
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- Thread
- container
- 자료구조
- Docker
- 인프런
- 동시성
- 시작하세요 도커 & 쿠버네티스
- LIST
- java socket
- 자바 io 보조스트림
- 멀티 쓰레드
- 리스트
- 도커
- 실전 자바 고급 1편
- 쓰레드
- 김영한
- 자바
- Collection
- 도커 엔진
- 자바 입출력 스트림
- 쿠버네티스
- 스레드 제어와 생명 주기
- 스레드
- java network
- 알고리즘
- java
- filewriter filereader
- 컨테이너
- Kubernetes
- Java IO
- Today
- Total
쌩로그
김영한의 실전 자바 - 중급 2편 - Sec 06. 컬렉션 프레임워크 - List 본문
목차
- 포스팅 개요
- 본론
2-1. 리스트 추상화1 - 인터페이스 도입
2-2. 리스트 추상화2 - 의존관계 주입
2-3. 리스트 추상화3 - 컴파일 타임, 런타임 의존관계
2-4. 직접 구현한 리스트의 성능 비교
2-5. 자바 리스트
2-6. 자바 리스트의 성능 비교 - 요약
1. 포스팅 개요
해당 포스팅은 김영한의 실전 자바 중급 2편 Section 6의 `컬렉션 프레임워크 - List 에 대한 학습 내용이다.
학습 레포 URL : https://github.com/SsangSoo/inflearn-holyeye-java-mid2
(해당 레포는 완강시 public으로 전환 예정이다.)
2. 본론
2-1. 리스트 추상화1 - 인터페이스 도입
자료 구조에 다형성과 OCP 원칙이 어떻게 적용되는지 먼저 알아본다.
List 자료 구조
순서가 있고, 중복을 허용하는 자료 구조를 리스트(List)라 한다.
지금까지 만든 MyArrayList 와 MyLinkedList 는 내부 구현만 다를 뿐 같은 기능을 제공하는 리스트다.
내부 구현이 다르기 때문에 상황에 따라 성능은 달라질 수 있다.
핵심은 사용자 입장에서 보면 같은 기능을 제공한다.
둘의 공통 기능을 인터페이스로 뽑아서 추상화하면 다형성을 활용한 다양한 이점을 얻을 수 있다.
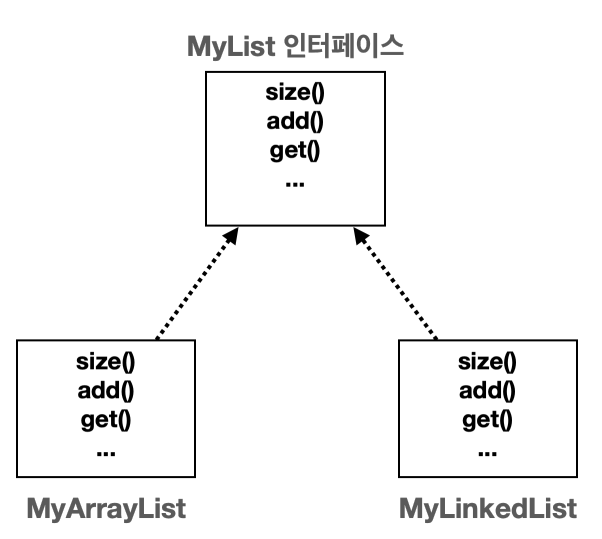
같은 기능을 제공하는 메서드를 MyList 인터페이스로 뽑아본다.
public interface MyList<E> {
int size();
void add(E e);
void add(int index, E e);
E get(int index);
E set(int index, E element);
E remove(int index);
int indexOf(E o);
}그리고 이전에 만들었던 MyArrayListV4 와 MyLinkedListV3 을 복붙하여 MyArrayList 와 MyLinkedList 라는 클래스 이름으로 MyList와 같은 패키지 안에 넣어둔다.
그리고 implemnet MyList<E> 를 추가해준다.
2-2. 리스트 추상화2 - 의존관계 주입
MyArrayList 를 활용해서 많은 데이터를 처리하는 BatchProcessor 클래스를 개발하고 있다고 가정할 때, 프로그램을 개발하고 보니 데이터를 앞에서 추가하는 일이 많은 상황이다.
앞서 살펴본 것처럼 데이터를 앞에서 추가 하거나 삭제하는 일이 많다면 MyArrayList 보다는 MyLinkedList 를 사용하는 것이 훨씬 효율적이다.
데이터를 앞에서 추가하거나 삭제할 때 빅오 비교
MyArrayList: O(n)MyLinkedList: O(1)
예시 코드다.
구체적인 MyArrayList에 의존하는 BatchProcessor 예시
public class BatchProcessor {
private final MyArrayList list = new MyArrayList<>(); //코드 변경
public void logic(int size) {
for (int i = 0; i < size; i++) {
list.add(0, i); //앞에 추가
}
}
}MyArrayList를 사용해보니 성능이 너무 느려서MyLinkedList를 사용하도록 코드를 변경해야 한다.BatchProcessor의 내부 코드가MyArrayList에서MyLinkedList를 사용하도록 다음과 같이 변경해야 한다.
