
- 분류 전체보기 (249)

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 시작하세요 도커 & 쿠버네티스
- filewriter filereader
- 리스트
- 자바
- 도커 엔진
- LIST
- container
- 쓰레드
- Docker
- java
- 인프런
- 멀티 쓰레드
- Java IO
- 컨테이너
- java network
- 김영한
- Kubernetes
- 스레드
- 자바 입출력 스트림
- 도커
- 자료구조
- 알고리즘
- 실전 자바 고급 1편
- 동시성
- 쿠버네티스
- Collection
- java socket
- 자바 io 보조스트림
- 스레드 제어와 생명 주기
- Thread
Archives
- Today
- Total
쌩로그
처음하는 SQL과 데이터베이스 본문
반응형
목록
- 포스팅 개요
- 본론
- 후기
1. 포스팅 개요
해당 포스팅은 인프런에서 잔재미코딩 님의 SQL 기초 강의를 학습하고 정리하는 포스팅이다.
헷갈리거나, 모르거나, 모호한 것만 정리했다.
2. 본론
2-1. 자료형 중 시간 타입
DATE
- YYYY-MM-DD
TIME
- hh:mm:ss
DATETIME
- YYYY-MM-DD hh:mm:ss
TIMESTAMP
- 1970-01-01 00:00:00 부터 현재 시간까지
YEAR(n)
- n이 2라면 1970년일 때
70, 4라면1970
- n이 2라면 1970년일 때
테이블 목록 확인 명령어
SHOW TABLES;- 테이블의 컬럼 들을 알고 싶을 때
DESC 테이블_이름;- 테이블 구조수정(ALTER)
# 테이블에 새로운 컬럼 추가
ALTER TABLE [테이블명] ADD COLUMN [추가할_컬럼명] [추가할 컬럼 데이터타입]
# 테이블 컬럼 타입 변경
ALTER TABLE [테이블명] MODIFY COLUNM [변경할 컬럼명] [변경할 컬럼 타입]
# 테이블 컬럼 이름 변경
ALTER TABLE [테이블명] CHANGE COLUMN [기존 컬럼 명] [변경할 컬럼명] [변경할 컬럼 타입]
# 테이블 컬럼 삭제
ALTER TABLE [테이블명] DROP COLUMN [삭제할 컬럼 명]
2-2. DCL
※ 참고로 잘 안씀
터미널로 접속
> mysql -u 사용자이름 -p유저를 만드려면 mysql 스키마로 접속해야함
USE mysql;
# 사용자 정보를 알려면
SELECT host, user FROM user;
# 사용자 생성
# 로컬에서만 접속 가능한 사용자로 생성한다.
CREATE USER 'userid'@'localhost'
IDENTIFIED BY '비밀번호';
# 패스워드 변경
SET PASSWORD FOR 'userid'@'호스트' = '신규비밀번호';
# 사용자 삭제
DROP USER 'userid'@'호스트';
# 사용자의 권한 확인
SHOW GRANTS FRO 'userid'@'호스트';
# 로컬에서만 접속 허용
GRANT ALL on 데이터베이스.테이블 TO 'user'@'localhost';
# *.* <= 모든 데이터베이스의 모든 테이블
GRANT ALL on *.* TO 'user'@'localhost';
# 특정 권한만 허용
GRANT SELECT, UPDATE ON 데이터베이스.테이블 TO 'userid'@'호스트';
# 모든 데이터베이스, 모든 테이블에 INSERT, SELECT, UPDATE 권한 허용
GRANT INSERT, SELECT, UPDATE ON *.* TO 'userid'@'호스트';
# 사용자명과 호스트
'userid'@'호스트
호스트에 'localhost' : 로컬호스트에서의 접속만 허용
호스트에 '%' : 모든 호스트에서의 접속을 허용
# 권한 변경 후 변경 사항 적용
FLUSH PRIVILEGES;2-3. Query
(나에게 약하고 애매한 부분만 필기했다.)
FOREIGN KEY 와 HAVING
FOREIGN KEY
- DB의 제약 조건 중 하나이다.
- 데이터의 무결성을 위해 적용한다.
- 두 테이블간 관계에 있어서 데이터의 정확성을 보장하는 제약 조건
- 참조하는 테이블의 기본키가 있어야 외래키에 데이터를 넣을 수 있다.
- 없으면 못 넣는다.
- 없으면 데이터가 정확하지 않다.
- 참조하는 테이블에서 테이블의 기본키를 외래키로 가지는 데이터를 삭제할 수 없다.
- 만약 A 테이블의 'a' 를 기본키로 가지는 row 데이터를 삭제할 때 A 테이블을 참조하는 B 테이블의 외래키가 A 테이블의 기본키인 'a' 를 가진다면 지우려는 A 테이블의 'a'를 기본키로 가지는 row는 삭제할 수 없다.
