
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 김영한
- 데이터베이스
- 컨테이너
- SQL
- RDB
- replicaset
- lambda
- 동시성
- mysql
- 스레드
- 시작하세요 도커 & 쿠버네티스
- 자바 입출력 스트림
- 쓰레드
- 함수형 인터페이스
- Thread
- 인프런
- Docker
- db
- container
- 실전 자바 고급 1편
- 자료구조
- 쿠버네티스
- 알고리즘
- Kubernetes
- 일프로
- 람다
- 자바
- 도커
- 도커 엔진
- java
- Today
- Total
쌩로그
[Kubernetes] 쿠버네티스 어나더 클래스-Sprint 1. 실무에서 느껴 본 쿠버네티스가 정말 편한 이유 본문
[Kubernetes] 쿠버네티스 어나더 클래스-Sprint 1. 실무에서 느껴 본 쿠버네티스가 정말 편한 이유
.쌩수. 2026. 3. 27. 07:33목록
- 포스팅 개요
- 본론
2-1. 쿠버네티스 표준 생태계로 편해진 IT 인프라 구축
2-2. 모니터링 설치 - Loki-Stack(🖥️실습포함)
2-3. 쿠버네티스 대표 기능 - Traffic Routing, Self-Healing, AutoScaling, RollingUpdate(🖥️실습포함)
2-4. 쿠버네티스 기능으로 편해진 서비스 안정화 및 인프라 환경 관리 코드화
2-5. 쿠버네티스 엔지니어가 되려면.. - 요약
1. 포스팅 개요
해당 포스팅은 인프런의 일프로님의 쿠버네티스 어나더 클래스-Spring 1,2 (#실무기초 #설치 #배포 #Jenkins #Helm #ArgoCD) 중 Sprint1의 실무에서 느껴 본 쿠버네티스가 정말 편한 이유 를 학습하며 정리한 글이다.
2. 본론
2-1. 쿠버네티스 표준 생태계로 편해진 IT 인프라 구축
쿠버네티스가 나온지 10년도 되지 않았음에도 불구하고, 아래 그림과 같이 많은 제품들이 쿠버네티스 생태계에서 돌아간다.
이미지 출처 - 인프런-쿠버네티스 어나더 클래스-Sprint 1, 2 (#실무기초 #설치 #배포 #Jenkins #Helm #ArgoCD)
자세히 보진 말자.. 눈 아프다...
IT에 관련된 모든 회사가 쿠버네티스와 컨테이너에 진입했다해도 과언이 아닐정도다.
그런데 이 모든 걸 알 필요는 없다.
CNCF에서 클라우드 생태계를 영역별로 카테고리화 시켰다.
뺄 부분부터 빼본다면,
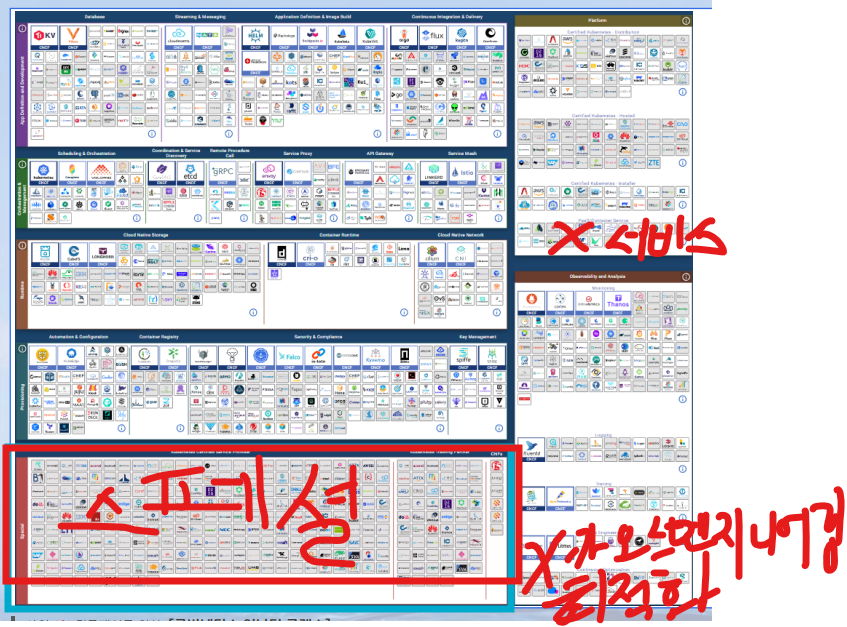
이미지 출처 - 인프런-쿠버네티스 어나더 클래스-Sprint 1, 2 (#실무기초 #설치 #배포 #Jenkins #Helm #ArgoCD)
- 스페셜 부분은 쿠버네티스 관련 업체와 교육 파트너이므로, 뺀다.
- 서비스, 카오스 엔지니어링, 최적화 부분은 메인이 아니므로 역시 뺀다.
이를 과감히 제거하고도 여전히 많다.
더욱 더 디테일하게 줄여보자.
기준은 다음과 같다.
- CNCF 프로젝트
- Graduated Projects
- Incubating Projects
- Sandbox Projects
- Archived Projects
- CNCF 멤버 제품
- 비 CNCF 멤버 제품
멤버냐 비 멤버의 차이는 CNCF에 회비를 내면서 제품 홍보나 등급별로 혜택을 받을 수 있나 없나의 차이고, 비 멤버라도 표준 생태계에 영향력이 있는 제품들이 많이 있다.
CNCF 프로젝트에서 Sandbox 는 실험단계이므로, 빼고,
Archived 는 비활성화 된 프로젝트이므로 역시 제한다.
그리고 Graduated 와 Incubating 에 있어서 성숙도가 높다고 우리가 많이 쓰고 있는 것은 아니다.
Graduated 이지만, 깃허브 Stars가 낮은 것은 제외했고,
Incubating 이지만, 깃허브 Stars가 높은 것츤 추가했다.
그리고 비 CNCF 멤버 제품이라도 Starts가 높은 것은 추가한다.
그리고 일프로님이 임의로 추가한 것도 있는데,
말이 많았지만, 결과로 보면 다음과 같아진다.
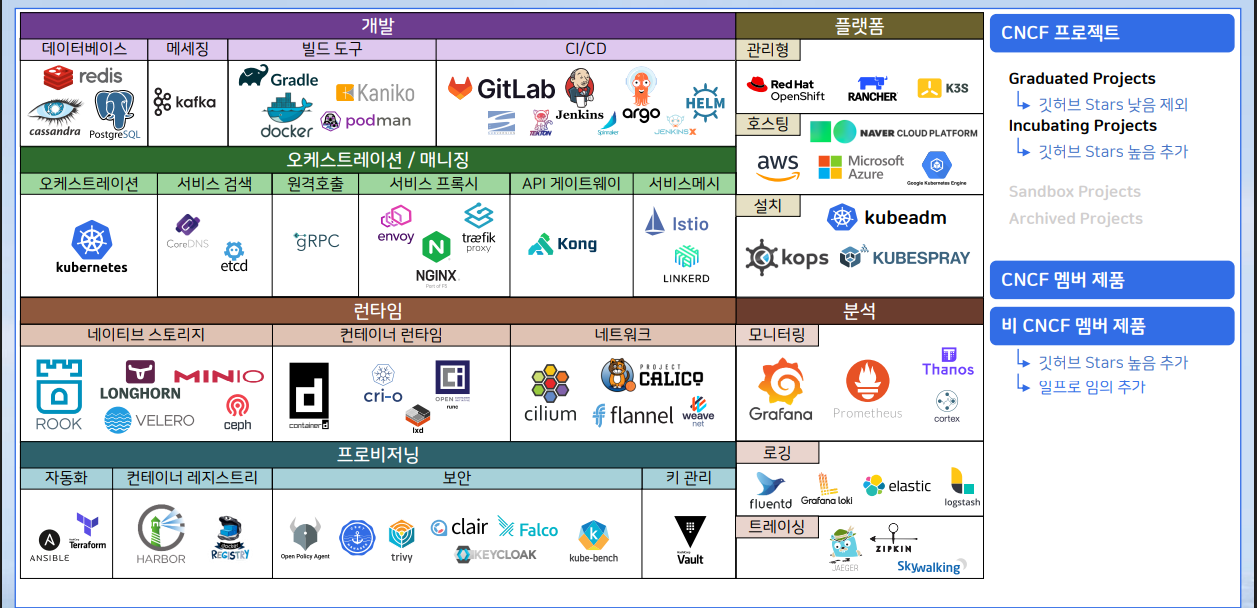
이미지 출처 - 인프런-쿠버네티스 어나더 클래스-Sprint 1, 2 (#실무기초 #설치 #배포 #Jenkins #Helm #ArgoCD)
이렇게 많이 좁혀진다.
사실 CNCF를 졸업했고, 멤버가 어떻고는 중요하지 않다.
위의 것은 정말 많은 오픈소스 중에 대표이고, 처음엔 이것들만 집중해도 충분하다.(물론 이것도 적지 않다.)
카테고리를 간략히 설명하면,
- 개발 : 기존에 해왔던 App 개발에서 배포까지 써야되는 기술들이다.
- 오케스트레이션/매니징은 App을 마이크로 서비스로 만들 때 쓰면 좋은 기술들이다.
- 플랫폼과 런타임은 App을 클라우드로 올릴 때 주로 사용되는 기술들이다.
- 프로비저닝과 분석은 실제 프로젝트에서 써야하는 기술들이다.
만약에 프로젝트에서 App을 마이크로 서비스로 개발하고, 클라우드까지 올린다면 여기 카테고리들을 다 알아야된다.
요즘은 이러한 프로젝트가 대부분이다.
현재까진 편하진 않고, 불편하게 보인다.
이제 편해지는 얘기를 해보면,
쿠버네티스가 편한 이유 : 분석 카테고리의 모니터링과 로깅
결론은 다음과 같다.