구체적인 MyLinkedList에 의존하는 BatchProcessor 예시
public class BatchProcessor {
private final MyLinkedList list = new MyLinkedList<>(); //코드 변경
public void logic(int size) {
for (int i = 0; i < size; i++) {
list.add(0, i); //앞에 추가
}
}
}BatchProcessor는 구체적인MyArrayList또는MyLinkedList를 사용하고 있다.- 이것을
BatchProcessor가 구체적인 클래스에 의존한다고 표현한다.- 이렇게 구체적인 클래스에 직접 의존하면
MyArrayList를MyLinkedList로 변경할 때 마다 여기에 의존하는BatchProcessor의 코드도 함께 수정해야 한다.
- 이렇게 구체적인 클래스에 직접 의존하면
BatchProcessor가 구체적인 클래스에 의존하는 대신 추상적인MyList인터페이스에 의존하는 방법도 있다.
추상적인 MyList에 의존하는 BatchProcessor 예시는 다음과 같다.
public class BatchProcessor {
private final MyList list;
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}
public void logic(int size) {
for (int i = 0; i < size; i++) {
list.add(0, i); //앞에 추가
}
}
} main() {
new BatchProcessor(new MyArrayList()); //MyArrayList를 사용하고 싶을 때
new BatchProcessor(new MyLinkedList()); //MyLinkedList를 사용하고 싶을 때
}BatchProcessor를 생성하는 시점에 생성자를 통해 원하는 리스트 전략(알고리즘)을 선택해서 전달하면 된다.- 이렇게 하면
MyList를 사용하는 클라이언트 코드인BatchProcessor의 코드를 전혀 변경하지 않고, 원하는 리스트 전략을 런타임에 지정할 수 있다.
정리하면 다형성과 추상화를 활용하면 BatchProcessor 코드를 전혀 변경하지 않고 리스트 전략(알고리즘)을 MyArrayList 에서 MyLinkedList 로 변경할 수 있다.
실제 코드다.
public class BatchProcessor {
private final MyList<Integer> list;
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}
public void logic(int size) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < size; i++) {
list.add(0, 1);
}
long endTime = System.currentTimeMillis();
System.out.println("크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
}logic(int size)메서드는 매우 복잡한 비즈니스 로직을 다룬다고 가정하고, 이 메서드는list의 앞 부분에 데이터를 추가한다.- 어떤
MyList list의 구현체를 선택할 지는 실행 시점에 생성자를 통해서 결정한다. - 생성자를 통해서
MyList구현체가 전달된다.MyArrayList의 인스턴스가 들어올 수도 있고,MyLinkedList의 인스턴스가 들어올 수도 있다.
- 이것은
BatchProcessor의 외부에서 의존관계가 결정되어서BatchProcessor인스턴스에 들어오는 것 같다. 마치 의존관계가 외부에서 주입되는 것 같다고 해서 이것을 의존관계 주입이라 한다. - 참고로 생성자를 통해서 의존관계를 주입했기 때문에 생성자 의존관계 주입이라 한다.
의존관계 주입
- Dependency Injection, 줄여서 DI라고 부른다. 의존성 주입이라고도 부른다.
위의 코드를 실제로 사용해보자.
public class BatchProcessorMain {
public static void main(String[] args) {
MyArrayList<Integer> list = new MyArrayList<>();
BatchProcessor processor = new BatchProcessor(list);
processor.logic(1_000_000);
}
}
// MyArrayList 결과
크기: 50000, 계산 시간: 3006ms // 50,000 건
크기: 100000, 계산 시간: 12593ms // 100,000 건
안 나온다. // 1,000,000 건
// MyLinkedList 결과
크기: 50000, 계산 시간: 5ms // 50,000 건
크기: 100000, 계산 시간: 7ms // 100,000 건
크기: 1000000, 계산 시간: 113ms // 1,000,000 건MyArrayList의 100만의 결과를 집어넣었는데, 결과가 안나온다..
BatchProcessor의 생성자에MyArrayList를 사용할지,MyLinkedList를 사용할지 결정해서 넘겨야 한다.이후에
processor.logic()을 호출하면 생성자로 넘긴 자료 구조를 사용해서 실행한다.MyLinkedList를 사용한 덕분에O(n)->O(1)로 훨씬 더 성능이 개선 된 것을 확인할 수 있다.데이터가 증가할수록 성능의 차이는 더 벌어진다.
2-3. 리스트 추상화3 - 컴파일 타임, 런타임 의존관계
의존관계는 컴파일 타임 의존관계와 런타임 의존관계로 나눌 수 있다.
- 컴파일 타임(compile time) : 코드 컴파일 시점을 뜻함.
- 런타임(runtime) : 프로그램 실행 시점을 뜻함.
컴파일 타임 의존 관계 vs 런타임 의존관계
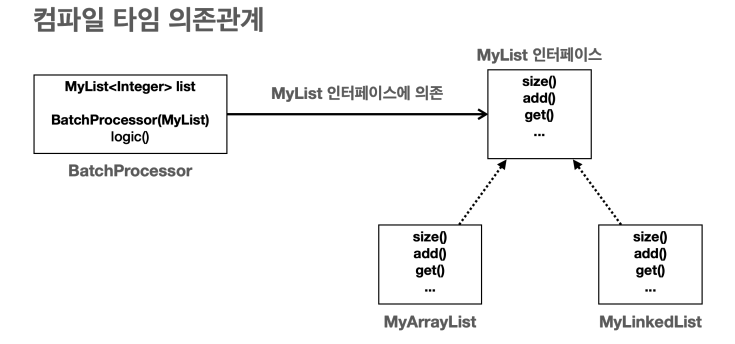
- 컴파일 타임 의존관계는 자바 컴파일러가 보는 의존관계이다.