- 이경우 B 테이블 데이터를 먼저 지워야 A 테이블의 row를 삭제할 수 있다.
HAVING
- 집계함수를 가지고 조건비교를 할 때 사용한다.
- HAVING 절은 GROUP BY 절과 함께 사용한다.
JOIN
- 두 개 이상의 테이블로부터 필요한 데이터를 연결해 하나의 포괄적인 구조로 결합시키는 연산
- INNER JOIN
- 두 테이블에 해당 필드값이 매칭되는 레코드만 가져온다.
- OUTER JOIN
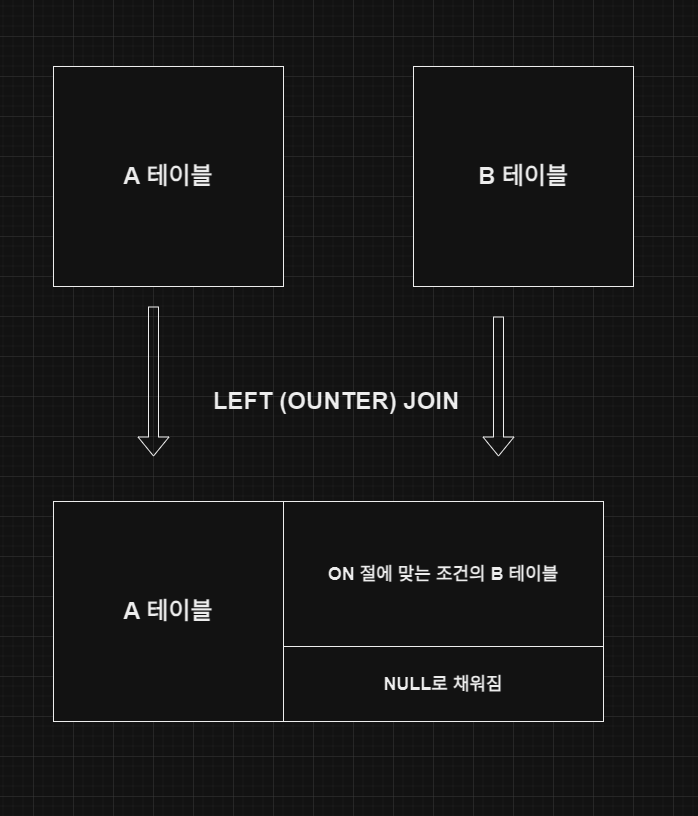
- LEFT OUTER JOIN
- 왼쪽 테이블에서 모든 레코드와 함께, 오른쪽 테이블에 왼쪽 테이블 레코드와 매칭되는 레코드를 붙여서 가져온다.
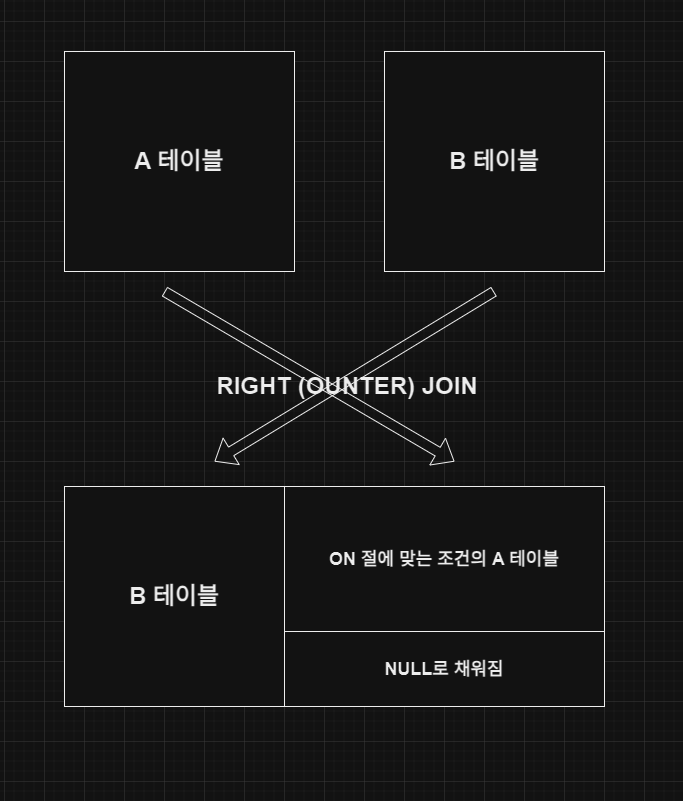
- RIGHT OUTER JOIN
- 오른쪽 테이블에서 모든 레코드와 함께, 왼쪽 테이블에 왼쪽 테이블 레코드와 매칭되는 레코드를 붙여서 가져옴.
