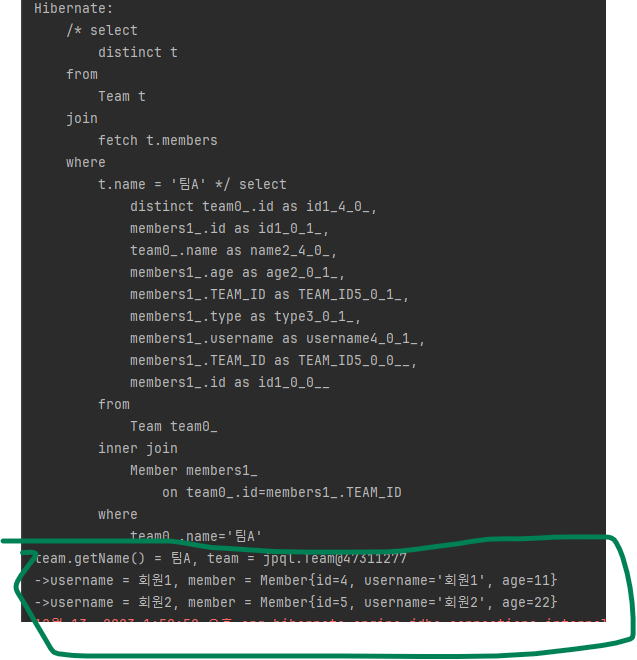
String query = "select t from Team t join fetch t.members where t.name = '팀A'";
List<Team> teams = em.createQuery(query, Team.class).getResultList();
for(Team team : teams) {
System.out.println("team.getName() = " + team.getName() + ", team = " + team);
for(Member member : team.getMembers()) {
//페치 조인으로 팀과 회원을 함꼐 조회해서 지연 로딩 발생 안함
System.out.println(
"->username = " + member.getUsername() + ", member = " + member);
}
}실행 결과는 다음과 같습니다.
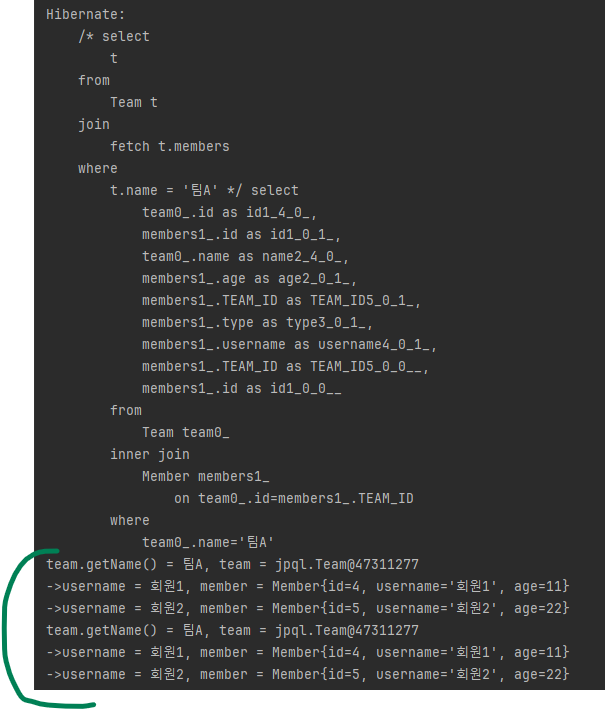
출력 결과를 보면 같은 '팀A'가 2건 조회된 것을 확인할 수 있습니다.
페치 조인과 DISTINCT
SQL의 DISTINCT는 중복된 결과를 제거하는 명령어입니다.
JPQL의 DISTINCT 명령어는 SQL에 DISTINCT를 추가하는 것은 물론이고, 애플리케이션에서 한 번 더 중복을 제거합니다.
바로 직전에 컬렉션 페치 조인은 팀A가 중복으로 조회됩니다.
다음처럼 DISTINCT를 추가해보겠습니다.
select distinct t from Team t join fetch t.members where t.name = '팀A'먼저 DISTINCT를 사용하면 SQL에 select distinct가 추가됩니다.
하지만 지금은 각 로우의 데이터가 다르므로 다음 표처럼 SQL의 DISTINCT는 효과가 없습니다.
데이터가 다르기 때문에 SQL의 DISTINCT 효과가 없습니다.
| 로우번호 | 팀 | 회원 |
|---|---|---|
| 1 | 팀A | 회원1 |
| 2 | 팀A | 회원2 |
다음으로 애플리케이션에서 distinct 명령어를 보고 중복된 데이터를 걸러냅니다.
select distinct t의 의미는 팀 엔티티의 중복을 제거하라는 것입니다.
따라서 중복인 팀A는 다음 그림처럼 하나만 조회됩니다.
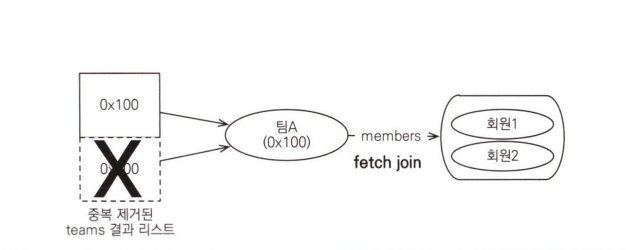
다음은 실행 결과입니다.
페치 조인과 일반 조인의 차이
페치조인을 사용하지 않고 조인만 사용하면 어떻게 될까요?
select t from Team t join t.members m where t.name = '팀A'다음은 실행된 SQL입니다.
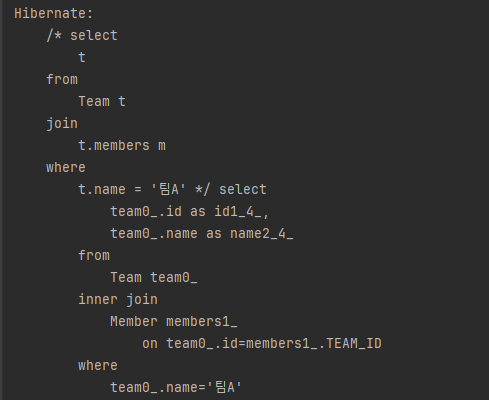
JPQL에서 팀과 회원 컬렉션을 조인했으므로 회원 컬렉션도 함꼐 조회할 것으로 기대해선 안 됩니다.
실행된 SQL의 SELECT 적을 보면 팀만 조회하고 조인했던 회원은 전혀 조회하지 않습니다.
JPQL은 결과를 반환할 때 연관관계까지 고려하지 않습니다.
단지 SELECT 절에 지정한 엔티티만 조회할 뿐입니다.
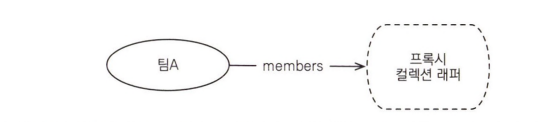
따라서 팀 엔티티만 조회하고 연관된 회원 컬렉션은 조회하지 않습니다. 만약 회원 컬렉션을 지연 로딩으로 설정하면 다음 그림과 같이 프록시나 아직 초기화하지 않은 컬렉션 레퍼를 반환합니다. 즉시 로딩으로 설정하면 회원 컬렉션을 즉시 로딩하기 위해 쿼리를 한 번 더 실행합니다.
반면에 페치 조인을 사용하면 연관된 엔티티도 함께 조회합니다.
다음 예를 보겠습니다.
select t
from Team t join fetch t.members
where t.name = '팀A'실행된 SQL은 다음과 같습니다.
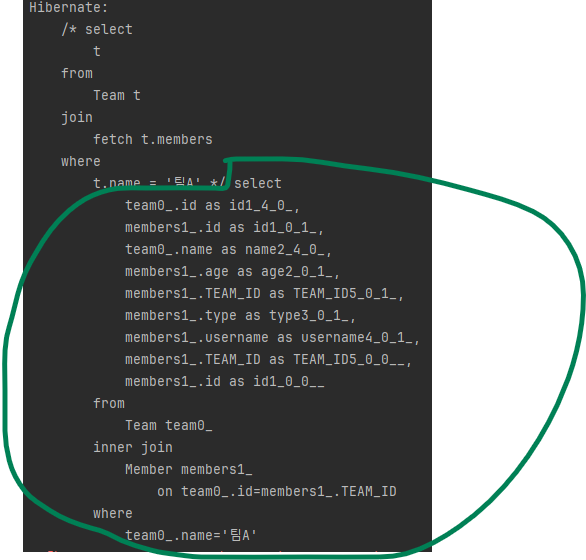
SELECT T.*, M.*로 팀과 회원을 함께 조회한 것을 알 수 있습니다.
페치 조인의 특징화 한계
페치 조인을 사용하면 SQL 한번으로 연관된 엔티티들을 함께 조회할 수 있어서 SQL 호출 횟수를 줄여 성능을 최적화할 수 있습니다.
다음처럼 엔티티에 직접 적용하는 로딩 전략은 애플리케이션 전체에 영향을 미치므로 글로벌 로딩 전략이라고 부릅니다.
페치 조인은 글로벌 로딩 전략보다 우선합니다.
예를 들어 글로벌 로딩 전략을 지연 로딩으로 설정해도 JPQL에서 페치 조인을 사용하면 페치 조인을 적용해서 함께 조회합니다.
@OneToMany(fetch = FetchType.LAZY) // 글로벌 로딩 전략최적화를 위해 글로벌 로딩 전략을 즉시 로딩으로 설정하면 애플리케이션 전체에서 항상 즉시 로딩이 일어납니다. 물론 일부는 빠를 수는 있지만 전체로 보면 사용하지 않는 엔티티를 자주 로딩하므로 오히려 성능에 악영향을 미칠 수 있습니다. 따라서 글로벌 로딩 전략은 될 수 있으면 지연 로딩을 사용하고 최적화가 필요하면 페치 조인을 적용하는 것이 효과적입니다.