- 클래스에 모든 의존관계가 다 나타난다.
- 클래스에 바로 보이는 의존관계이다.
- 실행하지 않은 소스 코드에 정적으로 나타나는 의존 관계이다.
BatchProcessor클래스를 보면MyList인터페이스만 사용한다.- 코드 어디에도
MyArrayList나MyLinkedList같은 정보는 보이지 않는다. - 따라서
BatchProcessor는MyList인터페이스에만 의존한다.
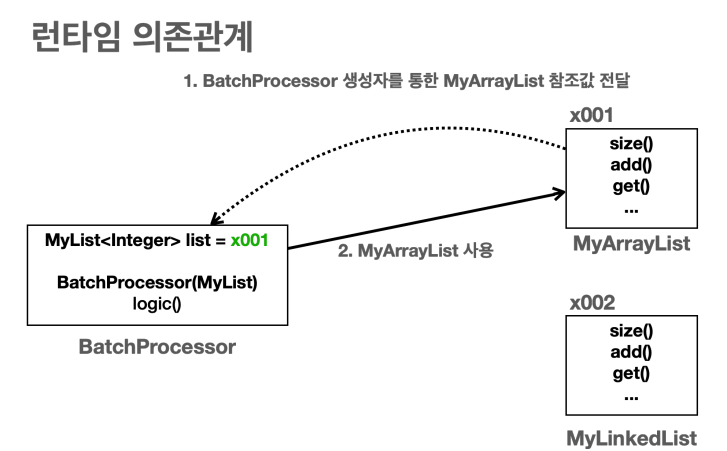
- 런타임 의존관계는 실제 프로그램이 작동할 때 보이는 의존관계다.
- 주로 생성된 인스턴스와 그것을 참조하는 의존 관계이다.
- 프로그램이 실행될 때 인스턴스 간에 의존관계로 보면 된다.
- 런타임 의존관계는 프로그램 실행 중에 계속 변할 수 있다
정리
MyList인터페이스의 도입으로 같은 리스트 자료구조를 그대로 사용하면서 원하는 구현을 변경할 수 있게 되었다.BatchProcessor에서 다음과 같이 처음부터MyArrayList를 사용하도록 컴파일 타임 의존관계를 지정했다면 이후에MyLinkedList로 수정하기 위해서는BatchProcessor의 코드를 변경해야 한다.
BatchProcessor클래스는 구체적인MyArrayList나MyLinkedList에 의존하는 것이 아니라 추상적인MyList에 의존한다.- 런타임에
MyList의 구현체를 얼마든지 선택할 수 있다.
- 런타임에
BatchProcessor에서 사용하는 리스트의 의존관계를 클래스에서 미리 결정하는 것이 아니라, 런타임에 객체 를 생성하는 시점으로 미룬다.- 따라서 런타임에
MyList의 구현체를 변경해도BatchProcessor의 코드는 전혀 변경하지 않아도 된다.
- 따라서 런타임에
- 생성자를 통해 런타임 의존관계를 주입하는 것을 생성자 의존관계 주입 또는 줄여서 생성자 주입이라 한다.
- 자바 기본편에서 학습한 OCP 원칙을 지켰다.
- 클라이언트 코드의 변경 없이, 구현 알고리즘인
MyList인터페이스의 구현을 자유롭게 확장할 수 있다.
- 클라이언트 클래스는 컴파일 타임에 추상적인 것에 의존하고, 런타임에 의존 관계 주입을 통해 구현체를 주입받아 사용함으로써, 이런 이점을 얻을 수 있다.
전략 패턴(Strategy Pattern)
- 디자인 패턴 중에 가장 중요한 패턴을 하나 뽑으라고 하면 전략 패턴을 뽑을 수 있다.
- 전략 패턴은 알고리즘을 클라이언트 코드의 변경 없이 쉽게 교체할 수 있다.
- 방금 설명한 코드가 바로 전략 패턴을 사용한 코드이다.
MyList인터페이스가 바로 전략을 정의하는 인터페이스가 되고, 각각의 구현체인MyArrayList,MyLinkedList가 전략의 구체적인 구현이 된다.- 그리고 전략을 클라이언트 코드(
BatchProcessor)의 변경 없이 손쉽게 교체할 수 있다.
2-4. 직접 구현한 리스트의 성능 비교
직접 구현한 리스트들의 성능을 비교하자.