- 개발과 모니터링 시스템이 서로 엮일 수 밖에 없는 구조
- 개발에서는 한번도 써보지 않은 (개발 시스템을 위한)모니터링 시스템을 만드는 구조
- 오픈시 개발 프로젝트와 서로 다른 범위의 App들을 모니터링하게 되는 구조
분석 카테고리의 모니터링과 로깅을 살펴보면
실제 프로젝트할 때에는 어려운 상황들이 많지만, Kubernetes를 사용하면 편해진다.
큰 규모의 개발 프로젝트를 하게되면 그만큼 장애 요소가 많으므로 프로젝트에 적합한 모니터링 시스템을 개발하는 경우가 생긴다.
그런데 모니터링 시스템을 개발하는데 많은 난관이 있다.
프로젝트 별로 하는 사람에 따라 케바케지만, 구조적으로 무조건 부딪히는 상황이 있다.
모니터링을 개발 하려면 개발 패키지에 에이전트를 심거나 개발 코드를 변경한다.
모니터링과 개발 시스템은 엮일 수 밖에 없는데, 성능 테스트시 개발 기능에 성능이 안 나오면 모니터링에 심은 에이전트를 의심하기도 한다.
이처럼 개발과 모니터링 시스템이 서로 엮일 수 밖에 없는 구조가 첫 번째이다.
그리고 모니터링 시스템은 개발 초반부터 개발자들이 써보고 불편한 점이나 주요 모니터링 포인트를 수용하면서 만들어지는 게 이상적인데 프로젝트가 같이 시작되니 처음엔 쓸 수가 없다.
그래서 개발자들은 로우 레벨로 로그나 성능을 찾아보면서 장애를 분석한다.
그리고 나중에 모니터링 시스템이 오픈이 되더라도 익숙한 방법이 있다보니 안 보게 되고,
개발에서는 한 번도 써보지 않은 개발 시스템을 위한 모니터링 시스템이 만들어지는 구조가 두번째다.
이처럼 개발과 모니터링은 각자의 산으로 가고 있는 상황에서 개발은 막판에 초기 계획이랑 달리 요구 사항들이 쏟아지면서 앱들이 추가되거나 빠질 수 있다.
근데 모니터링 시스템에 앱이 자동으로 인식되는 기능이 없을 수도 있고, 앱에 에이전트를 심는 것을 놓칠 수도 있다.
심지어 모니터링 프로젝트가 먼저 끝나거 개발자가 없을 수 있다.
그래서 오픈 시 개발 프로젝트와 서로 다른 범위의 앱들을 모니터링하게 되는 구조가 세 번째다.
아무리 좋은 모니터링 개발 인력이 있더라도 이런 구조적인 문제들 때문에 프로젝트가 힘들다.
하지만, 쿠버네티스 생태계에 있는 모니터링과 로깅 툴을 쓰면 이런 문제들이 다 해결된다.
모니터링 시스템은 개발 시스템과 서로 엮이지 않고,
개발 초기부터 바로 쓸 수 있고,
항상 앱이 자동으로 반영되는 구조가 된다.
쿠버네티스를 사용하면, 아래와 같이 해결된다.
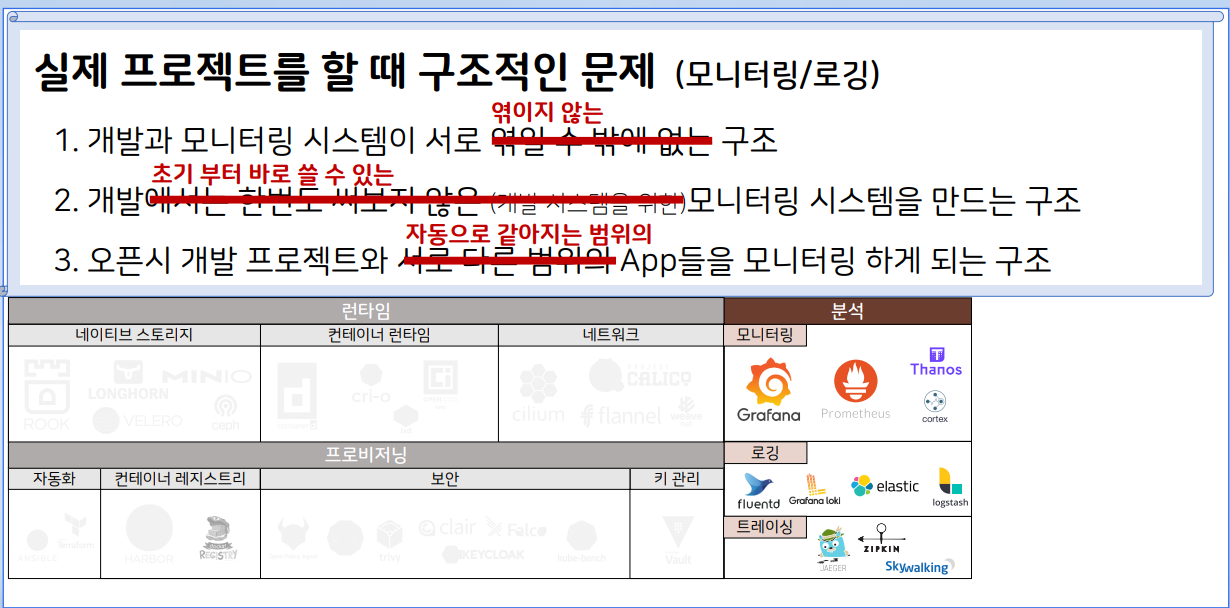
이미지 출처 - 인프런-쿠버네티스 어나더 클래스-Sprint 1, 2 (#실무기초 #설치 #배포 #Jenkins #Helm #ArgoCD)
2-2. 모니터링 설치 - Loki-Stack(🖥️실습포함)
이전에 설치했던 것을 통해서 다음과 같은 명령어를 사용하여, 설치해보자.
Github(k8s-1pro)에서 Prometheus(with Grafana), Loki-Stack yaml 다운로드
[root@k8s-master ~]# yum -y install git
# 로컬 저장소 생성
[root@k8s-master ~]# git init monitoring
[root@k8s-master ~]# git config --global init.defaultBranch main
[root@k8s-master ~]# cd monitoring
# remote 추가 ([root@k8s-master monitoring]#)
[root@k8s-master ~]# git remote add -f origin https://github.com/k8s-1pro/install.git
# sparse checkout 설정
[root@k8s-master ~]# git config core.sparseCheckout true
[root@k8s-master ~]# echo "ground/k8s-1.27/prometheus-2.44.0" >> .git/info/sparse-checkout
[root@k8s-master ~]# echo "ground/k8s-1.27/loki-stack-2.6.1" >> .git/info/sparse-checkout
# 다운로드
[root@k8s-master ~]# git pull origin mainPrometheus**(with Grafana) 설치
# 설치 ([root@k8s-master monitoring]#)
[root@k8s-master ~]# kubectl apply --server-side -f ground/k8s-1.27/prometheus-2.44.0/manifests/setup
[root@k8s-master ~]# kubectl wait --for condition=Established --all CustomResourceDefinition --namespace=monitoring
[root@k8s-master ~]# kubectl apply -f ground/k8s-1.27/prometheus-2.44.0/manifests
# 설치 확인 ([root@k8s-master]#)
[root@k8s-master ~]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
grafana-646b5d5dd8-vdv86 1/1 Running 0 52s
kube-state-metrics-86c66b4fcd-qnn6q 3/3 Running 0 52s
node-exporter-2rd9l 2/2 Running 0 51s
prometheus-adapter-648959cd84-w5cjz 1/1 Running 0 51s
prometheus-k8s-0 1/2 Running 0 25s
prometheus-operator-7ff88bdb95-dvczs 2/2 Running 0 51s
Loki-Stack 설치
# 설치 ([root@k8s-master monitoring]#)
[root@k8s-master ~]# kubectl apply -f ground/k8s-1.27/loki-stack-2.6.1
# 설치 확인
[root@k8s-master ~]# kubectl get pods -n loki-stack
NAME READY STATUS RESTARTS AGE
loki-stack-0 1/1 Running 0 50s
loki-stack-promtail-54pdf 1/1 Running 0 50s
Grafana 접속
- 접속 URL : http://192.168.56.30:30001
- 로그인 : id : admin / pw : admin
- 확인 결과
위 Grafana에 Prometheus는 설치할 떄 자동 연결이 돼 있고,
Loki-Stack 은 추가로 연결해야 한다.
아래에서 확인하자.
Grafana에서 Loki-Stack 연결
- Connect data : Home > Connections > Connect data
- 검색에
[loki]입력 후 항목 클릭
Loki를 클릭하자.
우측 상단의 Create a Loki data source 를 클릭한다.
그리고 아래의 화면과 같이 해준다.