또한 페치 조인을 사용하면 연관된 엔티티를 쿼리 시점에 조회하므로 지연 로딩이 발생하지 않습니다. 따라서 준영속 상태에서도 객체 그래프를 탐색할 수 있습니다.
페치 조인은 다음과 같은 한계가 있습니다.
페치 조인 대상에는 별칭을 줄 수 없습니다.
- 문법을 자세히 보면 페치 조인에 별칭을 정의하는 내용이 없습니다. 따라서 SELECT, WHERE 절, 서브 쿼리에 페치 조인 대상을 사용할 수 없습니다.
- JPA 표준에서는 지원하지 않지만 하이버네이트를 포함한 몇몇 구현체들은 페치 조인에 별칭을 지원합니다. 하지만 별칭을 잘못 사용하면 연관된 데이터 수가 달라져서 데이터 무결설이 깨질 수 있으므로 조심해서 사용해야 합니다. 특히 2차 캐시와 함께 사용할 때 조심해야 하는데, 연관된 데이터 수가 달라진 상태에서 2차 캐시에 저장되면 다른 곳에서 조회할 때도 연관된 데이터 수가 달라지는 문제가 발생할 수 있습니다. (2차캐시는 책 후반에 있습니다.)
둘 이상의 컬렉션을 페치할 수 없습니다.
- 구현체에 따라 되기도 하는데 컬렉션 * 컬렉션의 카테이산 곱이 만들어지므로 주의해야 합니다. 하이버네이트를 사용하면
javax.persistence.PersistenceException: org.hibernte.loader.MultipleMagFetchException: cannot simultaneously fetch multiple bags예외가 발생합니다.
- 구현체에 따라 되기도 하는데 컬렉션 * 컬렉션의 카테이산 곱이 만들어지므로 주의해야 합니다. 하이버네이트를 사용하면
컬렉션을 페치 조인하면 페이징 API(setFirsetResult, setMaxResults)를 사용할 수 없습니다.
컬렉션(일대다)이 아닌 단일 값 연관 필드(일대일, 다대일)들은 페치 조인을 사용해도 페이징 API를 사용할 수 있습니다.
하이버네이트에서 컬렉션을 페치 조인하고 페이징 API를 사용하면 경고 로그를 남기면서 메모리에서 페이징 처리를 합니다. 데이터가 적으면 상관없겠지만 데이터가 많으면 성능 이슈와 메모리 초과 예외가 발생할 수 있어서 위험합니다.
String query = "select t from Team t join fetch t.members where t.name = '팀A'"; List resultList = em.createQuery(query) .setFirstResult(0) .setMaxResults(2) .getResultList();경고메세지는 다음과 같습니다.
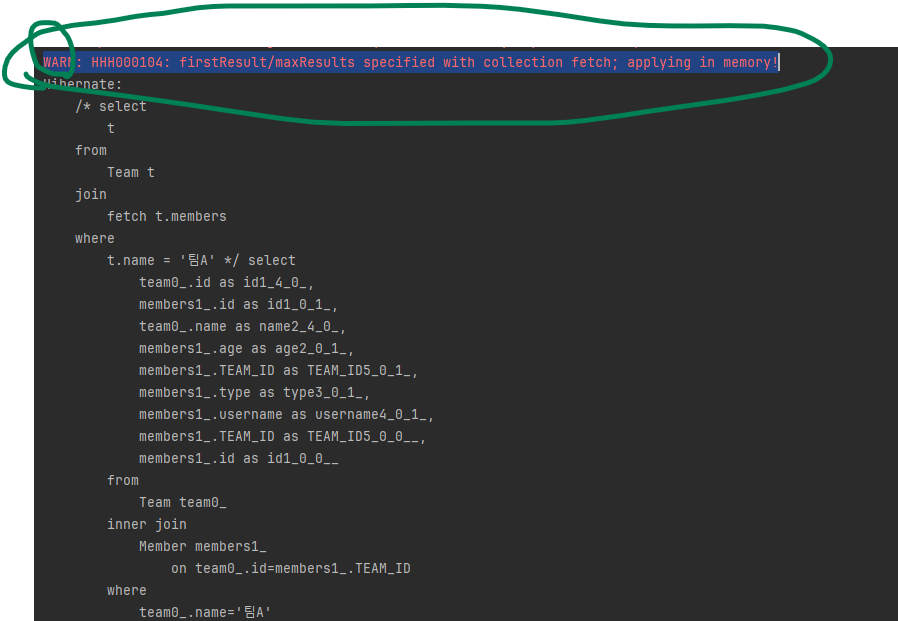
페치 조인은 SQL 한 번으로 연관된 여러 데이터를 조회할 수 있어서 성능 최적화에 상당히 유용합니다.
그리고 실무에서 자주 사용하게 됩니다.
하지만 모든 것을 페치 조인으로 해결할 수는 없습니다.
페치 조인은 객체 그래프를 유지할 떄 사용하면 효과적입니다.
반면에 여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야 한다면 억지로 페치 조인을 사용하기보다는 여러 테이블에서 필요한 필드들만 조회해서 DTO로 반환하는 것이 더 효과적일 수 있습니다.
경로 표현식
지금까지 JPQL 조인을 알아보았습니다.
이번에는 JPQL에서 사용하는 경로 표션식(Path Expression)을 알아보고 경로 표현식을 통한 묵시적 조인을 알아보겠습니다.
경로 표현식이라는 것은 쉽게 이야기해서 .(점)을 찍어 객체 그래프를 탐색하는 것입니다.
select m.username
from Member m
join m.team t
join m.orders o
where t.name = '팀A'여기서 m.username, m.team, m.orders, t.name이 모두 경로 표현식을 사용한 예입니다.
경로 표현식의 용어 정리
경로 표현식을 이해하려면 우선 다음 용어들을 알아야 합니다.
- 상태 필드(state field) : 단순히 값을 저장하기 위한 필드(필드 or 프로퍼티)
- 연관 필드(associtaion field) : 연관관계를 위한 필드, 임베디드 타입 포함(필드 or 프로퍼티)
- 단일 값 연관 필드 : @ManyToOne, @OneToOne, 대상이 엔티티
- 컬렉션 값 연관 필드 : @OneToMany, @ManyToMany, 대상이 컬렉션
상태 필드는 단순히 값을 저장하는 필드이고 연관 필드는 객체 사이의 연과관계를 맺기 위해 사용파는 필드입니다. 다음 예시로 상태 필드와 연관 필드를 알아보겠습니다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "name")
private String username; // 상태 필드
private int age; // 상태 필드
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team; // 연관 필드(단일 값 연관 필드)
@OneToMany
private List<Order> orders = new ArrayList<>(); // 연관 필드(컬렉션 값 연관 필드)
}정리하면 다음 3가지 경로 표현식이 있습니다.
- 상태 필드 : 예 t.username, t.age
- 단일 값 연관 필드 : 예 m.team
- 컬렉션 값 연관 필드 : 예 m.orders
경로 표현식과 특징
JPQL에서 경로 표현식을 사용해서 경로 탐색을 하려면 다음 3가지 경로에 따라 어떤 특징이 있 느지 이해해야 합니다.
- 상태 필드 경로 : 경로 탐색의 끝입니다. 더는 탐색할 수 없습니다.
- 단일 값 연관 경로 : 묵시적으로 내부 조인이 일어납니다. 단일 값 연관 경로는 계속 탐색할 수 있습니다.
- 컬렉션 값 연관 경로 : 묵시적으로 내부 조인이 일어납니다. 더는 탐색할 수 없습니다. 단 FROM 절에서 조인을 통해 별칭을 얻으면 별칭으로 탐색할 수 있습니다.
예제를 통해 경로 탐색을 하나씩 알아보겠습니다.
상태 필드 경로 탐색
다음 JPQL의 m.username, m.age는 상태 필드 경로 탐색입니다.
select m.username, m.age from Member m이 JPQL을 실행한 결과 SQL은 다음과 같습니다.
select m.username, m.age
from Member m단일 값 연관 경로 탐색
다음 JPQL을 보겠습니다.
select o.member from Order o이 JPQL을 실행한 결과 SQL은 다음과 같습니다.
select m.*
from Orders o
inner join Member m on o.member_id = m.idJPQL을 보면 o.member를 통해 주문에서 회원으로 단일 값 연관 필드로 경로 탐색을 햇습니다. 단일 값 연관 필드로 경로 탐색을 하면 SQL에서 내부 조인이 일어나는데 이것을 묵시적 조인이라고 합니다. 참고로 묵시적 조인은 모두 내부 조인입니다.
외부 조인은 명식적으로 JOIN 키워드를 사용해야 합니다.
- 명시적 조인 : JOIN을 직접 적어주는 것
- 예 :
SELECT m FROM Member m JOIN m.team t
- 예 :
- 묵시적 조인 : 경로 표현식에 의해 묵시적으로 조인이 일어나는 것, 내부 조인(INNER JOIN)만 할 수 있습니다.
- 예 :
SELECT m.team FROM Member m
- 예 :
이번에는 복잡한 예제를 보겠습니다.
다음 그림과 코드를 보고 JPQL을 살펴보겠습니다.
select o.member.team
from Order o
where o.product.name = 'productA' and o.address.city = 'JINJU'주문 중에서 상품명이 'productA'이고 배송지가 'JINJU'인 회원이 소속된 팀을 조회합니다. 실제 내부 조인이 몇 번 일어날지 생각해봅시다.
실행 결과는 다음과 같습니다.
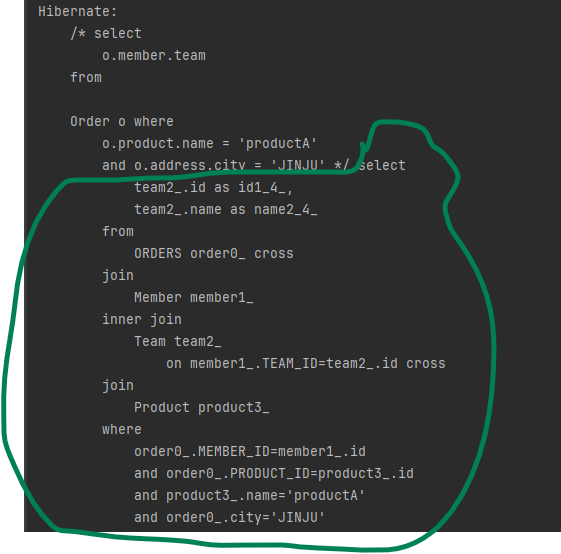
위처럼 실행된 SQL을 보면 총 3번의 조인이 발생했습니다.