public class MyListPerformanceTest {
public static void main(String[] args) {
int size = 50000;
System.out.println("==MyArrayList 추가==");
addFirst(new MyArrayList<>(), size);
addMid(new MyArrayList<>(), size);
MyArrayList<Integer> arrayList = new MyArrayList<>();
addLast(arrayList, size);
int loop = 10000;
System.out.println("==MyArrayList 조회");
getIndex(arrayList, loop, 0);
getIndex(arrayList, loop, size / 2);
getIndex(arrayList, loop, size - 1);
System.out.println("==MyArrayList 검색");
search(arrayList, loop, 0);
search(arrayList, loop, size / 2);
search(arrayList, loop, size - 1);
System.out.println("==MyLinkedList 추가==");
addFirst(new MyLinkedList<>(), size);
addMid(new MyLinkedList<>(), size);
MyLinkedList<Integer> linkedList = new MyLinkedList();
addLast(linkedList, size);
System.out.println("==MyLinkedList 조회");
getIndex(linkedList, loop, 0);
getIndex(linkedList, loop, size / 2);
getIndex(linkedList, loop, size - 1);
System.out.println("==MyLinkedList 검색");
search(linkedList, loop, 0);
search(linkedList, loop, size / 2);
search(linkedList, loop, size - 1);
}
private static void addFirst(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < size; i++) {
list.add(0, i);
}
long endTime = System.currentTimeMillis();
System.out.println("앞에 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void addMid(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < size; i++) {
list.add(i / 2, i);
}
long endTime = System.currentTimeMillis();
System.out.println("평균 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void addLast(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < size; i++) {
list.add(i);
}
long endTime = System.currentTimeMillis();
System.out.println("뒤에 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void getIndex(MyList<Integer> list, int loop, int index) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < loop; i++) {
list.get(index);
}
long endTime = System.currentTimeMillis();
System.out.println("index: " + index + ", 반복: " + loop + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void search(MyList<Integer> list, int loop, int findValue) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < loop; i++) {
list.indexOf(findValue);
}
long endTime = System.currentTimeMillis();
System.out.println("findValue: " + findValue + ", 반복: " + loop + ", 계산 시간: " + (endTime - startTime) + "ms");
}
}
// 결과
==MyArrayList 추가==
앞에 추가 - 크기: 50000, 계산 시간: 2395ms
평균 추가 - 크기: 50000, 계산 시간: 1348ms
뒤에 추가 - 크기: 50000, 계산 시간: 5ms
==MyArrayList 조회
index: 0, 반복: 10000, 계산 시간: 1ms
index: 25000, 반복: 10000, 계산 시간: 0ms
index: 49999, 반복: 10000, 계산 시간: 1ms
==MyArrayList 검색
findValue: 0, 반복: 10000, 계산 시간: 1ms
findValue: 25000, 반복: 10000, 계산 시간: 384ms
findValue: 49999, 반복: 10000, 계산 시간: 809ms
==MyLinkedList 추가==
앞에 추가 - 크기: 50000, 계산 시간: 3ms
평균 추가 - 크기: 50000, 계산 시간: 1426ms
뒤에 추가 - 크기: 50000, 계산 시간: 3396ms
==MyLinkedList 조회
index: 0, 반복: 10000, 계산 시간: 1ms
index: 25000, 반복: 10000, 계산 시간: 588ms
index: 49999, 반복: 10000, 계산 시간: 1183ms
==MyLinkedList 검색
findValue: 0, 반복: 10000, 계산 시간: 0ms
findValue: 25000, 반복: 10000, 계산 시간: 882ms
findValue: 49999, 반복: 10000, 계산 시간: 1456ms앞에 추가(삭제)
- 배열 리스트: 추가나 삭제할 위치는 찾는데 O(1), 데이터를 한칸씩 이동 O(n) : O(n)
- 연결 리스트: 추가나 삭제할 위치는 찾는데 O(1), 노드를 변경하는데 O(1) : O(1)
평균 추가(삭제)
- 배열 리스트: 추가나 삭제할 위치는 찾는데 O(1), 인덱스 이후의 데이터를 한칸씩 이동 O(n/2) : O(n)
- 연결 리스트: 추가나 삭제할 위치는 찾는데 O(n/2), 노드를 변경하는데 O(1) : O(n)
뒤에 추가(삭제)
- 배열 리스트: 추가나 삭제할 위치는 찾는데 O(1), 이동할 데이터 없음 : O(1)
- 연결 리스트: 추가나 삭제할 위치는 찾는데 O(n), 노드를 변경하는데 O(1) : O(n)
인덱스 조회
- 배열 리스트: 배열에 인덱스를 사용해서 값을 O(1)로 찾을 수 있음
- 연결 리스트: 노드를 인덱스 수 만큼 이동해야함 : O(n)
검색
- 배열 리스트: 데이터를 찾을 때 까지 배열을 순회 : O(n)
- 연결 리스트: 데이터를 찾을 때 까지 노드를 순회 : O(n)
시간 복잡도와 실제 성능
- 이론적으로
MyLinkedList의 평균 추가(중간 삽입) 연산은MyArrayList보다 빠를 수 있다.- 그러나 실제 성능은 요소의 순차적 접근 속도, 메모리 할당 및 해제 비용, CPU 캐시 활용도 등 다양한 요소에 의해 영향을 받는다.
MyArrayList는 요소들이 메모리 상에서 연속적으로 위치하여 CPU 캐시 효율이 좋고, 메모리 접근 속도가 빠르다.- 반면,
MyLinkedList는 각 요소가 별도의 객체로 존재하고 다음 요소의 참조를 저장하기 때문에 CPU 캐시 효율이 떨어지고, 메모리 접근 속도가 상대적으로 느릴 수 있다. MyArrayList의 경우CAPACITY를 넘어서면 배열을 다시 만들고 복사하는 과정이 추가된다.- 하지만 한번에 2배씩 늘어나기 때문에 이 과정은 가끔 발생하므로, 전체 성능에 큰 영향을 주지는 않는다.
정리하면, 이론적으로 MyLinkedList 가 평균 추가(중간 삽입)에 있어 더 효율적일 수 있지만, 현대 컴퓨터 시스템의 메모리 접근 패턴, CPU 캐시 최적화 등을 고려할 때 MyArrayList 가 실제 사용 환경에서 더 나은 성능을 보여주는 경우가 많다.
배열 리스트 vs 연결 리스트
- 대부분의 경우 배열 리스트가 성능상 유리하다.