- LEFT OUTER JOIN
LEFT OUTER JOIN
RIGHT OUTER JOIN
2중 3중 JOIN은 어떤 방식으로 이뤄질까..?
- 솔직히 2중 3중 JOIN은 좋지 않은데, 어떤 식으로 테이블들을 묶어나가는지 궁금해서 GPT한테 물어봤었다.
솔직히 지금 정리하면서 생각해보면JOIN을 정확히 몰랐고, 알아보려 하지도 않았던 거 같다. 그러다보니 이상하게 생각했었다...FROM 절의 대상이 되는 테이블과 어떤 관계를 맺어나가겠지 했는데, 그게 아니었다.부끄러운 고백을 한다..
내가 질문했다.
# 나의 질문
SQL 문에서
SELECT * FROM A
LEFT OUTER JOIN B
ON A.id = b.a_id
LEFT OUTER JOIN C
ON b.a_id = c.b_id
이렇게 했을 때 A, B의 테이블이 어떻게 되는지는 알겠는데, 그 이후 `LEFT OUTER JOIN C`에 대한 내용은 어떻게 JOIN 이 들어가는거지?# GPT의 질문
`FROM` 절에서의 JOIN 문은 순차적으로 처리됩니다. 즉,
1. **A와 B를 LEFT OUTER JOIN**
먼저 `FROM A LEFT OUTER JOIN B ON A.id = b.a_id`를 통해 A 테이블을 기준으로 B 테이블을 합칩니다.
이 때 A의 각 행에 대해 A.id = b.a_id를 만족하는 B의 행이 있으면 해당 B 행이 결합되고, 없으면 B 부분은 NULL 값으로 채워진 결과 행이 생성됩니다.
결과적으로 여기까지의 단계에서 `(A LEFT OUTER JOIN B)`라는 하나의 결과 집합이 만들어집니다. 이 결과 집합은 A 테이블의 모든 행을 포함하고, B는 조건에 맞는 행이 있으면 결합되어 있고, 없으면 해당 부분은 NULL입니다.
2. **그 이후 C 테이블과의 LEFT OUTER JOIN**
다음으로 `(A LEFT OUTER JOIN B)`라는 결과 집합에 `LEFT OUTER JOIN C ON b.a_id = c.b_id`를 적용합니다. 여기서 JOIN의 기준이 되는 테이블은 이제 A나 B 단독이 아니라 `(A LEFT OUTER JOIN B)`로 만들어진 중간 결과 집합입니다.
- 첫 번째 JOIN에서 나온 결과 집합의 각 행에 대해, `b.a_id = c.b_id` 조건을 만족하는 C 테이블의 행을 LEFT JOIN 합니다.
- 만약 해당 조건을 만족하는 C 테이블 행이 있다면 그 행이 결합되고,
- 만족하는 행이 없다면 C 부분이 NULL로 채워진 결과를 얻게 됩니다.
즉, `A LEFT OUTER JOIN B`로 형성된 중간 결과를 기준으로 다시 `C`를 LEFT JOIN 하는 개념입니다. 순서대로 보면 다음과 같이 동작합니다.
1. `(A LEFT JOIN B)` 결과 집합 생성
2. `(A LEFT JOIN B)` 결과 집합과 C를 LEFT JOIN하여 최종 결과 생성
이렇게 최종적으로는 A를 기준으로 한 행은 모두 나오며, B와 C는 각각 해당 JOIN 조건을 만족하는 행들만 매칭되고, 만족하는 행이 없을 경우 해당 테이블의 컬럼들은 NULL로 채워진 상태로 결과에 포함됩니다.그니깐 A,B 의 JOIN과 ON에 대한 결과가 만들어진 테이블과 다음 JOIN절의 연산을 한다.
그냥 수학적으로는(((A+B)+C)+D) 이런 식으로 연산된다고 생각하면 된다.
SUBQUERY
- SQL 문 안에 포함되어 있는 SQL문
- SQL 문 안에서 괄호
()를 사용해서, 서브쿼리문을 추가할 수 있다.
- SQL 문 안에서 괄호
- 테이블과 테이블간의 검색시, 검색 범위(테이블 중 필요한 부분만 먼저 가져오도록)를 좁히는 기능에 주로 사용
SUBQUERY 사용법
- JOIN은 출력 결과에 여러 테이블의 열이 필요한 경우 유용
- 대부분의 서브쿼리(Sub Query)는 JOIN문으로 처리가 가능하다.