참고로 o.address처럼 임베디드 타입에 접근하는 것도 단일 값 연관 경로 탐색이지만 주문 테이블에 이미 포함되어 있으므로 조인이 발생하지 않습니다.
컬렉션 값 연관 경로 탐색
JPQL을 다루면서 많이 하는 실수 중 하나는 컬렉션 값에서 경로 탐색을 시도하는 것입니다.
select t.member from Team t // 성공
select t.members.username from Team t // 실패실패 결과입니다.

t.members 처럼 컬렉션까지는 경로 탐색이 가능합니다.
하지만 t.members.username처럼 컬렉션에서 경로 탐색을 시작하는 것은 허락하지 않습니다.
만약 컬렉션에서 경로탐색을 하고 싶으면 다음 코드처럼 조인을 사용해서 새로운 별칭을 획득해야 합니다.
select m.username from Team t join t.members mjoin t.members m으로 컬렉션에 새로운 별칭을 얻었습니다.
이제 별칭 m부터 다시 경로 탐색을 할 수 있습니다.
참고로 컬렉션은 컬렉션의 크기를 구할 수 있는 size라는 특별한 기능을 사용할 수 있습니다. size를 사용하면 COUNT함수를 사용하는 SQL로 적절히 변환됩니다.
select t.members.size from Team t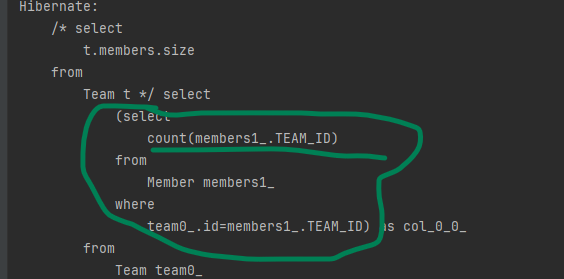
경로 탐색을 사용한 묵시적 조인 시 주의사항
경로 탐색을 사용하면 묵시적 조인이 발생해서 SQL에서 내부 조인이 일어날 수 있습니다. 이때 주의사항은 다음과 같습니다.
- 항상 내부 조인입니다.
- 컬렉션은 경로 탐색의 끝입니다. 컬렉션에서 경로 탐색을 하려면 명시적으로 조인해서 별칭을 얻어야 합니다.
- 경로 탐색은 주로 SELECT, WHERE 절(다른 곳에서도 사용됨)에서 사용하지만, 묵시적 조인으로 인해 SQL의 FROM 절에 영향을 줍니다.
조인이 성능상 차지하는 부분은 아주 큽니다. 묵시적 조인이 일어나는 상황을 한눈에 파악하기 어렵다는 단점이 있습니다. 따라서 단순하고 성능에 이슈가 없으면 크게 문제가 안 되지만 성능이 중요하면 분석하기 쉽도록 묵시적 조인보다는 명시적 조인을 사용합시다.
서브쿼리
JPQL도 SQL처럼 서브 쿼리를 지원합니다.
여기에는 몇 가지 제약이 있는데, 서브쿼리를 WHERE, HAVING 절에서만 사용할 수 있고, SELECT, FROM 절에서는 사용할 수 없습니다.
| 참고로 하이버네이트의 HQL은 SELECT 절의 서브 쿼리도 허용합니다. 하지만 아직까지 FROM 절의 서브 쿼리는 지원하지 않습니다. 일부 JPA 구현체는 FROM 절의 서브 쿼리도 지원합니다.
서브 쿼리 사용 예를 살펴봅시다.
다음은 나이가 평균보다 많은 회원을 찾습니다.
select m from Member m
where m.age > (select avg(m2.age) from Member m2)다음은 한 건이라도 주문한 고객을 찾습니다.
select m from Member m
where (select count(o) from Order o where m = o.member) > 0참고로 이 쿼리는 다음처럼 컬렉션 값 연관 필드의 size 기능을 사용해도 같은 결과를 얻을 수 있습니다.
(실행되는 SQL도 같습니다.)
select m from Member m
where m.orders.size > 0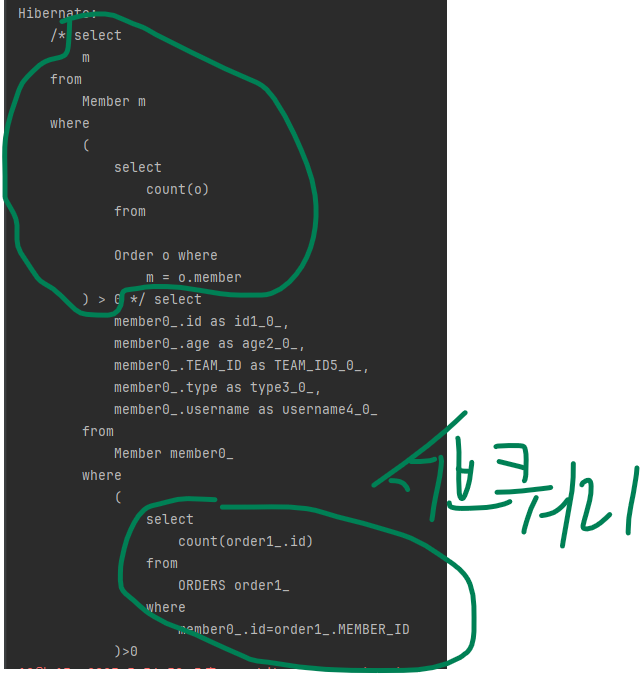
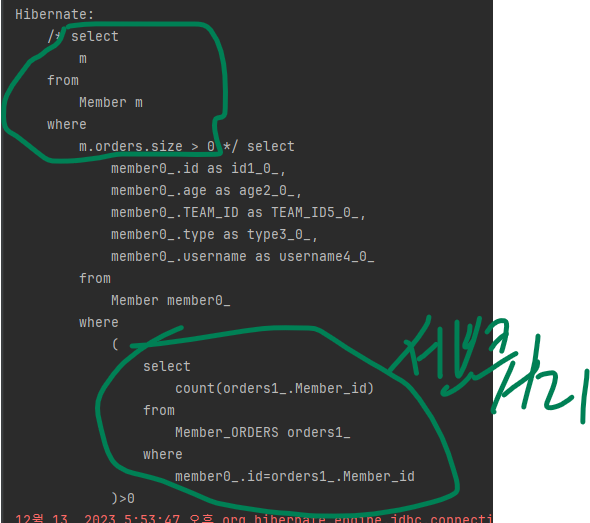
실행 결과가 위처럼 같습니다.
서브 쿼리 함수
서브 쿼리는 다음 함수들과 같이 사용할 수 있습니다.
[NOT] EXISTS (subquery){ALL | ANY | SOME} (subquery)[NOT] IN (subquery)
EXISTS
- 문법 :
[NOT] EXITST (subquery) - 설명 : 서브쿼리에 결과가 존재하면 참입니다. NOT은 반대입니다.
- 예) 팀 A 소속인 회원
select m from Member m where exists (select t from m.team t where t.name = '팀A')
{ALL | ANY | SOME}
문법 : { ALL | ANY | SOME } (subquery)
설명 : 비교 연산자와 같이 사용합니다. `{= | > | >= | < | <= | <>}
- ALL : 조건을 모두 만족하면 참입니다.
- ANY 혹은 SOME : 둘은 같은 의미입니다. 조건을 하나라도 만족하면 참입니다.
- 예) 전체 상품 각각의 재고보다 주문량이 많은 주문들
select o from Order o where o.orderAmount > ALL (select p.stockAmount from Product p)- 예) 어떤 팀이든 팀에 소속된 회원
select m from Member m where m.team = ANY (select t from Team t)
IN
- 문법 : `[NOT] IN (subquery)
- 설명 : 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참입니다. 참고로 IN은 서브쿼리가 아닌 곳에서도 사용됩니다.
- 예)
select t from Team t
where t IN (select t2 From Team t2 JOIN t2.members m2 where m2.age >= 20)조건식
타입 표현
JPQL에서 사용하는 타입은 다음 표와 같이 표시됩니다.
대소문자는 구분하지 않습니다.
| 문자 | 설명 | 예제 |
|---|---|---|
| 문자 | 작은 따옴표 사이에 표현 작은 따옴표를 표현하고 싶으면 작은 따옴표 연속 두 개('')를 사용합니다. |
'HELLO' 'She''s' |
| 숫자 | L(Long 타입 지정) D(Double 타입 지정) F(Float 타입 지정) |
10L 10D 10F |
| 날짜 | DATE{d 'yyyy-mm-dd'} TIME {t 'hh-mm-ss'} DATETIME{ts 'yyyy-mm-dd hh:mm:ss.f'} |
{d '2012-03-24'} {t '10-11-11'} {ts '2012-03-24 10-11-11,123'} m.createDate = {d '2012-03-24'} |
| Boolean | TRUE, FALSE | . |
| Enum | 패키지명을 포함한 전체 이름을 사용해야 합니다. | jpabook.MemberType.Admin |
| 엔티티 타입 | 엔티티의 타입을 표현합니다. 주로 상속과 관련해서 사용합니다. | TYPE(m) = Member |
연산자 우선순위
연산자 우선 순위는 다음과 같습니다.
- 경로 탐색 연산(.)