- 이런 이유로 실무에서는 주로 배열 리스트를 기본으로 사용한다.
- 만약 데이터를 앞쪽에서 자주 추가하거나 삭제할 일이 있다면 연결 리스트를 고려하자.
2-5. 자바 리스트
List 자료 구조
순서가 있고, 중복을 허용하는 자료 구조를 리스트라 한다.
자바의 컬렉션 프레임워크가 제공하는 가장 대표적인 자료 구조가 바로 리스트이다.
리스트와 관련된 컬렉션 프레임워크는 다음 구조를 가진다.
컬렉션 프레임워크 - 리스트
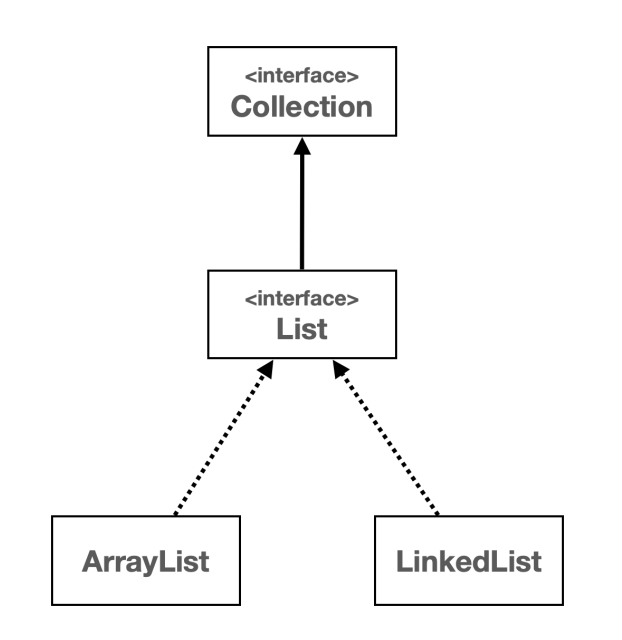
Collection 인터페이스
Collection인터페이스는java.util패키지의 컬렉션 프레임워크의 핵심 인터페이스 중 하나이다.- 이 인터페이 스는 자바에서 다양한 컬렉션, 즉 데이터 그룹을 다루기 위한 메서드를 정의한다.
Collection인터페이스는List,Set,Queue와 같은 다양한 하위 인터페이스와 함께 사용되며, 이를 통해 데이터를 리스트, 세트, 큐 등의 형태로 관리할 수 있다.
List 인터페이스
List인터페이스는java.util패키지에 있는 컬렉션 프레임워크의 일부다.List는 객체들의 순서가 있는 컬렉션을 나타내며, 같은 객체의 중복 저장을 허용한다.- 리스트는 배열과 비슷하지만, 크기가 동적으로 변화하는 컬렉션을 다룰 때 유연하게 사용할 수 있다.
List인터페이스는ArrayList,LinkedList와 같은 여러 구현 클래스를 가지고 있으며, 각 클래스는List인 터페이스의 메서드를 구현한다.
List 인터페이스의 주요 메서드
| 메서드 | 설명 |
|---|---|
add(E e) |
리스트의 끝에 지정된 요소를 추가한다. |
add(int index, E element) |
리스트의 지정된 위치에 요소를 삽입한다. |
addAll(Collection c) |
지정된 컬렉션의 모든 요소를 리스트의 끝에 추가한다. |
addAll(int index, Collection c) |
지정된 컬렉션의 모든 요소를 리스트의 지정된 위치에 추 가한다. |
get(int index) |
리스트에서 지정된 위치의 요소를 반환한다. |
set(int index, E element) |
지정한 위치의 요소를 변경하고, 이전 요소를 반환한다. |
remove(int index) |
리스트에서 지정된 위치의 요소를 제거하고 그 요소를 반 환한다. |
remove(Object o) |
리스트에서 지정된 첫 번째 요소를 제거한다. |
clear() |
리스트에서 모든 요소를 제거한다. |
indexOf(Object o) |
리스트에서 지정된 요소의 첫 번째 인덱스를 반환한다. |
lastIndexOf(Object o) |
리스트에서 지정된 요소의 마지막 인덱스를 반환한다. |
contains(Object o) |
리스트가 지정된 요소를 포함하고 있는지 여부를 반환한 다. |
sort(Comparator c) |
리스트의 요소를 지정된 비교자에 따라 정렬한다 |
subList(int fromIndex, int toIndex) |
리스트의 일부분의 뷰를 반환한다. |
size() |
리스트의 요소 수를 반환한다. |
isEmpty() |
리스트가 비어있는지 여부를 반환한다. |
iterator() |
리스트의 요소에 대한 반복자를 반환한다 |
toArray() |
리스트의 모든 요소를 배열로 반환한다 |
toArray(T[] a) |
리스트의 모든 요소를 지정된 배열로 반환한다. |
자바 ArrayList
java.util.ArrayList- 자바가 제공하는
ArrayList는 우리가 직접 만든MyArrayList와 거의 비슷하다. - 특징은 다음과 같다
- 배열을 사용해서 데이터를 관리한다.
- 기본
CAPACITY는 10이다.(DEFAULT_CAPACITY = 10)CAPACITY를 넘어가면 배열을 50% 증가한다.- 10 -> 15 -> 22 -> 33 -> 49로 증가한다. (최적화는 자바 버전에 따라 달라질 수 있다.)
- 메모리 고속 복사 연산을 사용한다.