URL에 내용 입력 : http://loki-stack.loki-stack:3100
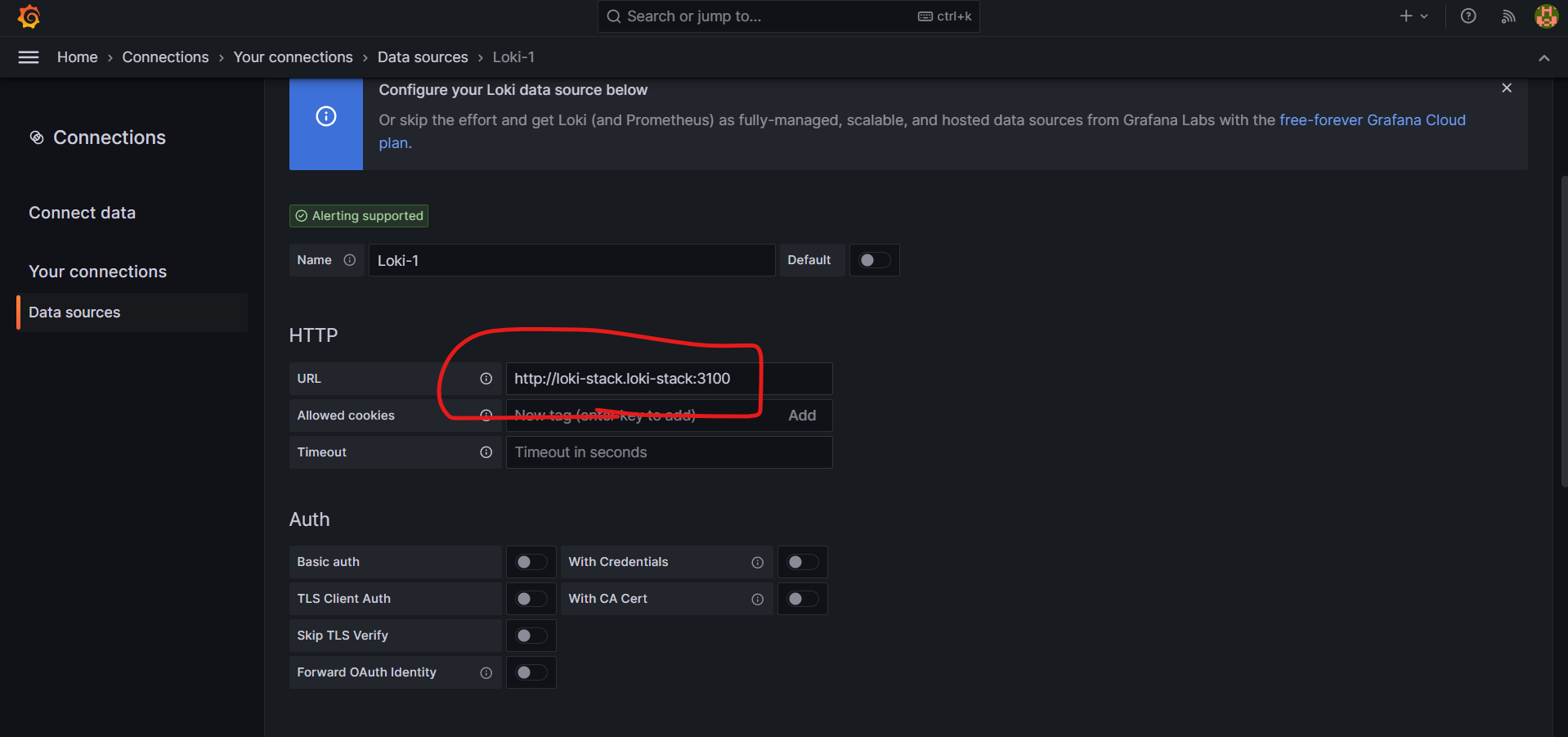
그리고 아래와 같이 하단에 Save & test 를 클릭해준다.
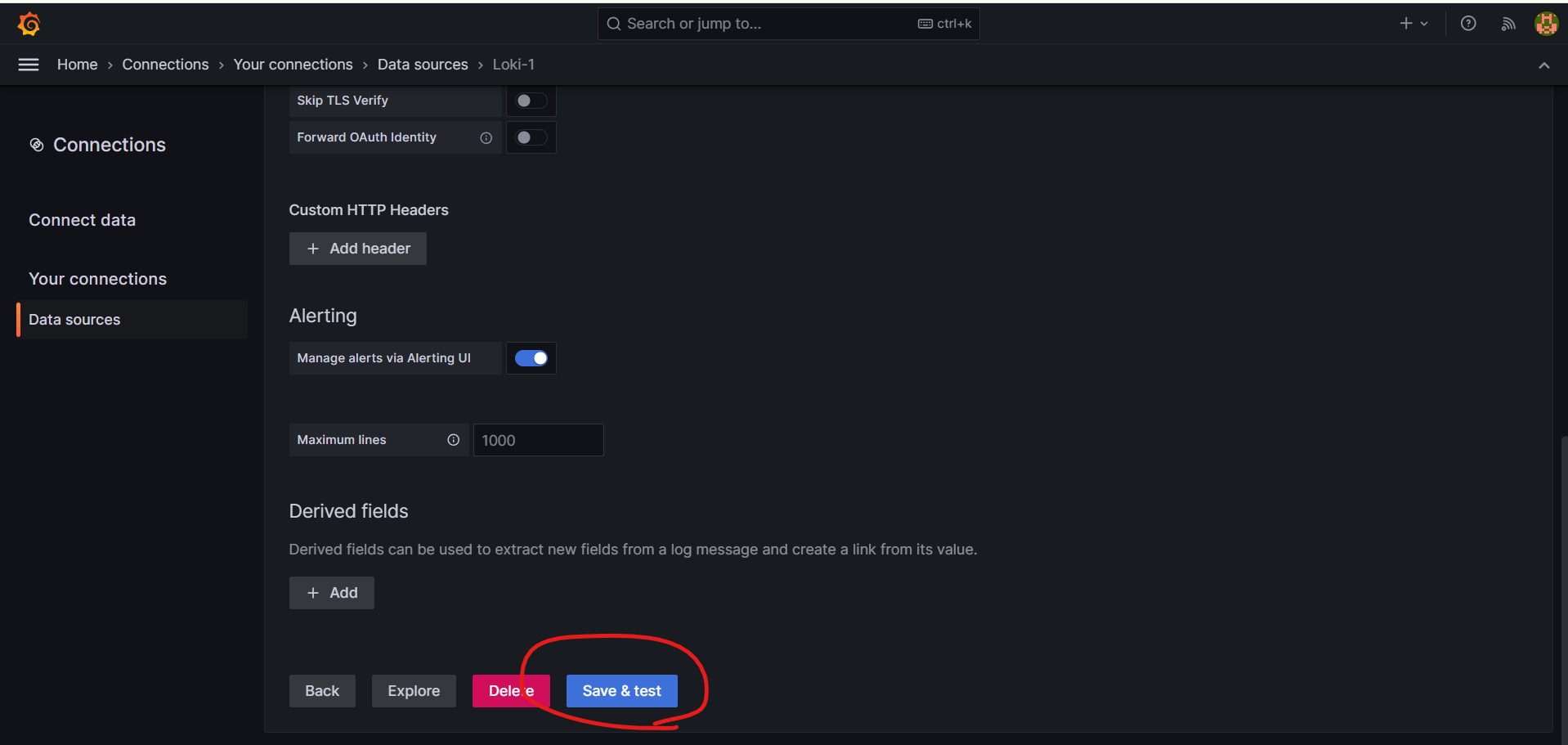
※참고 설치를 삭제해야 할 경우
- Prometheus(with Grafana), Loki-stack 삭제
k8s-master 에 Console 접속 후 아래 명령 실행
[root@k8s-master ~]# cd monitoring
# Prometheus 삭제
[root@k8s-master ~]# kubectl delete --ignore-not-found=true -f ground/k8s-1.27/prometheus-2.44.0/manifests -f ground/k8s-1.27/prometheus-2.44.0/manifests/setup
# Loki-stack 삭제
[root@k8s-master ~]# kubectl delete -f ground/k8s-1.27/loki-stack-2.6.1그리고 Dashboards - Default에 들어가보면, 많은 모니터링 화면들이 만들어져 있다.
아래에서 Kubernetes / Networking / Pod 를 선택하면 아래와 같이 나온다.
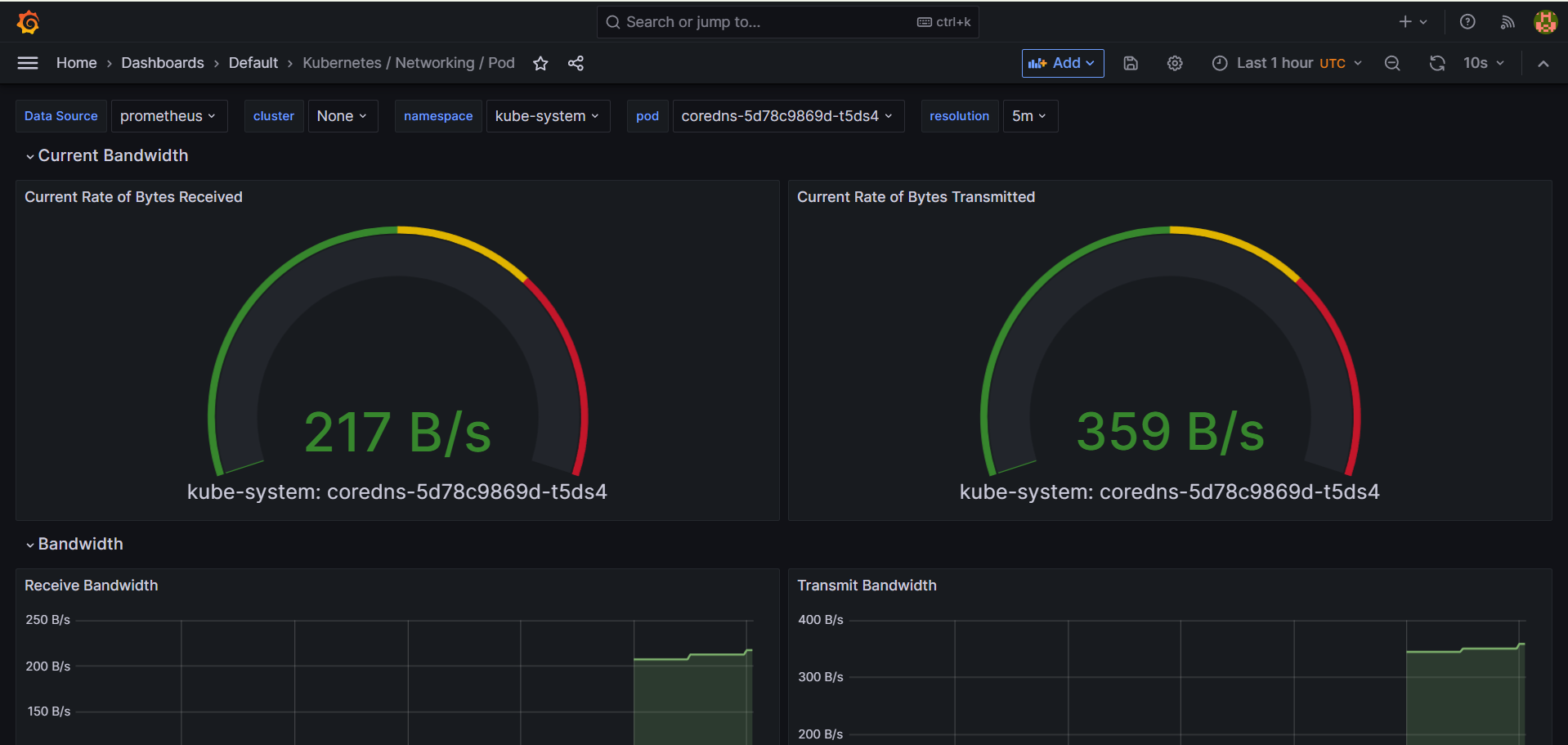
하나씩 선택해보면 된다.