- 수학 연산: +, -(단항 연산자), *, /, +, -
- 비교 연산: =, >ㅡ >=, <, <=, <>(다름),
[NOT] BETWEEN,[NOT] LIKE,[NOT] IN,IS [NOT] EMPTY,[NOT] MEMBER [OF],[NOT] EXITSTS - 논리 연산 : NOT, AND, OR
논리 연산과 비교식
- 논리 연산
- AND : 둘 다 만족하면 참
- OR : 둘 중 하나만 만족해도 참
- NOT : 조건식의 결과 반대
- 비교식
- 비교식은 다음과 같습니다.
- = | > | >= | < | <= | <>
Between, IN, Like, NULL 비교
Between 식
- 문법 :
X [NOT] BETWEEN A AND B - 설명 : X는 A ~ B 사이의 값이면 참(A,B 값 포함)
- 예) 나이가 10~20인 회원을 찾으시오
select m from Member m where m.age between 10 and 20- 문법 :
IN 식
- 문법 :
X [NOT] IN (예제) - 설명 : X와 같은 값이 예제에 하나라도 있으면 참입니다. IN 식의 예제에는 서브 쿼리를 사용할 수 있습니다.
- 예) 이름이 회원1이나 회원2인 회원을 찾으시오.
select m from Member m where m.username in ('회원1', '회원2')- 문법 :
Like 식
- 문법 :
문자표현식 [NOT] LIKE 패턴값 [ESCAPE 이스케이프문자] - 설명 : 문자표현식과 패턴값을 비교합니다.
%(퍼센트) : 아무 값들이 입력되어도 됩니다(값이 없어도 됩니다.)_(언더라인) : 한 글자는 아무 값이 입력되어도 되지만 값이 있어야 합니다.
- 문법 :
다음 예는 Like 식을 사용하는 예입니다.
// 중간에 원이라는 단어가 들어간 회원(좋은 회원, 회원, 원)
select m from Member m
where m.username like '%원'
// 처음에 회원이라는 단어가 포함(회원1, 회원 ABC)
where m.username like '회원%'
// 마지막에 회원이라는 단어가 포함(좋은 회원, A회원)
where m.username like '%회원'
// 회원A, 회원1
where m.username like '회원_'
// 회원 3
where m.username like '__3'
// 회원%
where m.username like '회원\%' ESCAPE '\'NULL 비교식
- 문법 : `{단일값 경로 | 입력 파라미터 } IS [NOT] NULL
- 설명 : *NULL인지 비교\합니다. **NULL은 = 으로 비교하면 안 되고 꼭
IS NULL을 사용해야 합니다. - 예
where m.username is null where null = null // 거짓 where 1=1 // 참
컬렉션 식
컬렉션 식은 컬렉션에만 사용하는 특별한 기능입니다.
참고로 컬렉션은 컬렉션 식 이외에 다른 식은 사용할 수 없습니다.
- 빈 컬렉션 비교 식
- 문법 :
{컬렉션 값 연관 경로} IS [NOT] EMPTY - 설명 : 컬렉션에 값이 비었으면 참
- 문법 :
다음 예는 빈 컬렉션을 비교하는 예입니다.
// JPQL : 주문이 하나라도 있는 회원을 조회합니다.
select m from Member m
where m.orders is not empty다음은 실행 결과입니다.
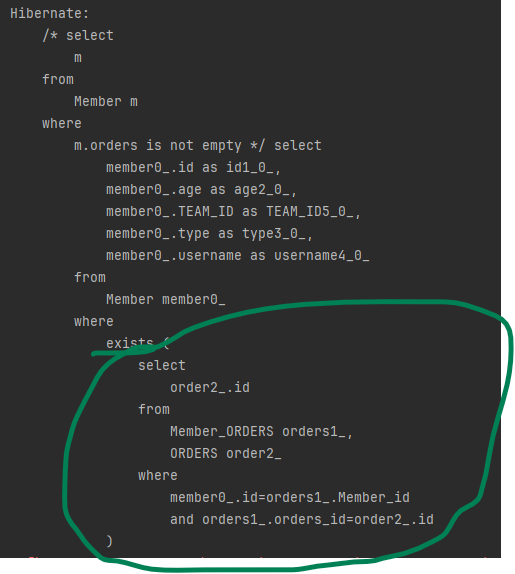
컬렉션은 컬렉션 식만 사용할 수 있다는 점에 주의해야 합니다.
다음은 is null처럼 컬렉션 식이 아닌 것은 사용할 수 없습니다.
select m from Member m
where m.orders is null(오류!)


컬렉션의 멤버 식
- 문법 :
{엔티티나 값} [NOT] MEMBER [OF] {컬렉션 값 연관 경로} - 설명 : 엔티티나 값이 컬렉션에 포함되어 있으면 참입니다.
- 예)
select t from Team t where :memberParam member of t.members- 문법 :
스칼라 식
스칼라는 숫자, 문자, 날짜, case, 엔티티 타입(엔티티의 타입 정보) 같은 가장 기본적인 타입들을 말한다. 스칼라 타입에 사용하는 식을 알아봅시다.
수학식
- +, - : 단항 연산자
- *, /, +, - : 사칙 연산
문자함수
다음 표를 보겟습니다.
| 함수 | 설명 | 예제 |
| --------------------------------------------- | --------------------------------------------------------------------------------------- | ------------------------------- | -------------------------------------------------------------------------------------------------------------------------------- | --------------------- |
| CONCAT(문자1, 문자2, ...) | 문자를 합합니다. | CONCAT('A','B') = AB |
| SUBSTRING(문자, 위치, [길이]) | 위치부터 시작해 길이만큼 문자를 구합니다. 길이 값이 없으면 나머지 전체 길이를 뜻합니다. | SUBSTRING('ABCDEF', 2, 3) = BCD |
| TRIP([[LEADING | TRAILING | BOTH] [트림 문자] FROM] 문자) | LEADING: 왼쪽만 TRAILING: 오른쪽만 BOTH: 양쪽 다 트림 문자를 제거합니다. 기본값은 BOTH, 트림 문자의 기본 값은 공백(SPACE)입니다. | TRIP(' ABC ') = 'ABC' |
| LOWER(문자) | 소문자로 변경 | LOWER('ABC') = 'abc' |
| UPPER(문자) | 대문자로 변경 | UPPER('abc') = 'ABC |
| LENGTH(문자) | 문자 길이 | LENGTH('ABC') = 3 |
| LOCATE(찾을 문자, 원본 문자, [검색시작위치] | 검색위치부터 문자를 검색합니다. 1부터 시작하고, 못 찾으면 0을 반환합니다. | LOCATE('DE', 'ABCDEFG') = 4 |
|참고로 HQL은 CONCAT 대신에 ||도 사용할 수 있습니다.
- 수학함수
다음 표를 보시면 됩니다.
| 함수 | 설명 | 예제 |
|---|---|---|
| ABS(수학식) | 절대값을 구합니다. | ABS(-10) = 10 |
| SQRT(수학식 | 제곱근을 구합니다. | SQRT(4) = 2.0 |
| MOD(수학식, 나눌 수) | 나머지를 구합니다. | MOD(4,3) = 1 |
| SIZE(컬렉션 값 연관 경로식) | 컬렉션의 크기를 구합니다. | SIZE(t.members) |
| INDEX(별칭) | LIST 타입 컬렉션의 위치값을 구합니다. 단 컬렉션이 @OrderColumn을 사용하는 LIST 타입일 때만 사용할 수 있습니다. | t.members , where INDEX(m) > 3 |
날짜 함수
날짜함수는 데이터베이스의 현재 시간을 조회합니다.CURRENT_DATE : 현재 날짜
CURRENT_TIME : 현재 시간
CURRENT)TIMESTAMP : 현재 날짜 시간
예)
select CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP from Team t예) 종료 이벤트 조회
select e from Event e where e.endDate < CURRENTS_DATE하이버네이트는 날짜 타입에서 년, 월, 일, 시간 분, 초 값을 구하는 기능을 지원합니다.
YEAR, MONTH, DAY, HOUR, MINUTE, SECOND예)
select year(CURRENT_TIMESTAM), month(CURRENT_TIMESTAEMP), day(CURRENT_TIMESTAMP)
from Member데이터베이스들은 각자의 방식으로 더 많은 날짜 함수를 지원합니다.
그리고 각각의 날짜 함수는 하이버네이트가 제공하는 데이터베이스 방언에 등록되어 있습니다.
예를 들어 오라클 방언을 사용하면 to_date, to_char 함수를 사용할 수 있습니다.
믈론 다른 데이터베이스를 사용하면 동작하지 않습니다.
CASE 식
특정 조건에 따라 분기할 때 CASE식을 사용합니다. CASE 식은 4가지 종류가 있습니다.
- 기본 CASE
- 심플 CASE
- COALESCE
- NULLIF
기본 CASE
문법
CASE {WHEN <조건식> THEN <스칼라식>} + ELSE <스칼라식> END예)
select case when m.age <= 10 than '학생요금' when m.age >= 60 than '경로요금' else '일반요금' end from Member m
심플 CASE
심플 CASE는 조건식을 사용할 수 없지만, 문법이 단순합니다.
참고로 자바의 switch case문과 비슷합니다.
문법
CASE <조건대상> {WHEN <스칼라식1> THEN <스칼라식2>} + ELSE <스칼라식> END예)
select case t.name when '팀A' then '인센티브110%' when '팀B' then '인센티브120%' else '인센티브105%' end from Team t
참고
표준 명세의 문법 정의는 다음과 같습니다.
- 기본 CASE식 ::=
CASE when_절 {when_절}* ELSE 스칼라식 END
when_절::= WHEN 조건식 THEN 스칼라식- 심플 CASE 식 ::=
CASE case_피연산자 심플_when_절 {심플_when_절}* ELSE 스칼라식 END
case_피연산자 ::= 상태 필드 경로식 | 타입 구분자
심플_when_절::= WHEN 스칼라식 THEN 스칼라식COALESCE
- 문법 :
COALESCE(<스칼라식> {, <스칼라식>}+) - 설명 : 스칼라식을 차례대로 조회해서 null이 아니면 반환합니다.