ArrayList의 중간 위치에 데이터를 추가하면, 추가할 위치 이후의 모든 요소를 한 칸씩 뒤로 이동시켜야 한다.- 자바가 제공하는
ArrayList는 이 부분을 최적화 하는데, 배열의 요소 이동은 시스템 레벨에서 최적화된 메모리 고속 복사 연산을 사용해서 비교적 빠르게 수행된다. 참고로System.arraycopy()를 사용한다.
데이터 추가 - 한 칸씩 이동하는 방식
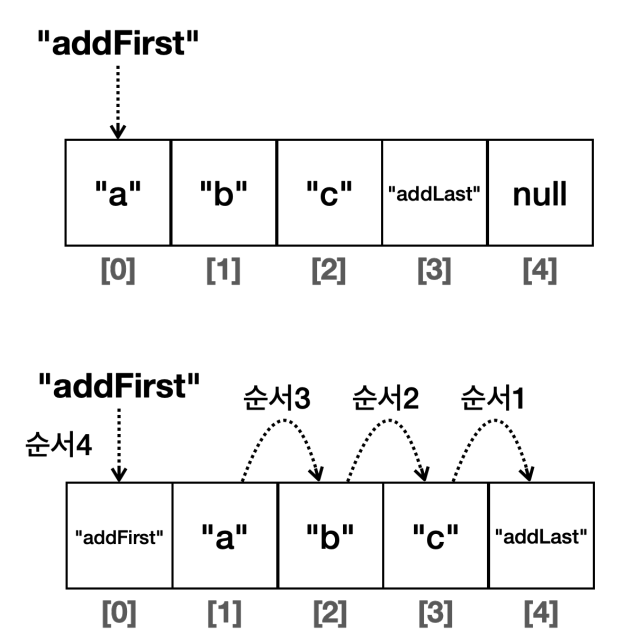
- 데이터를 루프를 돌면서 하나씩 이동해야 하기 때문에 매우 느리다.
MyArrayList에서 사용한 방식이다
데이터 추가 - 메모리 고속 복사 연산 사용
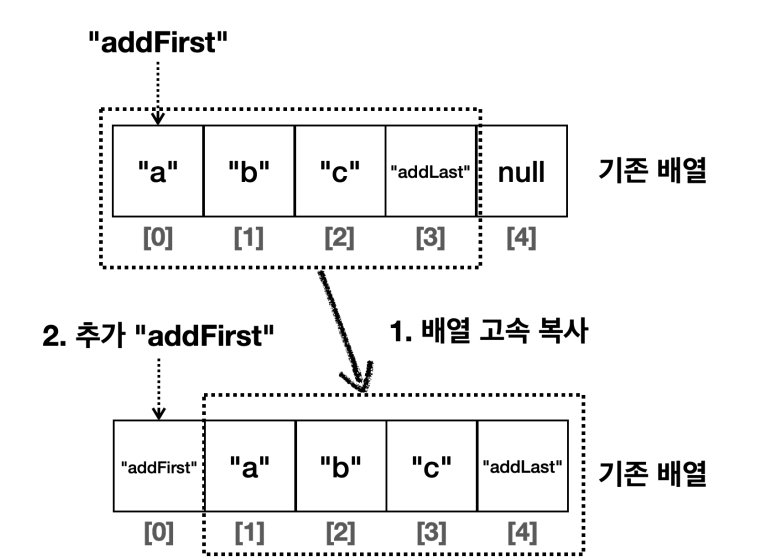
- 시스템 레벨에서 배열을 한 번에 아주 빠르게 복사한다.
- 이 부분은 OS, 하드웨어에 따라 성능이 다르기 때문에 정확한 측정이 어렵지만, 한 칸씩 이동하는 방식과 비교하면 보통 수 배 이상의 빠른 성능을 제공한다.
자바 LinkedList
java.util.LinkedList- 자바가 제공하는
LinkedList는 우리가 직접 만든MyLinkedList와 거의 비슷하다. - 특징은 다음과 같다.
- 이중 연결 리스트 구조
- 첫 번째 노드와 마지막 노드 둘다 참조
단일 연결 리스트
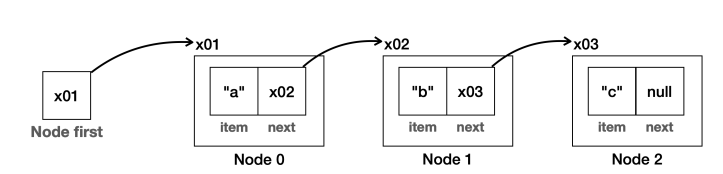
- 우리가 직접 만든
MyLinkedList의 노드는 다음 노드로만 이동할 수 있는 단일 연결 구조다. - 따라서 이전 노드로 이동할 수 없다는 단점이 있다.
이중 연결 리스트

- 자바가 제공하는
LinkedList는 이중 연결 구조를 사용한다.- 이 구조는 다음 노드 뿐만 아니라 이전 노드로도 이동할 수 있다.
- 예)
node.next를 호출하면 다음 노드로,node.prev를 호출하면 이전 노드로 이동한다.
- 마지막 노드에 대한 참조를 제공한다. 따라서 데이터를 마지막에 추가하는 경우에도 O(1)의 성능을 제공한다.
- 이전 노드로 이동할 수 있기 때문에 마지막 노드부터 앞으로, 그러니까 역방향으로 조회할 수 있다.