그리고 UI에가 쉬워서 보고싶은 지표를 통해 화면을 쉽게 만들 수 있다.
아래는 클러스터링 모니터링이다.
(켠지 얼마 되지 않았다 데이터가 없다.)
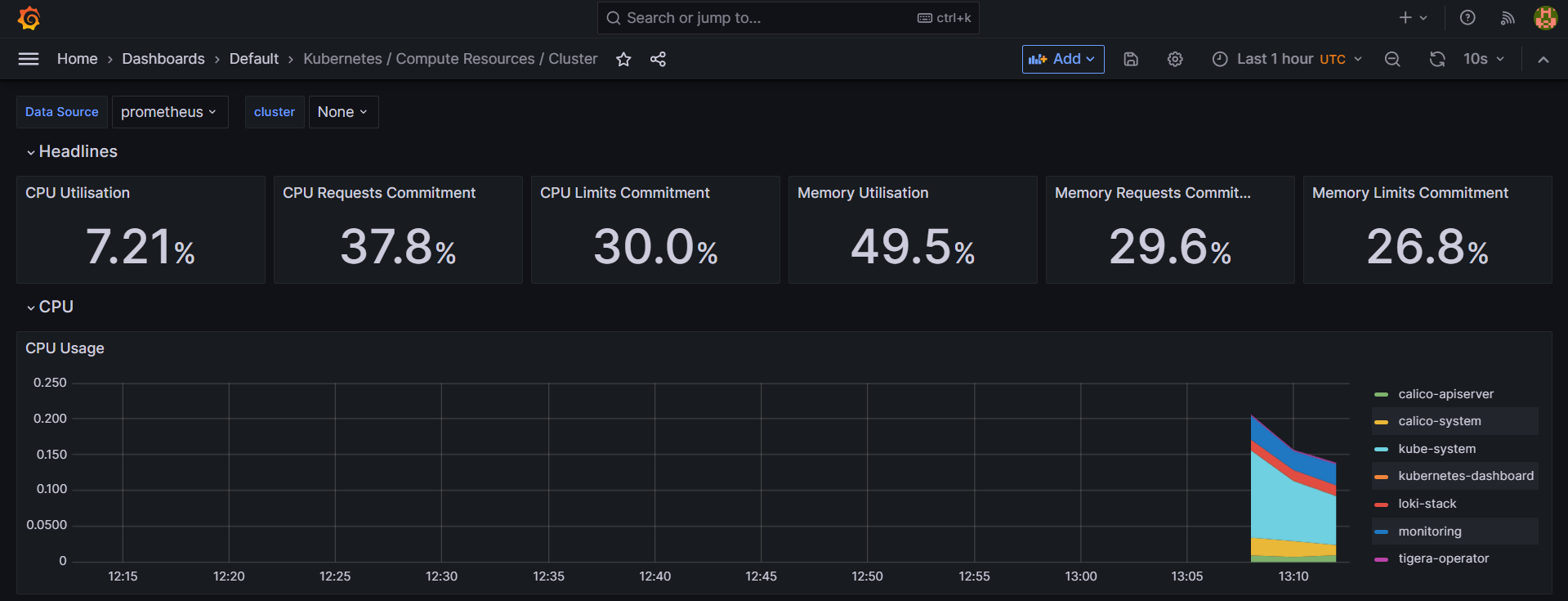
그리고 아래와 같이 마음에 드는 차트가 있으면 복사를 해서 새로운 대시보드로 만들 수도 있다.
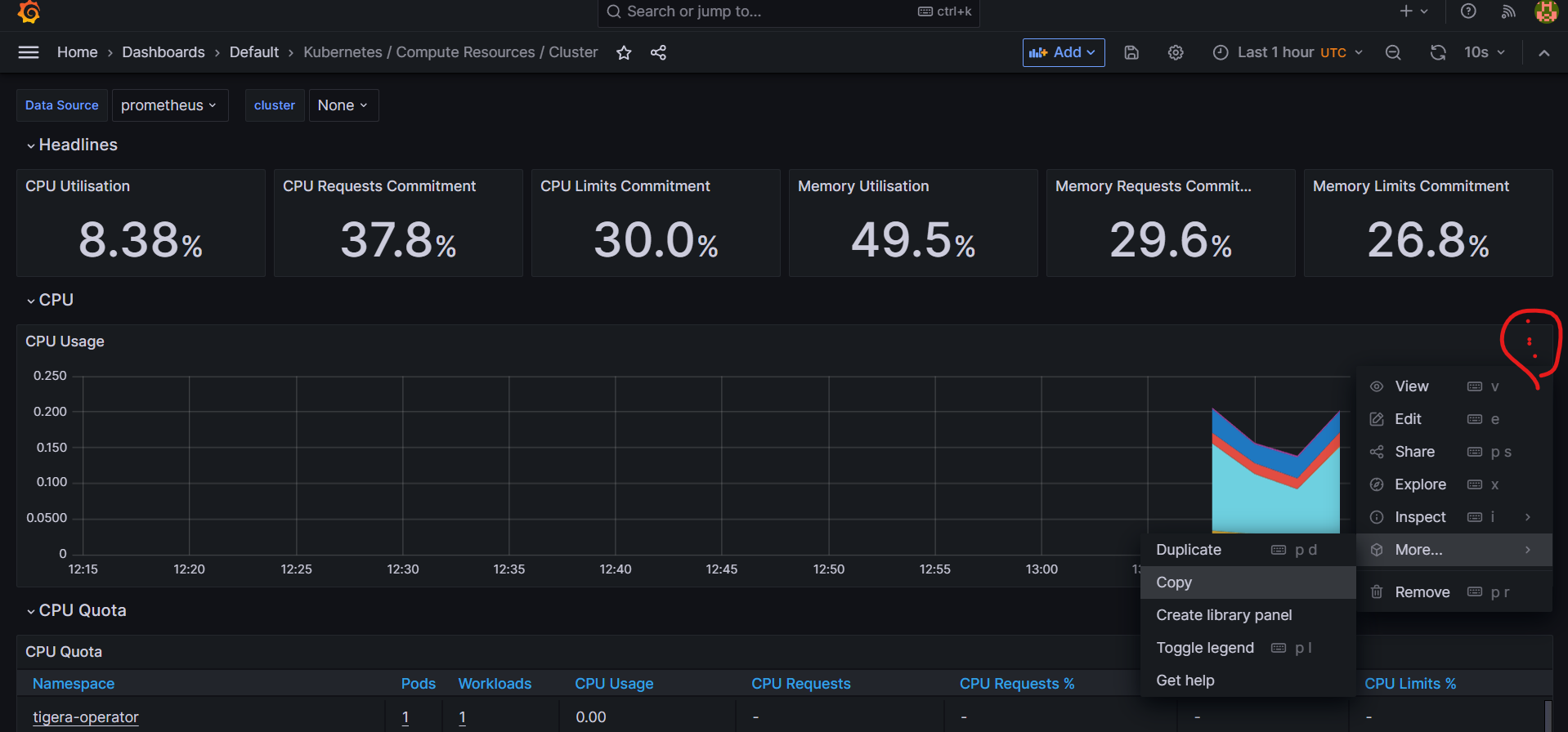
즉, 내가 보고싶은 화면들만 모아볼 수 있다는 것이다.
프로메테우스 메트릭을 별도로 공부할 필요없이 UI가 쉽게 되어있어 어떻게 써야할지 감이 온다.
그리고 그라파나 사이트에서 대시보드들을 더 받을 수 있다.
적용 방법은 아래와 같다.
그라파나 대시보드 사이트 에 접속한다.
사이트 링크 : https://grafana.com/grafana/dashboards/
강의따라 Node Exporter 를 확인해보자.