SELECT title
FROM items
INNER JOIN ranking ON items.item_code = ranking.item_code
WHERE ranking.sub_category = '여성신발';
# SUBQUERY로 변경
SELECT title
FROM items
WHERE item_code IN (SELECT item_code FROM ranking WHERE ranking.sub_category = '여성신발');참고로 서브쿼리의 위치는 정해져있지 않다.
- 그렇다고 아무 곳이나 쓰기보다는 비교할 때나 FROM 에서 쓰는 것이 적절하다.
INDEX
- 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조
- 어떤 데이터를 인덱스로 만드느냐에 따라 방대한 데이터의 경우 성능에 큰 영향을 미칠 수 있다.
인덱스 종류
- 클러스터형 인덱스
- 영어 사전과 같은 형태로 데이터를 재정렬하여 저장한다고 생각하면 된다.
- 테이블의 데이터를 실제로 재정렬하여 디스크에 저장
- 테이블에 PRIMARY KEY로 정의한 컬럼이 있을 경우, 자동 생성
- 한 테이블당 하나의 클러스터형 인덱스만 가질 수 있다.
- 영어 사전과 같은 형태로 데이터를 재정렬하여 저장한다고 생각하면 된다.
- 보조 인덱스
- 데이터는 그대로 두고, 일반 책 뒤에 있는
<찾아보기>와 같은 형태가 만들어진다고 생각하면 된다.- 클러스터형 인덱스와는 달리 데이터를 디스크에 재정렬하지 않고, 각 데이터의 위치만 빠르게 찾을 수 있는 구조로 구성
- 보조 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다.
- 인덱스는 키-필드만 갖고 있고, 나머지 세부 테이블 컬럼 정보는 가지고 있지 않다.
- 데이터는 그대로 두고, 일반 책 뒤에 있는
인덱스 확인 명령어
SHOW INDEX FROM [테이블 이름];- primary key는 클러스터형 인덱스로 나오고,
Key_name은PRIMARY로 나온다. - 반면
Key_name이PRIMARY로 나오지 않는 것은 다 보조 인덱스이다. - 다음과 같이
UNIQUE제약 조건을 추가해도 보조 인덱스가 추가된다.
ALTER TABLE [테이블 이름] ADD CONSTRAINT [제약 조건 이름] UNIQUE ([컬럼]);인덱스 생성 명령어
CREATE INDEX [인덱스 이름] ON [테이블_이름]([컬럼]);ALTER 문으로 인덱스 생성
ALTER TABLE [테이블] ADD INDEX [인덱스 이름]([컬럼]);테이블 생성하면서 인덱스 함께 만들기
INDEX<인덱스명> (컬럼명1, 컬럼명2)UNIQUE INDEX <인덱스명> (컬럼명): 항상 유일해야 함.UNIQUE INDEX의 경우 컬럼 명은 유일한 값을 가지고 있어야 한다.
CREATE TABLE xxx (
... ,
... ,
name VARCHAR(10) UNIQUE NOT NULL,
addr CHAR(2) NOT NULL,
... ,
...
UNIQUE INDEX idx_xxx_name (name),
INDEX idx_xxx_addr(addr)
);UNIQUE를 두어 중복값을 허용하지 않도록 한다.UNIQUE INDEX ...로 생성할 수도 있고,INDEX xxx로도 생성 가능하다.- 단
UNIQUE INDEX ...로 인덱스를 생성할 때는 컬럼에UNIQUE라는 제약 조건이 있어야 한다.
인덱스 삭제
- 따로
DELETE혹은DROP명령을 지원하진 않는다. - 따라서
ALTER문으로 삭제해야 한다.
ALTER TABLE [테이블] DROP INDEX [인덱스이름]3. 후기
JOIN을 이 때까지 명쾌하게 알던 적이 없었다.
JOIN 때문에 SQL에 좀 쫄고 있었다.
알고나니 별 거 없다...
늘 그렇다..
처음엔 뭔가 낯설어서 그런지 두렵다.
알고 나면 별 거 없다..
낯설더라도 두려워하지말자 알고, 결과 보면 별거 없다...
나머지 챕터가 있긴한데, 파이썬과 관련된 챕터라 다음에 기회가 되면 듣겠다.
기초 강의지만 개인적으로는 JOIN을 제대로 알고가는 것도 참 얻은 게 많은 강의인 거 같다.
끝
728x90
'DB > RDB' 카테고리의 다른 글
| SQL select 절에서 임의의 값 지정하기 (1) | 2023.11.07 |
|---|---|
| 혼공 SQL - ch07(스토어드 프로시저) (0) | 2023.08.09 |
| 혼공 SQL - ch06(인덱스) (0) | 2023.08.09 |
| 혼공 SQL - ch05(테이블과 뷰) (0) | 2023.08.08 |
| 혼공 SQL - ch04(SQL 고호오급 문법) (0) | 2023.08.08 |
Comments