예)
m.username이 null이면 '이름 없는 회원'을 반환합니다.select coalesce(m.username,'이름 없는 회원') from Member m- 문법 :
NULLIF
- 문법 :
NULLIF(<스칼라식>, <스칼라식>) - 설명 : 두 값이 같으면 null을 반환하고 다르면 첫 번째 값을 반환합니다. 집함 함수는 null을 포함하지 않으므로 보통 집합 함수와 함께 사용합니다.
예) 사용자 이름이 '관리자'면 null을 반환하고 나머지는 본인의 이름을 반환하세요
select NULLIF(m.username, '관리자') from Member m- 문법 :
다형성 쿼리
JPQL로 부모 엔티티를 조회하면 그 자식 엔티티도 함꼐 조회됩니다.
다음 예를 보면 Item의 자식으로 Book, Album, Movie가 있습니다.
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn // 기본값 DTYPE
public abstract class Item {
@Id @GeneratedValue
private Long id;
}
@Entity
@DiscriminatorValue("B")
public class Book extends Item {
private String author;
}
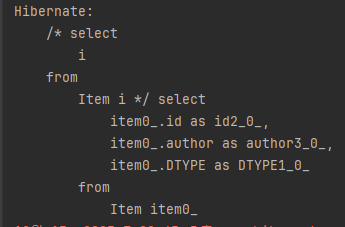
// Album, Movie 생략다음과 같이 조회하면 Item의 자식도 함께 조회됩니다.
String query = "select i from Item i";
List resultList = em.createQuery(query)
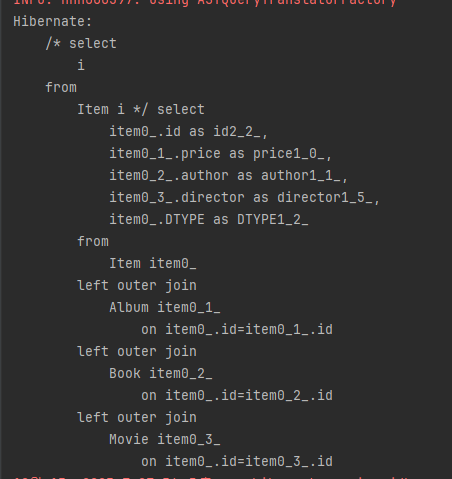
.getResultList();다음은 단일 테이블 전략(InheritanceType.SINGLE_TABLE)을 사용할 때의 실행 결과입니다.
조인 전략(InheritanceType.JOINED)을 사용할 때 실행되는 SQL은 다음과 같습니다.
TYPE
TYPE은 엔티티의 상속 구조에서 조회 대상을 특정 자식 타입으로 한정할 때 주로 사용합니다.
// 예 Item 중에 Book, Movie를 조회하세요
// JPQL
select i from Item i
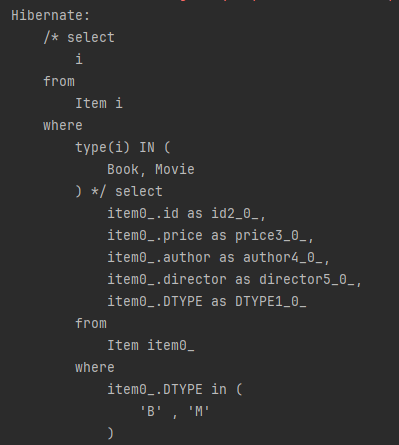
where type(i) IN (Book, Movie)다음은 실행 결과 입니다.
싱글테이블 전략 결과입니다.
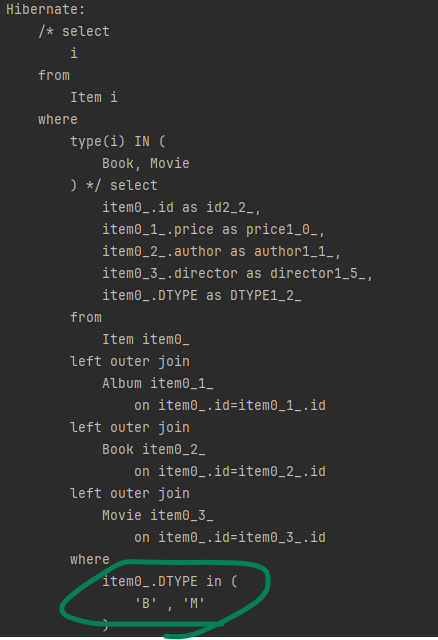
JOINED 전략 결과입니다.
TREAT(JPA 2.1)
TREAT은 JPA 2.1에 추가된 기능인데 자바의 타입 캐스팅과 비슷합니다.
상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용합니다.
JPA 표준은 FROM, WHERE 절에서 사용할 수 있지만, 하이버네이트는 SELECT 절에서도 TREAT을 사용할 수 있습니다.
// 예 : 부모인 Item과 자식 Book이 있습니다.
// JPQL
select i from Item i where treat(i as Book).author = 'kim'다음은 실행 결과입니다.
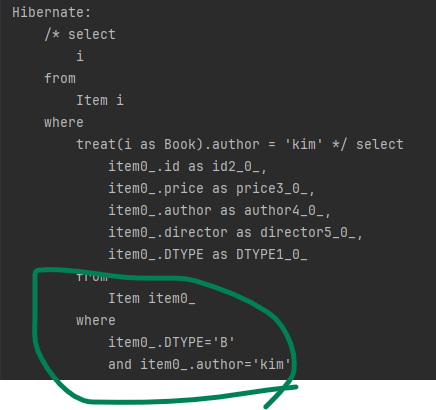
JPQL을 보면 treat을 사용해서 부모 타입인 Item을 자식 타입인 Book으로 다룹니다.
따라서 author 필드에 접근할 수 있습니다.
사용자 정의 함수 호출(JPA 2.1)
JPA 2.1부터 사용자 정의 함수를 지원합니다.
- 문법 : function_invocation::= FUNCTION(function_name (, frunction_arg)*)
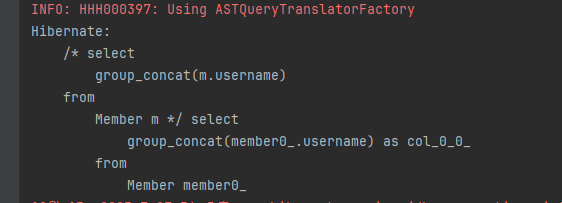
- 예 : select runction('group_concat', i.name) from Item i
하이버네이트 구현체를 사용하면 다음 예시와 같이 방언 클래스를 상속해서 구현하고 사용할 데이터베이스 함수를 미리 등록해야 합니다.
public class MyH2Dialect extends H2Dialect {
public MyH2Dialect() {
registerFunction("group_concat", new StandardSQLFunction("group_concat", StandardBasicTypes.STRING));
}
}참고로 다음은 H2Dialect.class인데, JPA에서 여러 가지 함수들을 제공합니다.
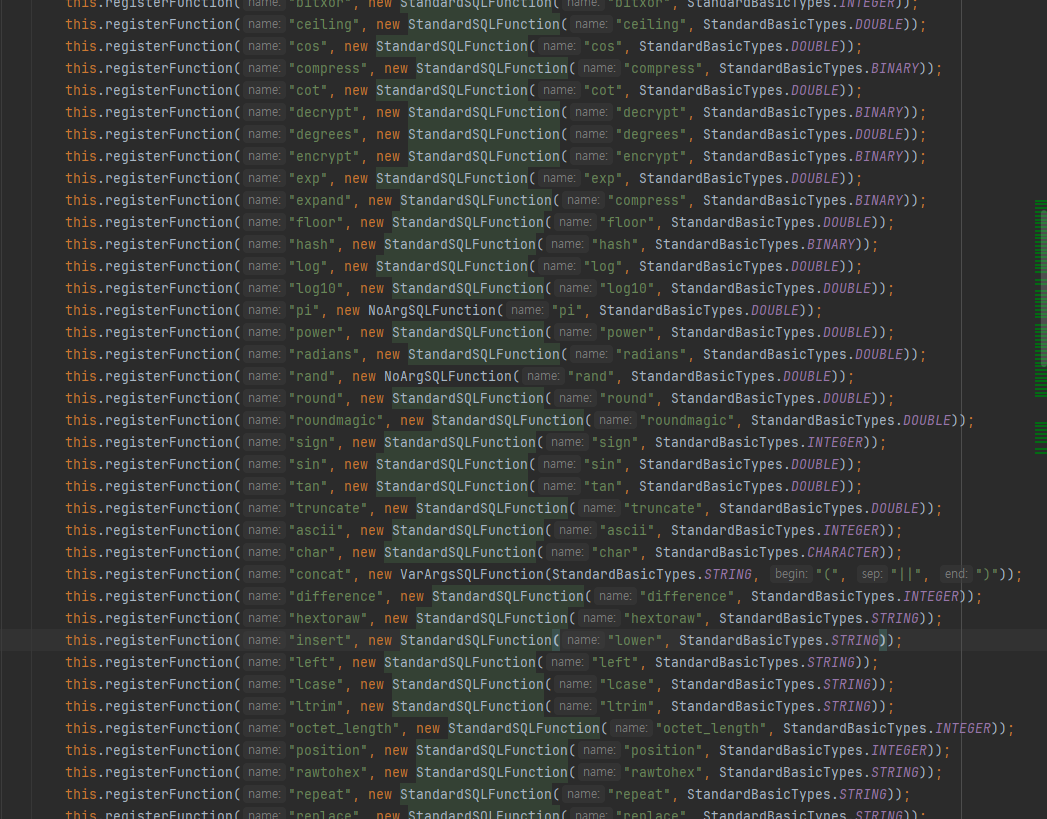
하이버네이트 구현체를 사용하면 다음과 같이 축약해서 사용할 수 있습니다.
select group_concat(m.username) from Member m다음은 실행결과입니다.
기타 정리
- enum은
=비교 연산만 지원합니다. - 임베디드 타입은 비교를 지원하지 않습니다.