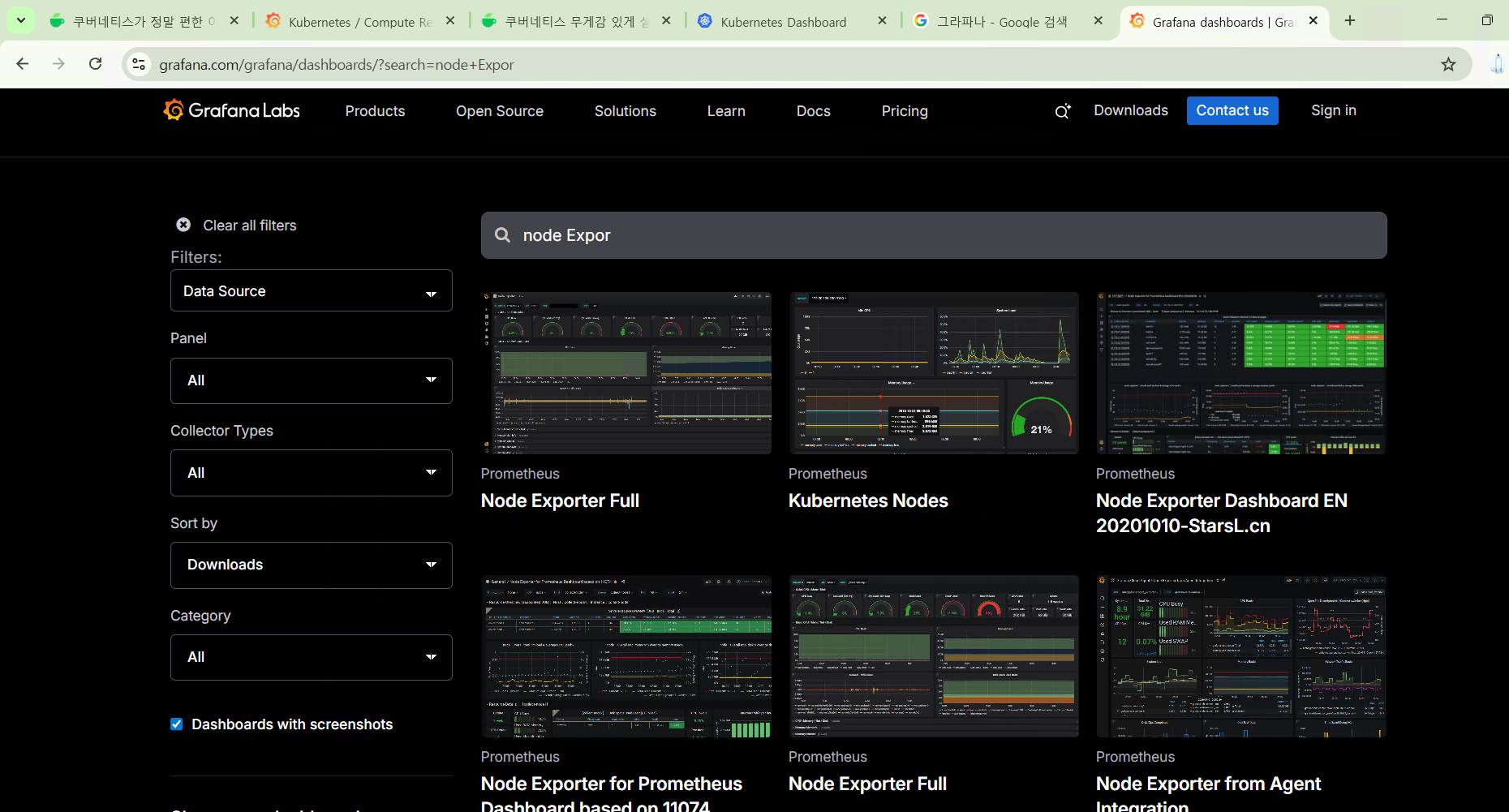
해당 대시보드의 경우, 마스터, 워커 노드의 VM의 세부 정보를 확인할 수 있는 화면을 제공한다.
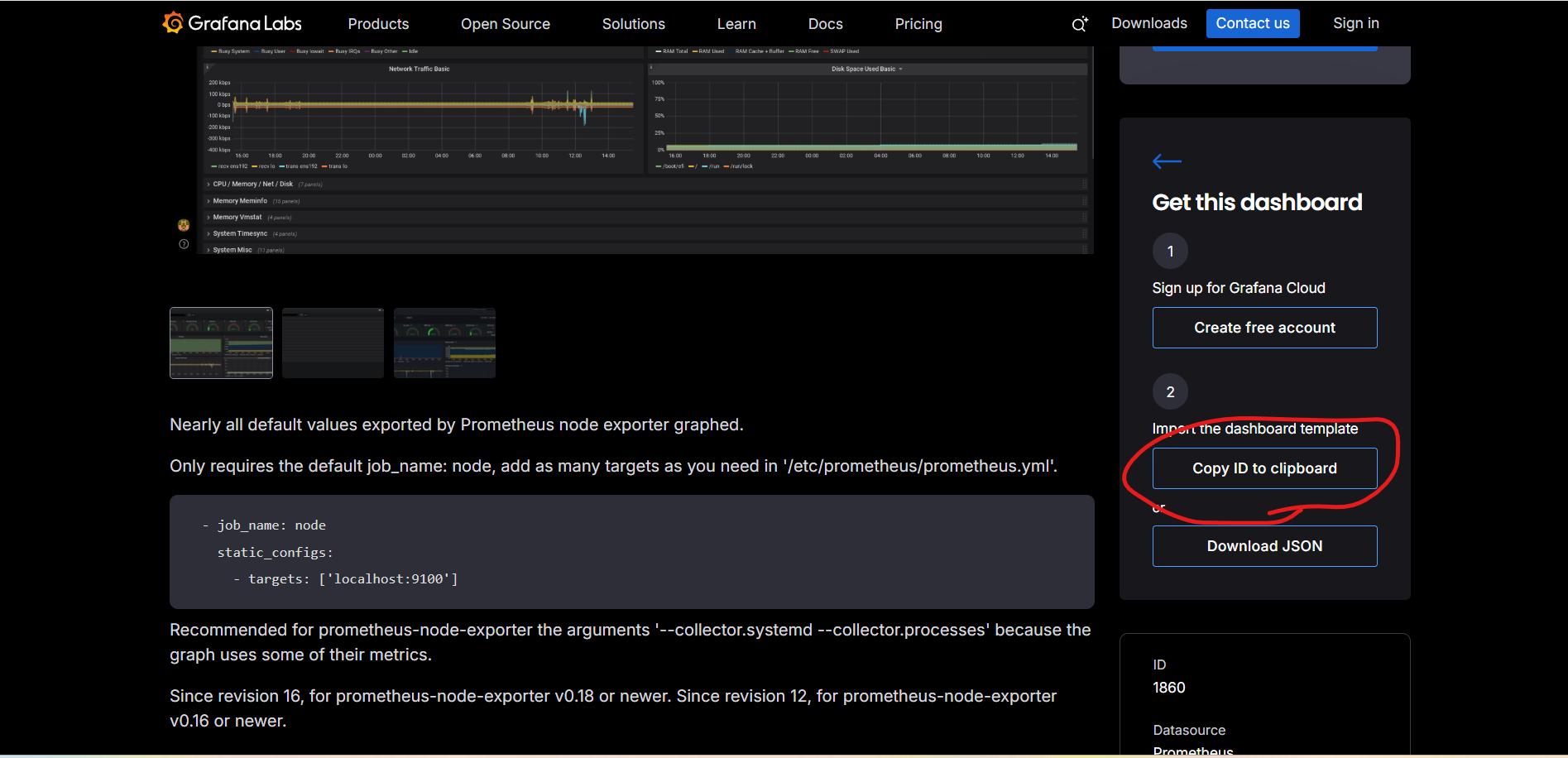
클릭 후, Copy ID to clipboard 에서 대시보드 id를 복사한다.
그라파나 홈에서 아래의 + 표시에서 Import dashboard 를 클릭한다.
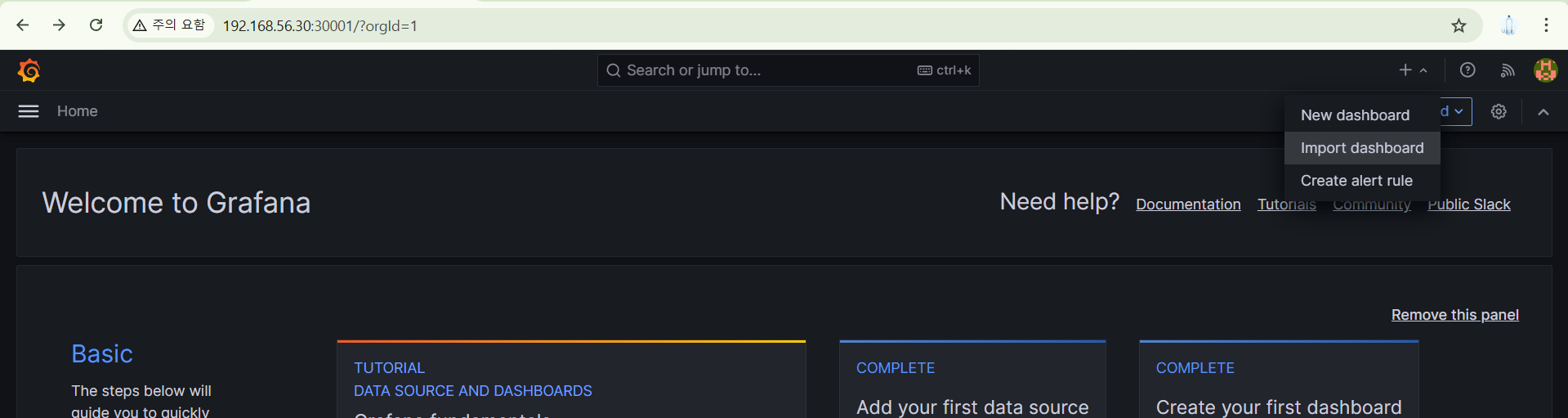
그리고 아까 복사한 ID를 넣고, Load한다.