- 덕분에 인덱스 조회 성능을 최적화 할 수 있다.
- 예를 들어 인덱스로 조회하는 경우 인덱스가 사이즈의 절반 이하라면 처음부터 찾아서 올라가고, 인덱스가 사이즈의 절반을 넘으면 마지막 노드부터 역방향으로 조회해서 성능을 최적화 할 수 있다.
2-6. 자바 리스트의 성능 비교
자바가 제공하는 리스트의 성능을 비교해보자.
위에 만들었던 MyListPerformanceTest 코드를 복사해서 자바의 리스트를 사용하도록 일부를 코드를 수정하면 된다.
수정 코드
MyList->ListMyArrayList->ArrayListMyLinkedList->LinkedList
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class JavaListPerformanceTest {
public static void main(String[] args) {
int size = 50000;
System.out.println("==ArrayList 추가==");
addFirst(new ArrayList<>(), size);
addMid(new ArrayList<>(), size);
ArrayList<Integer> arrayList = new ArrayList<>();
addLast(arrayList, size);
int loop = 10000;
System.out.println("==ArrayList 조회");
getIndex(arrayList, loop, 0);
getIndex(arrayList, loop, size / 2);
getIndex(arrayList, loop, size - 1);
System.out.println("==ArrayList 검색");
search(arrayList, loop, 0);
search(arrayList, loop, size / 2);
search(arrayList, loop, size - 1);
System.out.println("==LinkedList 추가==");
addFirst(new LinkedList<>(), size);
addMid(new LinkedList<>(), size);
LinkedList<Integer> linkedList = new LinkedList();
addLast(linkedList, size);
System.out.println("==LinkedList 조회");
getIndex(linkedList, loop, 0);
getIndex(linkedList, loop, size / 2);
getIndex(linkedList, loop, size - 1);
System.out.println("==LinkedList 검색");
search(linkedList, loop, 0);
search(linkedList, loop, size / 2);
search(linkedList, loop, size - 1);
}
private static void addFirst(List<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < size; i++) {
list.add(0, i);
}
long endTime = System.currentTimeMillis();
System.out.println("앞에 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void addMid(List<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < size; i++) {
list.add(i / 2, i);
}
long endTime = System.currentTimeMillis();
System.out.println("평균 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void addLast(List<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < size; i++) {
list.add(i);
}
long endTime = System.currentTimeMillis();
System.out.println("뒤에 추가 - 크기: " + size + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void getIndex(List<Integer> list, int loop, int index) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < loop; i++) {
list.get(index);
}
long endTime = System.currentTimeMillis();
System.out.println("index: " + index + ", 반복: " + loop + ", 계산 시간: " + (endTime - startTime) + "ms");
}
private static void search(List<Integer> list, int loop, int findValue) {
long startTime = System.currentTimeMillis();
for(int i = 0; i < loop; i++) {
list.indexOf(findValue);
}
long endTime = System.currentTimeMillis();
System.out.println("findValue: " + findValue + ", 반복: " + loop + ", 계산 시간: " + (endTime - startTime) + "ms");
}
}
// 결과
==ArrayList 추가==
앞에 추가 - 크기: 50000, 계산 시간: 88ms
평균 추가 - 크기: 50000, 계산 시간: 41ms
뒤에 추가 - 크기: 50000, 계산 시간: 4ms
==ArrayList 조회
index: 0, 반복: 10000, 계산 시간: 0ms
index: 25000, 반복: 10000, 계산 시간: 0ms
index: 49999, 반복: 10000, 계산 시간: 0ms
==ArrayList 검색
findValue: 0, 반복: 10000, 계산 시간: 2ms
findValue: 25000, 반복: 10000, 계산 시간: 207ms
findValue: 49999, 반복: 10000, 계산 시간: 369ms
==LinkedList 추가==
앞에 추가 - 크기: 50000, 계산 시간: 3ms
평균 추가 - 크기: 50000, 계산 시간: 1116ms
뒤에 추가 - 크기: 50000, 계산 시간: 4ms
==LinkedList 조회
index: 0, 반복: 10000, 계산 시간: 2ms
index: 25000, 반복: 10000, 계산 시간: 427ms
index: 49999, 반복: 10000, 계산 시간: 1ms
==LinkedList 검색
findValue: 0, 반복: 10000, 계산 시간: 1ms
findValue: 25000, 반복: 10000, 계산 시간: 516ms
findValue: 49999, 반복: 10000, 계산 시간: 1601ms추가, 삭제
- 배열 리스트는 인덱스를 통해 추가나 삭제할 위치를 O(1)로 빠르게 찾지만, 추가나 삭제 이후에 데이터를 한칸씩 밀어야 한다. 이 부분이 O(n)으로 오래 걸린다.
- 연결 리스트는 인덱스를 통해 추가나 삭제할 위치를 O(n)으로 느리게 찾지만, 실제 데이터의 추가는 간단한 참조 변경으로 O(1)로 빠르게 수행된다.