EMPTH STRING
JPA 표준은 ''을 길이 0인 Empty String으로 정했지만 데이터베이스에 따라 ''를 NULL로 사용하는 데이터베이스도 있으므로 확인하고 사용해야 합니다.
NULL 정의
- 조건을 만족하는 데이터가 하나도 없으면 NULL입니다.
- NULL은 알 수 없는 값(unknown value)입니다. NULL과의 모든 수학적 계산 결과는 NULL이 됩니다.
- Null == Null은 알 수 없는 값이다.
- Null is Null은 참이다.
JPA 표준 명세는 Null(U) 값과 TRUE(T), FALSE(F)의 논리 계산을 다음과 같이 정의했다.
다음 표는 AND 연산을 정리했습니다.
| AND | T | F | U |
|---|---|---|---|
| T | T | F | U |
| F | F | F | F |
| U | U | F | U |
다음 표는 OR 연산을 정리한 것입니다.
| OR | T | F | U |
|---|---|---|---|
| T | T | T | T |
| F | T | F | U |
| U | T | U | U |
다음 표는 NOT 연산을 정리한 것입니다.
| NOT | --- |
|---|---|
| T | F |
| F | T |
| U | U |
엔티티 직접 사용
기본 키 값
객체 인스턴스는 참조 값으로 식별하고, 테이블 로우는 기본 키 값으로 식별합니다.
따라서 JPQL에서 엔티티 객체를 직접 사용하면 SQL에서는 해당 엔티티의 기본 키 값을 사용합니다. 다음 JPQL예제를 확인해봅시다.
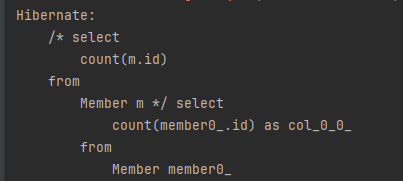
select count(m.id) from Member m // 엔티티의 아이디를 사용
select count(m) from Member m // 엔티티를 직접 사용두 번째의 count(m)을 보면 엔티티의 별칭을 직접 넘겨주었습니다.
이렇게 엔티티를 직접 사용하면 JPQL이 SQL로 변환될 때 해당 엔티티의기본 키를 사용합니다. 따라서 다음 실제 실행된 SQL은 둘 다 같습니다.
위의 코드 실행 결과입니다.
아래 코드의 실행 결과입니다.
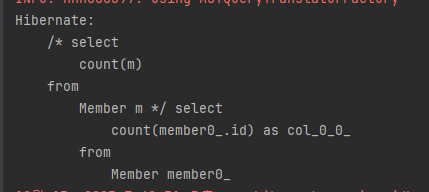
JPQL의 count(m)이 SQL에서 count(m.id)로 변환된 것을 확인할 수 있습니다.
이번에는 다음 예시와 같이 엔티티를 파라미터로 직접 받아보겠습니다.
String query = "select m from Member m where m = :member";
List resultList = em.createQuery(query)
.setParameter("member", member1)
.getResultList();다음은 실행 결과입니다.
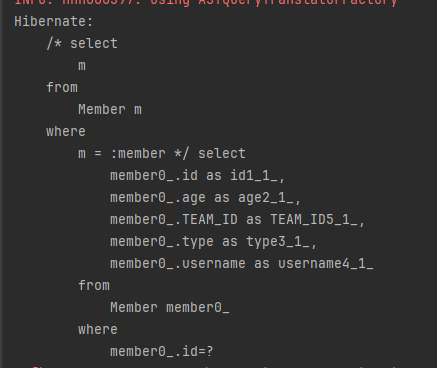
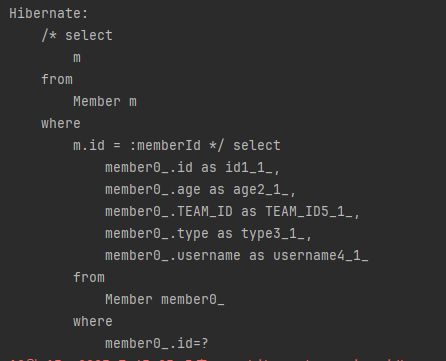
JPQL과 SQL을 비교해보면 JPQL에서 where m = :member로 엔티티를 직접 사용하는 부분이 SQL에서 where m.id-?로 기본 키 값을 사용하도록 변환된 것을 확인할 수 있습니다.
다음과 같이 식별자 값을 직접 사용해도 결과는 같습니다.
String query = "select m from Member m where m.id = :memberId";
List resultList = em.createQuery(query)
.setParameter("memberId", 1L)
.getResultList();다음은 실행 결과입니다.
외래키 값
이번에는 외래 키를 사용하는 예를 보겠습니다.
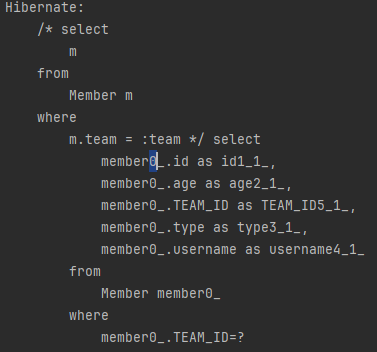
다음 예시는 특정 팀에 소속된 회원을 찾는 예입니다.
Team findteam = em.find(Team.class, 1L);
String query = "select m from Member m where m.team = :team";
List resultList = em.createQuery(query)
.setParameter("team", findteam)
.getResultList();기본 키 값이 1L인 팀 엔티티를 파라미터로 사용하고 있습니다.
m.team은 형재 team_id라는 외래 키와 매핑되어 있습니다.
따라서 다음과 같은 SQL이 실행됩니다.
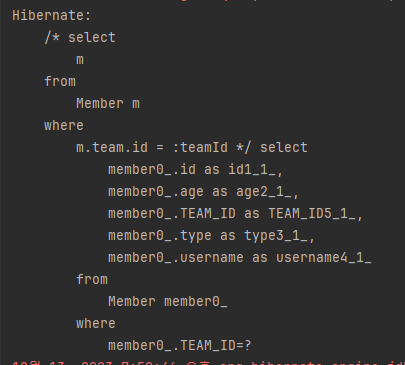
엔티티 대신 다음과 같이 식별자 값을 직접 사용할 수도 있습니다.
String query = "select m from Member m where m.team.id = :teamId";
List resultList = em.createQuery(query)
.setParameter("teamId", 1L)
.getResultList();예제에서 m.team.id를 보면 Member와 Team 간에 묵시적 조인이 일어날 것 같지만 MEMBER 테이블이 team_id 외래 키를 가지고 있으므로 묵시적 조인은 일어나지 않습니다. 물론 m.team.name을 호출하면 묵시적 조인이 일어납니다.
따라서 m.team을 사용하든 m.team.id를 사용하든 생성되는 SQL은 다음과 같습니다.
Named 쿼리: 정적 쿼리
JPQL 쿼리는 크게 동적 쿼리와 정적 쿼리로 나눌 수 있습니다.
- 동적 쿼리:
em.createQuery("select ..")처럼 JPQL을 문자로 완성해서 직접 넘기는 것을 동적 쿼리라 합니다. 런타임에 특정 조건에 따라 JPQL을 동적으로 구성할 수 있습니다. - 정적 쿼리 : 미리 정의한 쿼리에 이름을 부여해서 필요할 때 사용할 수 있는데 이것을 Named 쿼리라고 합니다. Named 쿼리는 한 번 정의하면 변경할 수 없는 정적인 쿼리입니다.
Named 쿼리는 애플리케이션 로딩 시점에 JPQL 문법을 체크하고 미리 파싱해둡니다.
따라서 오류를 빨리 확인할 수 있고, 사용하는 시점에 파싱된 결과를 재사용하므로 성능상 이점도 있습니다. 그리고 Named 쿼리는 변하지 않는 정적 SQL이 생성되므로 데이터베이스의 조회 성능 최적화에도 도움이 됩니다.
Named 쿼리는 @NamedQuery 어노태이션을 사용해서 자바 코드에 작성하거나 또는 XML 문서에 작성할 수 있습니다.
Named 쿼리를 어노테이션에 정의
Named 쿼리는 이름 그대로 쿼리에 이름을 부여해서 사용하는 방법입니다.@NamedQuery 어노테이션을 사용하는 예를 보겠습니다.
@Entity
@NamedQuery ()
name = "Member.findByUsername",
query = "select m from Member m where m.username = :username")
public class Member {
...
}@NamedQuery.name에 쿼리를 부여하고 @NamedQuery.query에 사용할 쿼리를 입력했습니다.
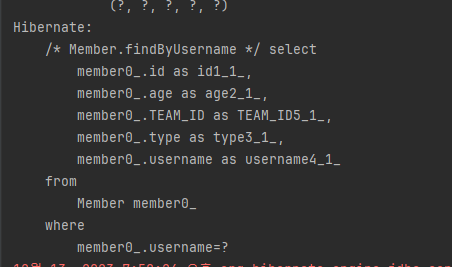
사용 예시입니다.
List<Member> resultList = em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "회원1")
.getResultList();다음은 실행 결과입니다.
Named 쿼리를 사용할 때는 예시와 같이 em.createNamedQuery() 메소드에 Named 쿼리 이름을 입력하면 됩니다.
참고
Named 쿼리 이름을 간단히 findByUsername이라 하지 않고 Member.findByUsername처럼 앞에 엔티티 이름을 주었는데 이것이 기능적으로 특별한 의미가 있는 것은 아닙니다. 하지만 Named 쿼리는 영속성 유닛 단위로 관리되므로 충돌을 방지하기 위해 엔티티 이름을 앞에 주었습니다.
그리고 엔티티 이름이 앞에 있으면 관리하기가 쉽습니다.
하나의 엔티티에 2개 이상의 Named 쿼리를 정의하려면 다음과 같이 @NamedQueries 어노테이션을 사용하면 됩니다.
@Entity
@NamedQueries({
@NamedQuery(
name = "Member.findByUsername",
query = "select m from Member m where m.username = :username"),
@NamedQuery(
name = "Member.count",
query = "select count(m) from Member m")
})
public class Member {...}다음은 @NamedQuery 어노테이션 입니다.