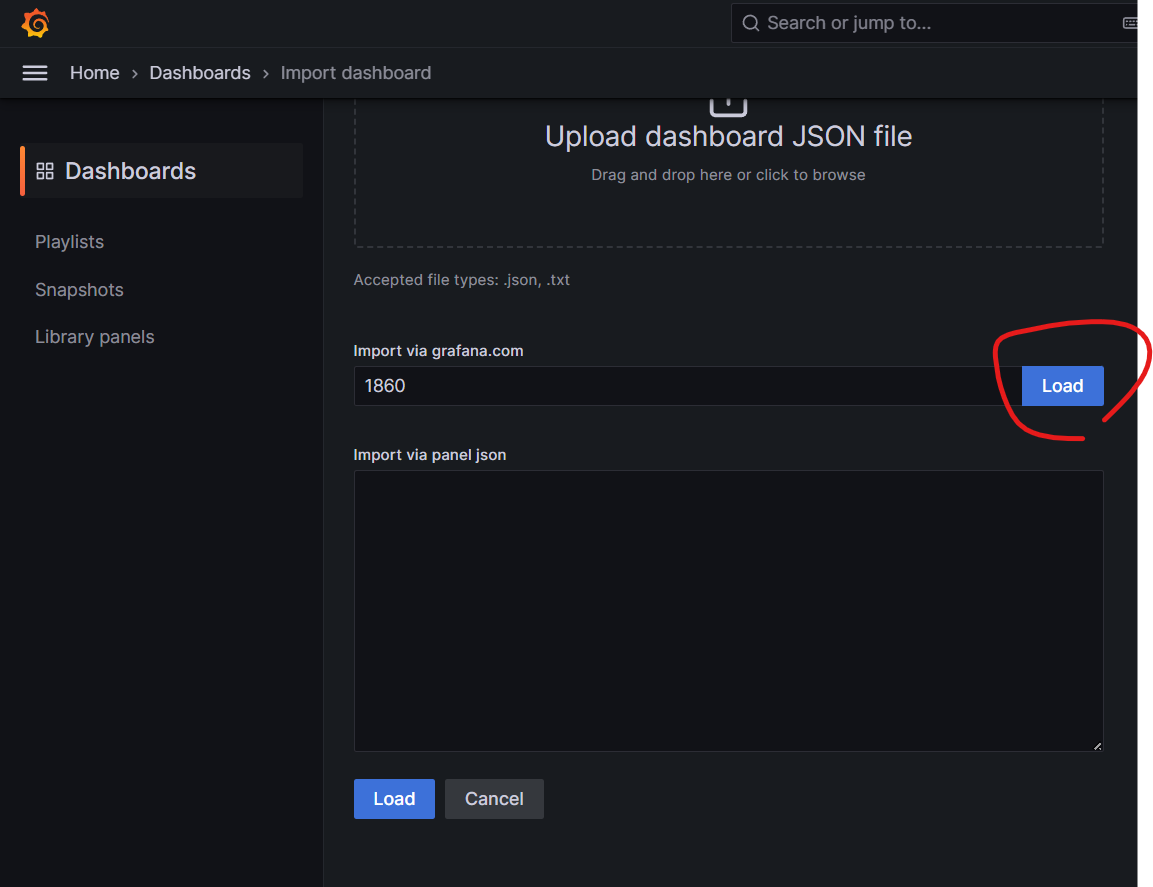
Load 후, Import 해주면 된다.
그러면, 아래와 같이 나온다.
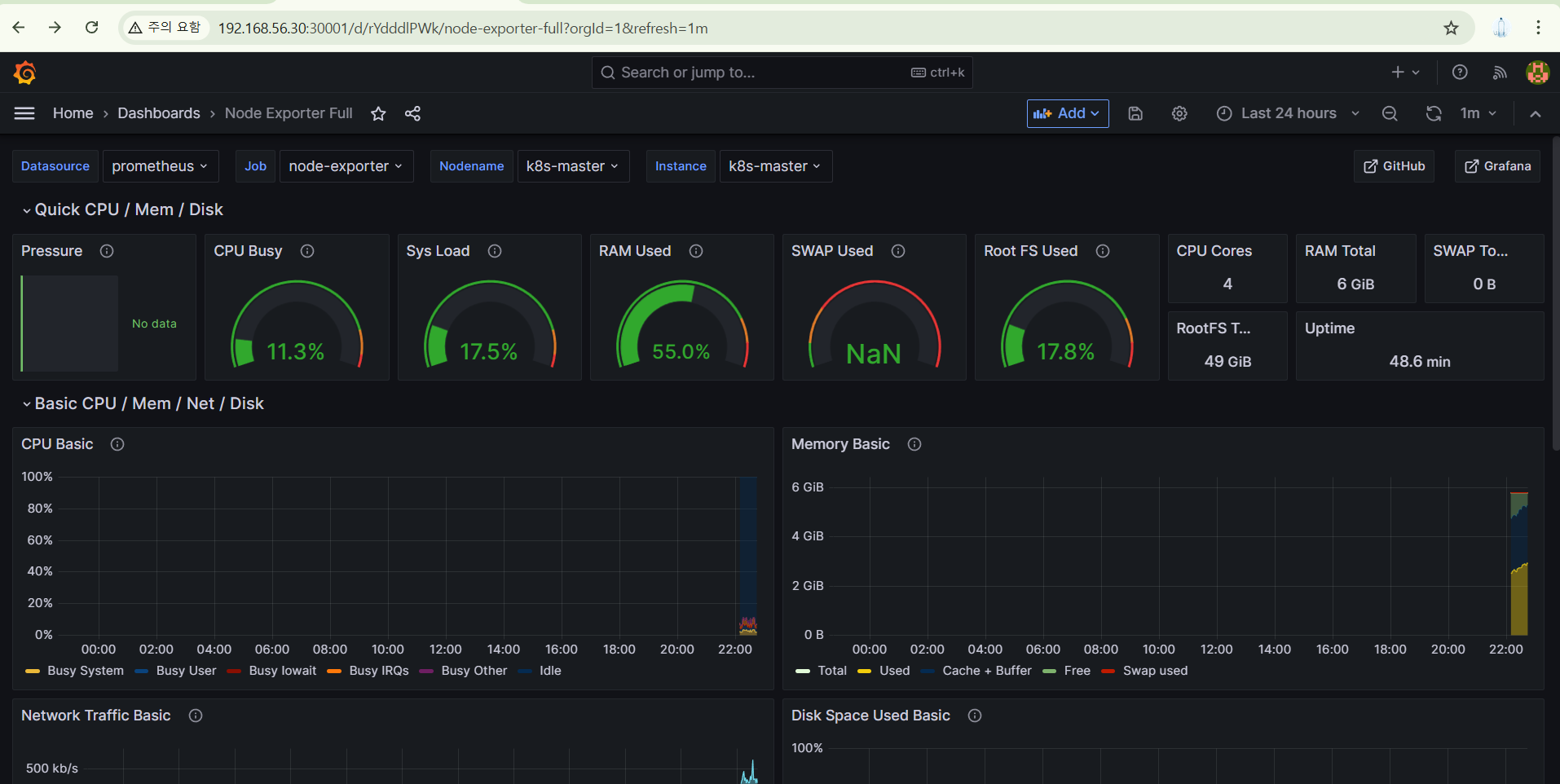
밑으로 더 내리면, 아래와 같은 정보를 볼 수 있다.
이제 App을 배포해보자.
yaml 샘플은 사이트에 있다.
기존에 설치했던 쿠버네티스 대시보드에 yaml을 입력하면 된다.
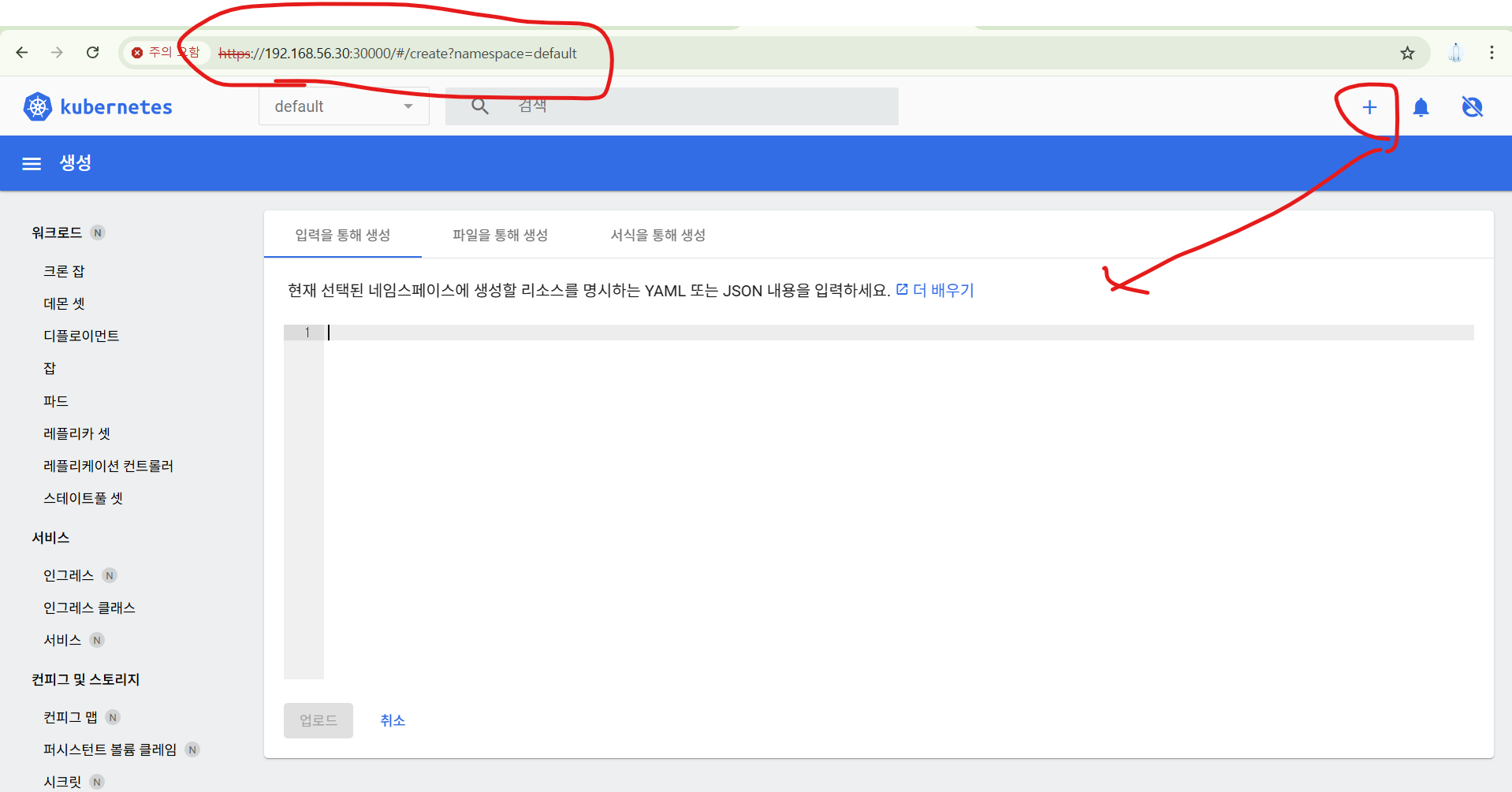
복붙 후, 업로드를 하면 된다.
그럼 아래와 같이 실행 대기 중이다.