앞에 추가(삭제)
- 배열 리스트: 추가나 삭제할 위치는 찾는데 O(1), 데이터를 한칸씩 이동 O(n) -> O(n)
- 연결 리스트: 추가나 삭제할 위치는 찾는데 O(1), 노드를 변경하는데 O(1) -> O(1)
평균 추가(삭제)
- 배열 리스트: 추가나 삭제할 위치는 찾는데 O(1), 인덱스 이후의 데이터를 한칸씩 이동 O(n/2) -> O(n)
- 연결 리스트: 추가나 삭제할 위치는 찾는데 O(n/2), 노드를 변경하는데 O(1) -> O(n)
뒤에 추가(삭제)
- 배열 리스트: 추가나 삭제할 위치는 찾는데 O(1), 이동할 데이터 없음 -> O(1)
- 연결 리스트: 추가나 삭제할 위치는 찾는데 O(1), 노드를 변경하는데 O(1) -> O(1)
- 참고로 자바가 제공하는 연결 리스트(
LinkedList)는 마지막 위치를 가지고 있다.
- 참고로 자바가 제공하는 연결 리스트(
인덱스 조회
- 배열 리스트: 배열에 인덱스를 사용해서 값을 O(1)로 찾을 수 있음
- 연결 리스트: 노드를 인덱스 수 만큼 이동해야함 O(n)
검색
- 배열 리스트: 데이터를 찾을 때 까지 배열을 순회 O(n)
- 연결 리스트: 데이터를 찾을 때 까지 노드를 순회 O(n)
데이터를 추가할 때 자바 ArrayList가 직접 구현한 MyArrayList보다 빠른 이유
- 자바의 배열 리스트는 이때 메모리 고속 복사를 사용하기 때문에 성능이 최적화된다.
- 메모리 고속 복사는 시스템에 따라 성능이 다르기 때문에 정확한 계산은 어렵지만 대략 O(n/10) 정도로 추정하자. 상수를 제거하면 O(n)이 된다.
- 메모리 고속 복사라도 데이터가 아주 많으면 느려진다.
시간 복잡도와 실제 성능
- 이론적으로
LinkedList의 중간 삽입 연산은ArrayList보다 빠를 수 있다. 그러나 실제 성능은 요소의 순차적 접근 속도, 메모리 할당 및 해제 비용, CPU 캐시 활용도 등 다양한 요소에 의해 영향을 받는다.- 추가로
ArrayList는 데이터를 한 칸씩 직접 이동하지 않고, 대신에 메모리 고속 복사를 사용한다.
- 추가로
ArrayList는 요소들이 메모리 상에서 연속적으로 위치하여 CPU 캐시 효율이 좋고, 메모리 접근 속도가 빠르다.LinkedList는 각 요소가 별도의 객체로 존재하고 다음 요소의 참조를 저장하기 때문에 CPU 캐시 효율이 떨어지고, 메모리 접근 속도가 상대적으로 느려질 수 있다ArrayList의 경우CAPACITY를 넘어서면 배열을 다시 만들고 복사하는 과정이 추가된다. 하지만 한번에 50%씩 늘어나기 때문에 이 과정은 가끔 발생하므로, 전체 성능에 큰 영향을 주지는 않는다.
정리하면 이론적으로 LinkedList 가 중간 삽입에 있어 더 효율적일 수 있지만, 현대 컴퓨터 시스템의 메모리 접근 패턴, CPU 캐시 최적화, 메모리 고속 복사 등을 고려할 때 ArrayList 가 실제 사용 환경에서 더 나은 성능을 보여주는 경우가 많다.
배열 리스트 vs 연결 리스트
- 대부분의 경우 배열 리스트가 성능상 유리하다.
- 이런 이유로 실무에서는 주로 배열 리스트를 기본으로 사용한다.
- 만약 데이터를 앞쪽에서 자주 추가하거나 삭제할 일이 있다면 연결 리스트를 고려하자.
3. 요약
- 이전에 직접 구현했던
MyArrayList와MyLinkedList를 추상화한MyList인터페이스를 만듦으로써 자바의ArrayList와LinkedList그리고List에 대해 알아보았다. MyArrayList와MyLinkedList의 성능을 비교해봤고, 어떤 경우에 어떤 자료 구조가 더 빠른지 알 수 있었고, 자바가 제공하는ArrayList와LinkedList의 성능까지 비교해보았다.- 이론적으로는 연결리스트가 배열리스트보다 더 빠른 경우일 거라고 생각했던 부분(예를 들면 중간에 데이터 추가 같은 경우)이 있지만, CPU 캐시 최적화, 메모리 고속 복사등 현대 컴퓨터 시스템에 의해서 그렇지 않은 경우도 있다.
- 정말 데이터가 무수히 많을 때는 이론적인 부분과 같이
LinkedList를 사용했을 때 더 빠를 수 있다. - (영한님이 경험을 공유해주심.. 데이터가 수백만건이 있을 때
ArrayList를 사용하다가LinkedList를 사용해서 성능을 최적화 하셨다고 함.)
- 정말 데이터가 무수히 많을 때는 이론적인 부분과 같이
다음은 Hash 다
'Language > JAVA' 카테고리의 다른 글
| 김영한의 실전 자바 - 중급 2편 - Sec 08. 컬렉션 프레임워크 - HashSet (0) | 2025.01.23 |
|---|---|
| 김영한의 실전 자바 - 중급 2편 - Sec 07. 컬렉션 프레임워크 - 해시(Hash) (1) | 2025.01.18 |
| 김영한의 실전 자바 - 중급 2편 - Sec 05. 컬렉션 프레임워크 - LinkedList (0) | 2025.01.10 |
| 김영한의 실전 자바 - 중급 2편 - Sec 04. 컬렉션 프레임워크 - ArrayList (0) | 2025.01.09 |
| 김영한의 실전 자바 - 중급 2편 - Sec 03. 제네릭 - Generic2 (0) | 2025.01.05 |