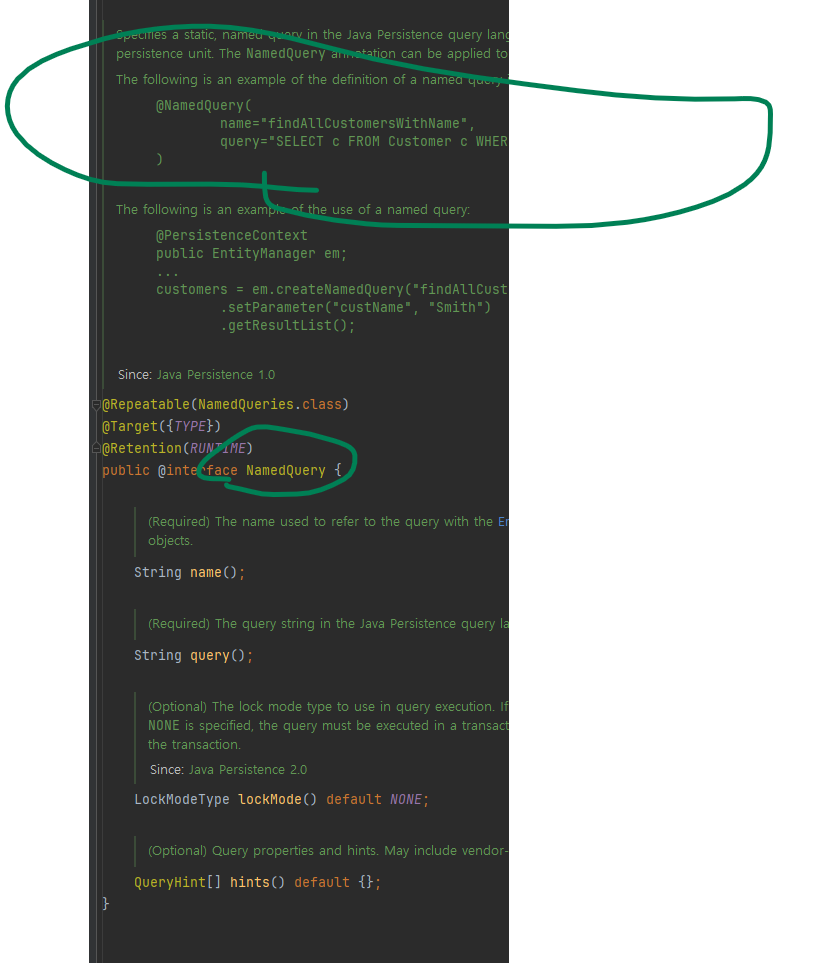
사용법도 알려주고 있습니다.
- lockMode : 쿼리 실행 시 락을 겁니다. 락에 대한 내용은 책 후반부에서 다루고 있습니다.
- hints : 여기서 힌트는 SQL 힌트가 아니라 JPA 구현체에게 제공하는 힌트입니다. 예를 들어 2차 캐시를 다룰 때 사용합니다.
Named 쿼리를 XML에 정의
JPA에서 어노테이션으로 작성할 수 있는 것은 XML로도 작성할 수 있습니다. 물론 어노테이션을 사용하는 것이 직관적이고 편리합니다. 하지만 Named 쿼리를 작성할 때는 XML을 사용하는 것이 더 편리합니다.
자바 언어로 멀티라인 문자를 다루는 것은 상당히 귀찮은 일입니다.
(어노테이션을 사용해도 마찬가지입니다.)

흠.. 좀 귀찮습니다...
자바에서 이런 불편함을 해결하기 위해 다음과 같이 XML을 사용하는 것이 불편함을 해소할 수 있을 거 같습니다.
다음과 같이 작성해주면 됩니다.
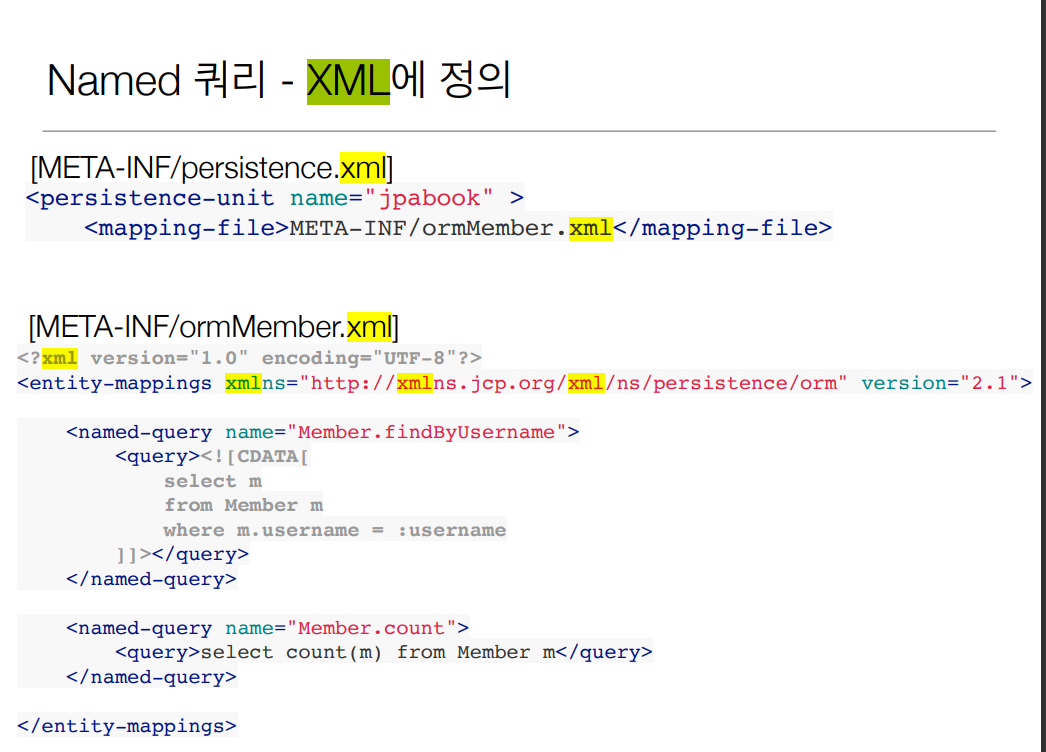
참고
XML에서 &, <, >는 XML 예약문자입니다. 대신에 &, <, >를 사용해야 합니다. <![CDATA[ ]]>를 사용하면 그 사이에 문장을 그대로 출력하므로 예약문자도 사용할 수 있습니다.
그리고 정의한 ormMember.xml을 인식하도록 META-INF/persistence.xml에도 그림에서 보이는 바와 같이 추가해줘야합니다.
참고
META-INF/orm.xml은 JPA가 기본 매핑파일로 인식해서 별도의 설정을 하지 않아도 됩니다. 이름이나 위치가 다르면 설정을 추가해야 합니다. 예제에서는 매핑 파일 이름이 ormMember.xml이므로 persistence.xml에 설정 정보를 추가했습니다.
환경에 따른 설정
만약 XML과 어노테이션에 같은 설정이 있으면 XML이 우선권을 가집니다. 예를 들어 같은 이름의 Named 쿼리가 있으면 XML에 정의한 것이 사용됩니다. 따라서 애플리케이션 운영 환경에 따라 다른 쿼리를 실행해야 한다면 각 환경에 맞춘 XML을 준비해 두고 XML만 변경해서 배포하면 됩니다.
2-3. 객체지향 쿼리 심화(일부)
| 참고로 해당 파트 중에는 벌크 연산에 대해서만 다룹니다.
벌크 연산
엔티티를 수정하려면 영속성 컨텍스트의 변경 감지 기능이나 병합을 사용하고, 삭제하려면 EntityManager.remove() 메서드를 사용합니다.
하지만 이 방법으로 수백개 이상의 엔티티를 하나씩 처리하기에는 시간이 너무 오래 걸립니다. 이럴 때 여러 건을 한 번에 수정하거나 삭제하는 벌크 연산을 사용하면 됩니다.
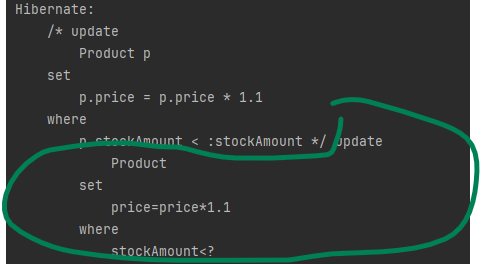
예를 들어 재고가 10개 미만인 모든 상품의 가격을 10% 상승시키려면 다음 예시와 같이 벌크 연산을 사용하면 됩니다.
String query = "update Product p " +
"set p.price = p.price \* 1.1 " +
"where p.stockAmount < :stockAmount";
int resultCount = em.createQuery(query)
.setParameter("stockAmount", 10)
.executeUpdate();
실행 결과는 다음과 같습니다.
벌크 연산은 executeUpdate()메소드를 사용합니다. 이 메소드는 벌크 연산으로 영향을 받은 엔티티 건수를 반환합니다.
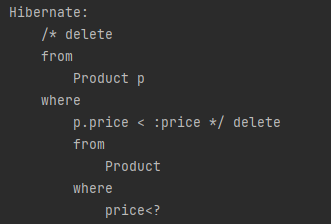
삭제도 같은 메소드를 사용합니다. 다음 예시는 가격이 100원 미만인 상품을 삭제하는 코드입니다.
String query = "delete from Product p " +
"where p.price < :price";
int resultCount = em.createQuery(query)
.setParameter("price", 10)
.executeUpdate();
다음은 실행 결과입니다.