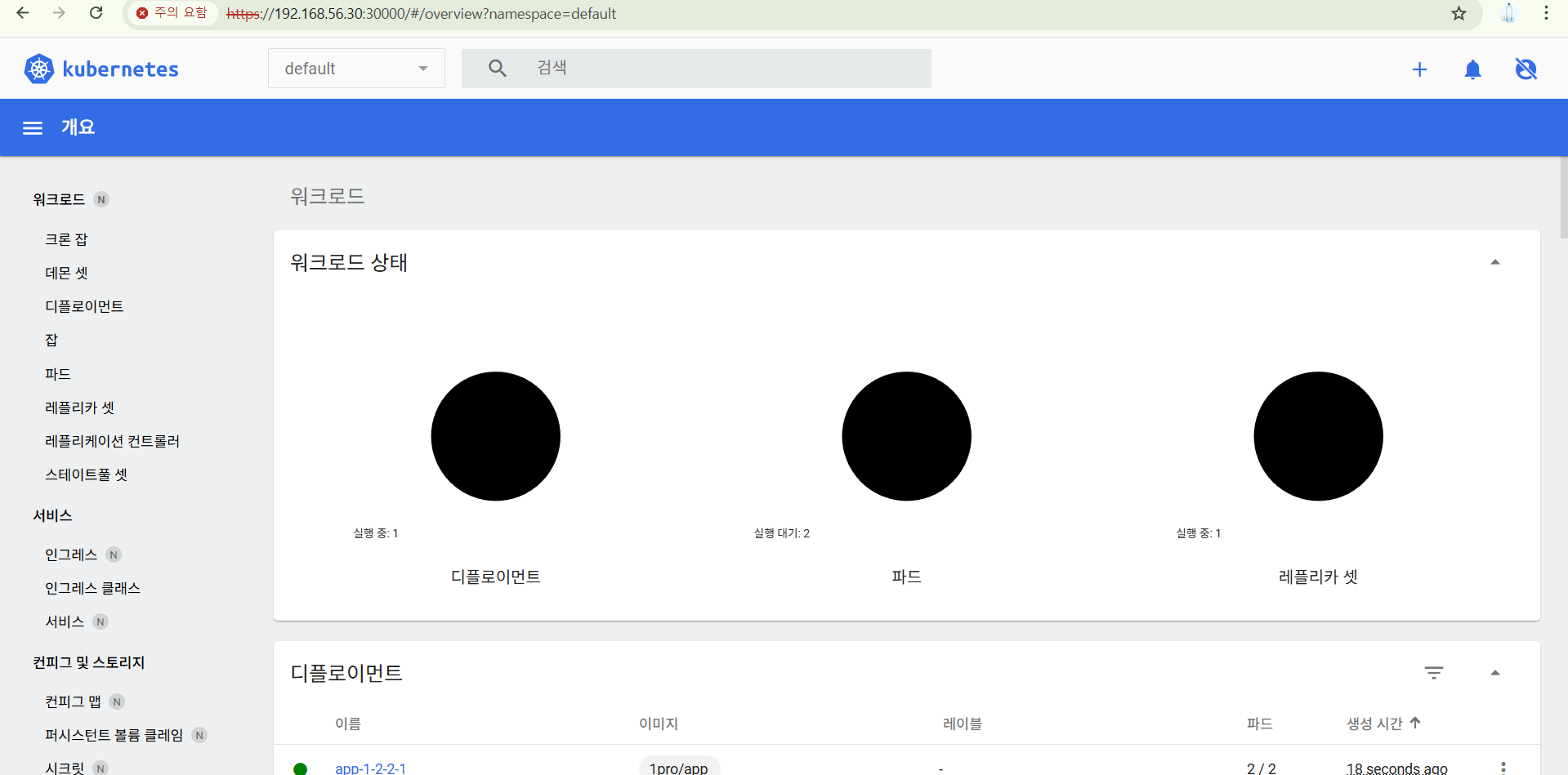
파드 확인
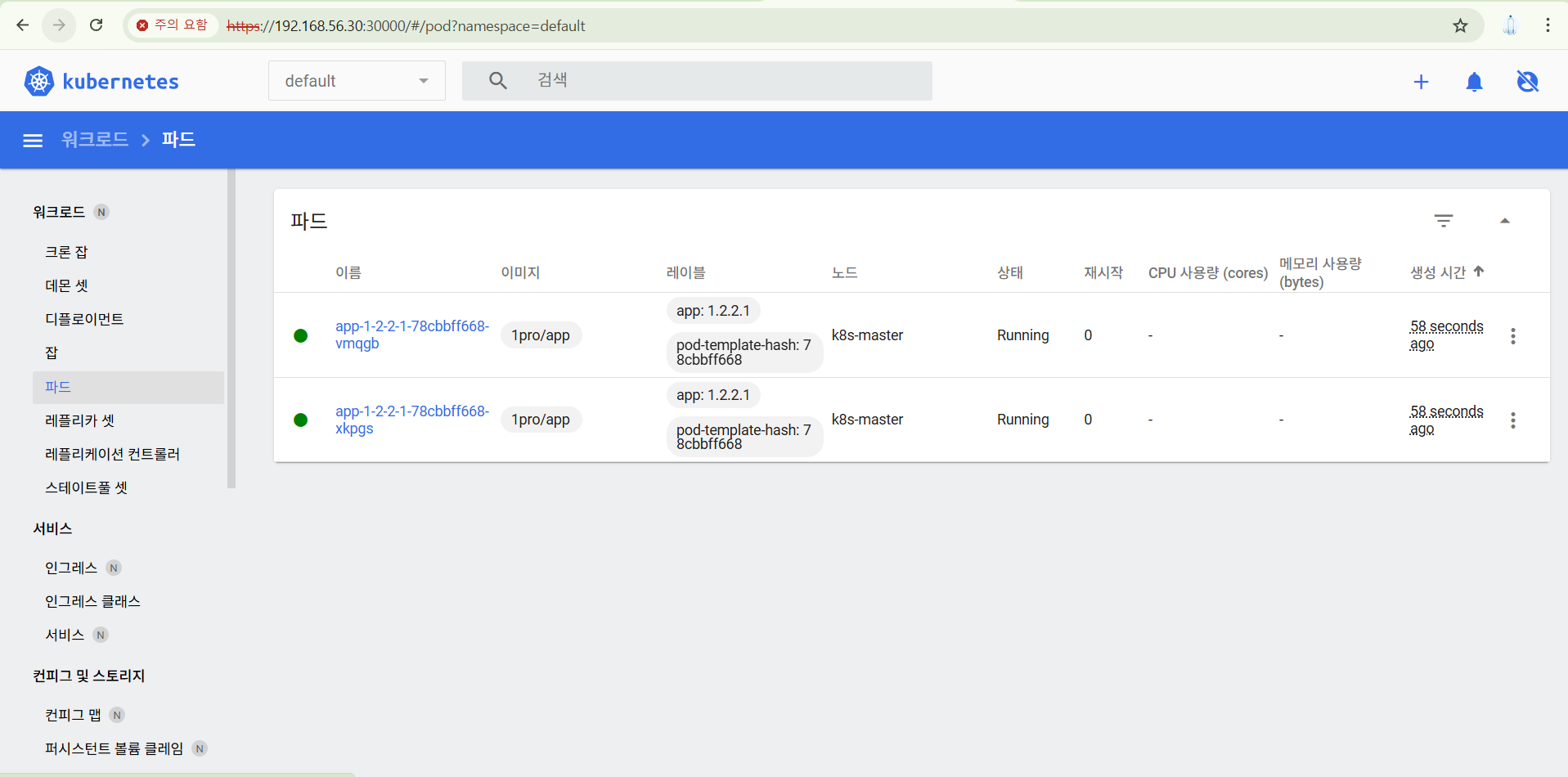
이제 그라파나에 가서 대시보드를 확인해보자.Kubernetes / Compute Resources / Pod 에서, namespace를 default로 바꾸면,
내가 띄운 App 정보가 자동으로 보인다.
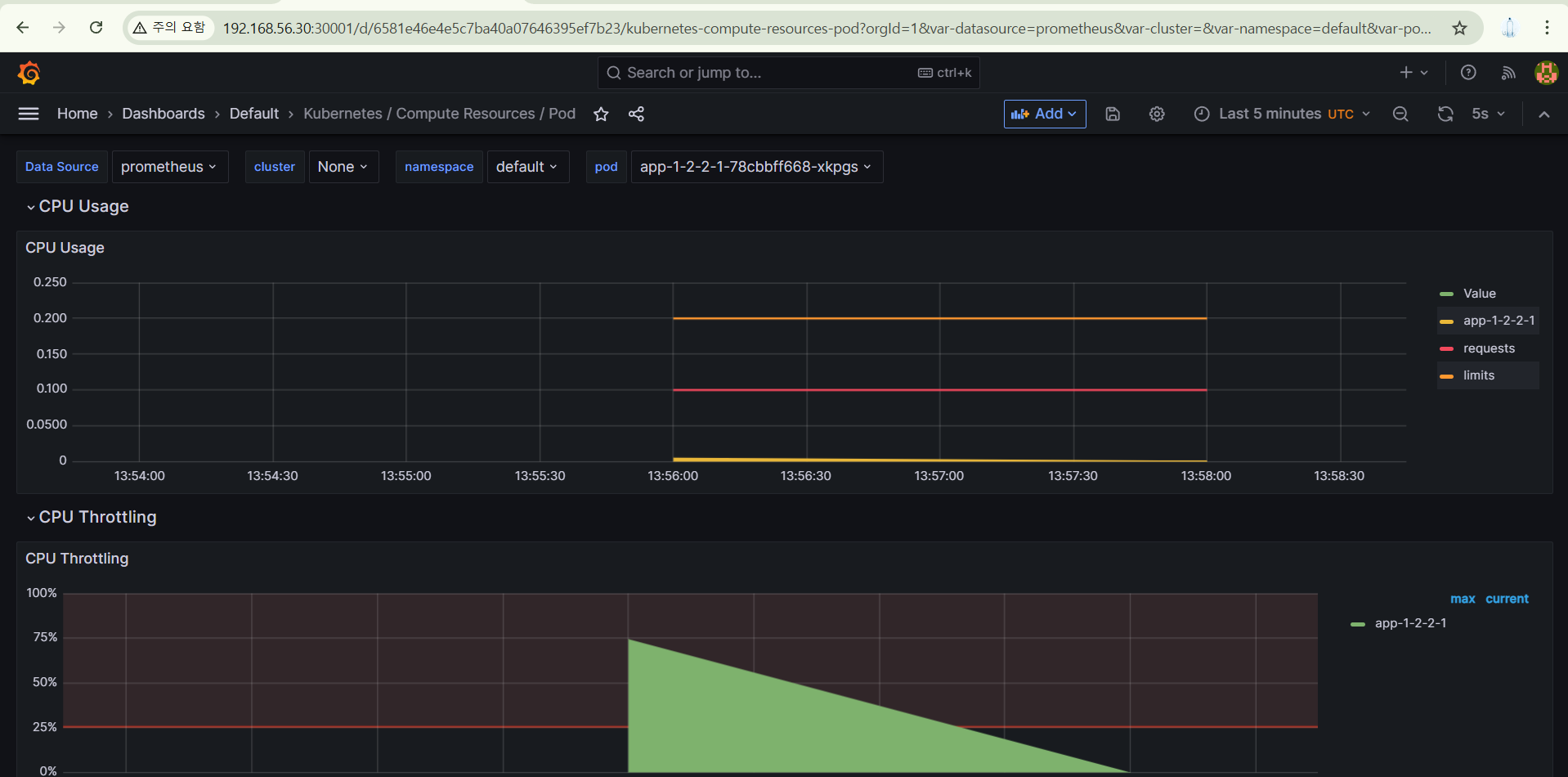
아래로 보면, App의 CPU와 모니터링 정보가 나오는 게 보인다.