참고
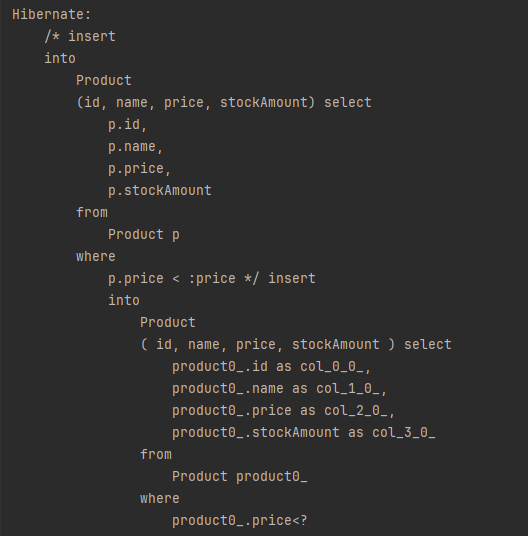
JPA 표준은 아니지만 하이버네이트는 INSERT 벌크 연산도 지원합니다. 다음 코드는 100원 미만의 모든 상품을 선택해서 Product에 저장하는 내용입니다.
String query =
"insert into Product(id, name, price, stockAmount) " +
"select p.id, p.name, p.price, p.stockAmount from Product p " +
"where p.price < :price";
em.createQuery(query)
.setParameter("price", 100)
.executeUpdate();
실행 결과입니다.
벌크 연산의 주의점
벌크 연산을 사용할 때는 벌크 연산이 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리한다는 점에 주의해야 하는데요.
벌크 연산시 어떤 문제가 발생할 수 있는지 다음 예를 통해 알아보겠습니다.
데이터베이스에는 가격이 1000원인 상품 A(productA)가 있습니다.
Product productA = new Product("productA", 1000, 1);
em.persist(productA);
// 상품A 조회(상품 A의 가격은 1000원이다.) ---- ①
Product findProductA = em.createQuery("select p from Product p where p.name = :name", Product.class)
.setParameter("name", "productA")
.getSingleResult();
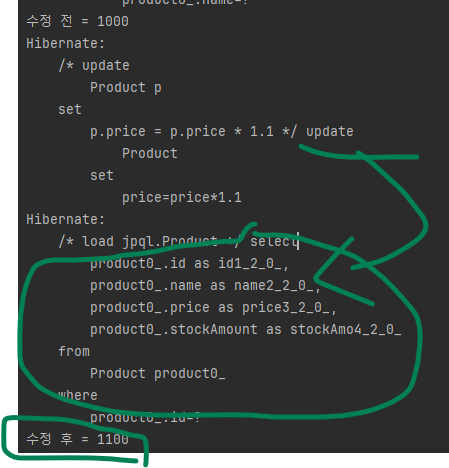
System.out.println("수정 전 = " + productA.getPrice());
// 출력 결과 : 수정 전 = 1000
// 벌크 연산 수행으로 모든 상품 가격 10% 상승 ---- ②
em.createQuery("update Product p set p.price = p.price \* 1.1")
.executeUpdate();
// 출력 결과 : 수정 후 = 1000 ---- ③
System.out.println("수정 후 = " + productA.getPrice());
다음은 실행 결과입니다.
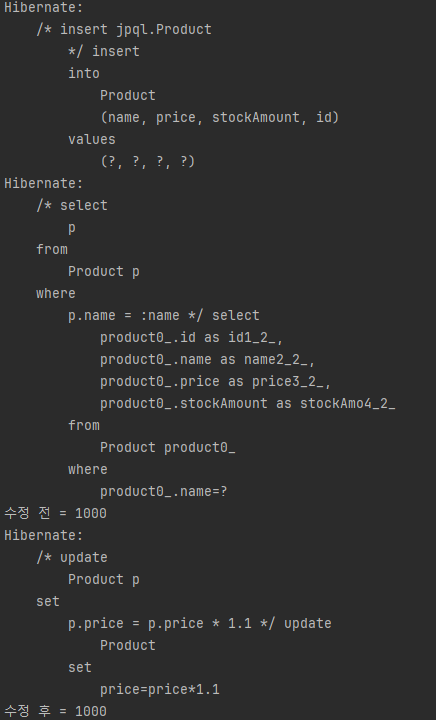
update 쿼리문이 나가더라도 그대로 1000원인 것을 알 수 있습니다.
① : 가격이 1000원인 상품A를 조회했습니다. 조회된 상품A는 영속성 컨텍스트에 관리됩니다.
② : 벌크 연산으로 모든 상품의 가격을 10% 상승시켰다. 따라서 상품A의 가격은 1100원이 되어야 합니다.
③ : 벌크 연산을 수행한 후에 상품A 의 가격을 출력하면 기대했던 1100원이 아니라 1000원이 출력됩니다.
상황을 그림으로 보겠습니다.
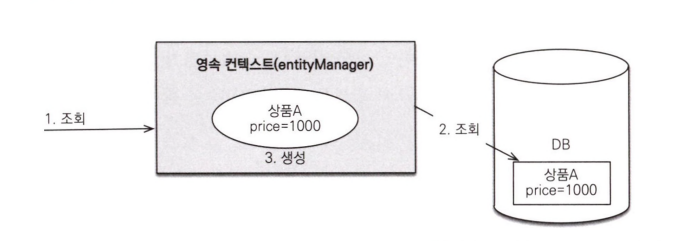
위 그림은 벌크 연산 직전의 상황을 나타냅니다. 상품 A를 조회했으므로 가격이 1000원인 상품A가 영속성 컨텍스트에 관리됩니다.
다음 그림을 보겠습니다.
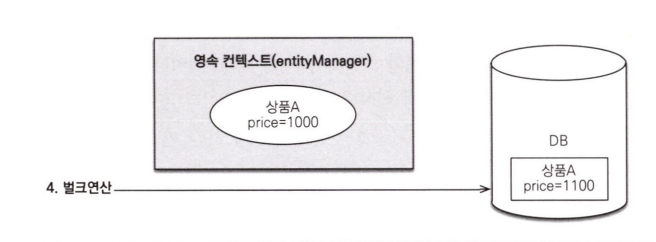
벌크 연산은 영속성 컨텍스트를 통하지 않고 데이터베이스에 직접 쿼리합니다. 따라서 영속성 컨텍스트에 있는 상품A와 데이터베이스에 있는 상품A의 가격이 다를 수 있습니다. 따라서 벌크 연산은 주의해서 사용해야 합니다.
이런 문제를 해결하는 다양한 방법이 있습니다.
em.refresh() 사용
벌크 연산을 수행한 직후에 정확한 상품A 엔티티를 사용해야 한다면 em.refresh()를 사용해서 데이터베이스에서 상품A를 다시 조회하면 됩니다.
em.refresh(productA); // 데이터베이스에 상품A를 다시 조회합니다.
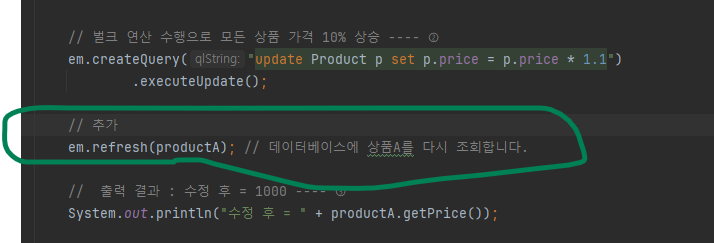
위처럼 코드를 추가하면 다음과 같은 실행결과가 나옵니다.
벌크 연산 먼저 실행
가장 실용적인 해결책은 벌크 연산을 가장 먼저 실행하는 것입니다.
예를 들어 위에서 벌크 연산을 먼저 실행하고 나서 상품A를 조회하면 벌크 연산으로 이미 변경된 상품A를 조회하게 됩니다.
이 방법은 JPA와 JDBC를 함께 사용할 때도 유용합니다.
벌크 연산 수행 후 영속성 컨텍스트 초기화
벌크 연산을 수행한 직후에 바로 영속성 컨텍스트를 초기화해서 영속성 컨텍스트에 남아 있는 엔티티를 제거하는 것도 좋은 방법입니다. 그렇지 않으면 엔티티를 조회할 때 영속성 컨텍스트에 남아 있는 엔티티를 조회할 수 있는데 이 엔티티에는 벌크 연산이 적용되어 있지 않습니다. 영속성 컨텍스트를 초기화하면 이후 엔티티를 조회할 때 벌크 연산이 적용된 데이터베이스에서 엔티티를 조회합니다.
벌크 연산은 영속성 컨텍스트와 2차 캐시를 무시하고 데이터베이스에 직접 실행합니다. 따라서 영속성 컨텍스트와 데이터베이스 간에 데이터 차이가 발생할 수 있으므로 주의해서 사용해야 합니다. 가능하면 벌크 연산을 가장 먼저 수행하는 것이 좋고 상황에 따라 영속성 컨텍스트를 초기화하는 것도 필요합니다.
3. 요약
- JPQL은 SQL을 추상화해서 특정 데이터베이스 기술에 의존하지 않습니다.
- Criteria나 QueryDSL은 JPQL을 만들어주는 빌더 역할을 할 뿐이므로 핵심은 JPQL을 잘 알아야 합니다.
- JPQL은 대량의 데이터를 수정하거나 삭제하는 벌크 연산을 지원합니다.
- 그 외 JPQL의 여러 기능을 통해서 활용하는 법을 살펴보았습니다.
(나에게) 감사합니다.
'Spring Project > JPA' 카테고리의 다른 글
| 실전! 스프링 부트와 JPA 활용 2편 (0) | 2024.01.14 |
|---|---|
| 실전! 스프링 부트와 JPA 활용 1편 (0) | 2023.12.22 |
| Jpa기본 09. 값 타입(인프런 + 자바 ORM 표준 JPA 프로그래밍) (0) | 2023.12.03 |
| Jpa기본 08. 프록시와 연관관계 관리(인프런 + 자바 ORM 표준 JPA 프로그래밍) (2) | 2023.12.01 |
| Jpa기본 07. 고급 매핑(인프런 + 자바 ORM 표준 JPA 프로그래밍) (2) | 2023.11.30 |