그리고 Explore 에서 Loki를 접속하면, App에 대한 로그도 볼 수 있다.
Loki로 확인하기
Label browser을 누르면, app에서 내가 만든 App 이름이 나온다.
그리고 더 디테일하게 pod를 눌러서도 확인할 수 있다.
그런데 이번에는 모든 로그를 다 확인해보자.
그러면 아래에서 로그를 확인할 수 있다
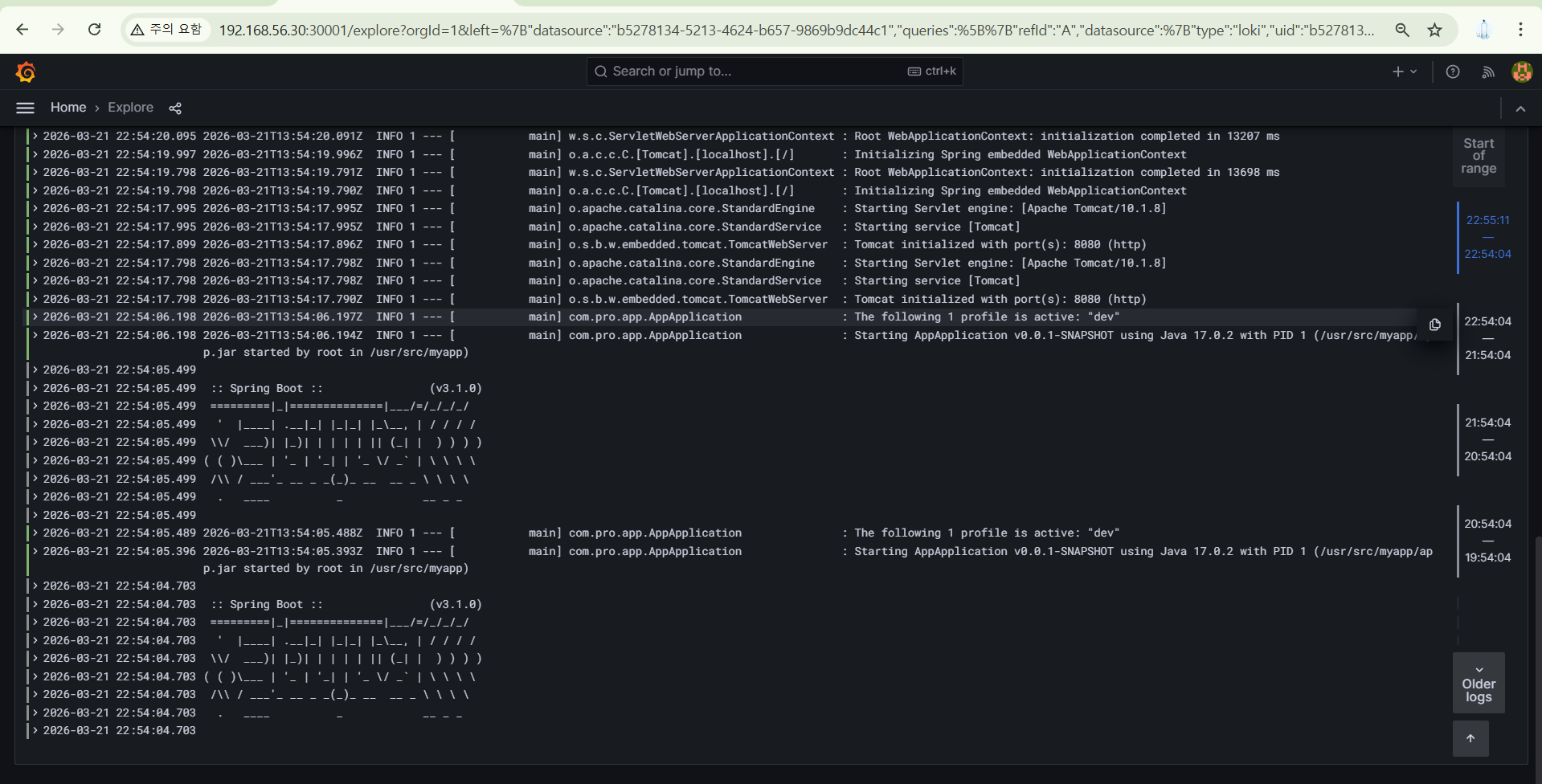
이처럼 앱이 새로 만들어져 있어도 추가 동작 없이 다 자동화로 돼어있어서 프로젝트 구축을 더 편하게 해준다.
이러한 부분이 다 쿠버네티스 아키텍처 표준이 있기 때문이다.
나중에 CSI 라는 단어를 배우게 될 것인데, 쿠버네티스 표준 기술 중 하나이다.
이처럼 표준은 편하다.
2-3. 쿠버네티스 대표 기능 - Traffic Routing, Self-Healing, AutoScaling, RollingUpdate(🖥️실습포함)
현재 파드는 두 개로 App이 이중화 되어있다.
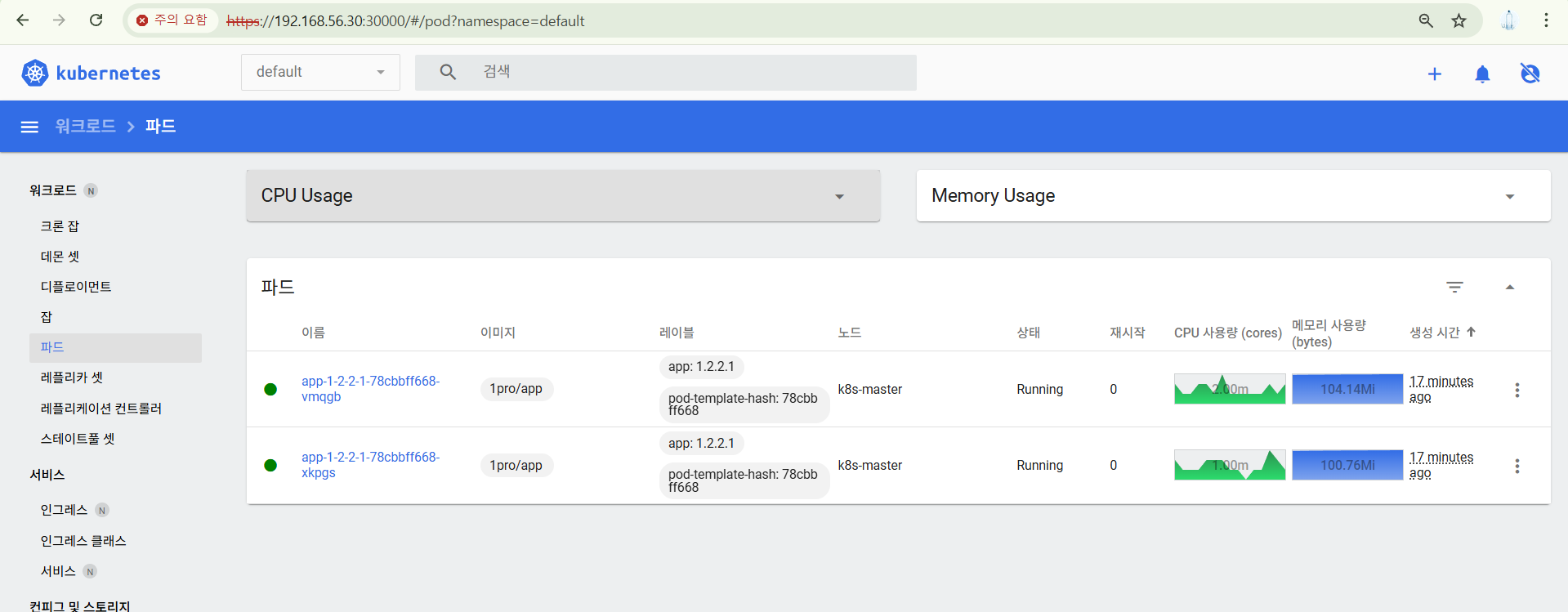
앱을 호출하면 두 파드에 트래픽이 골고루 들어가진다.
그리고 트래픽을 많이 보내어 부하가 생기면 파드가 늘어나는 설정이 되어 있다.
- 스케일링 설정이 2개에서 4개까지 늘어나게 되어있다.
- CPU 기준 평균 40%가 늘면 늘어난다.
App에 지속적으로 트래픽이 골고루 발생되는지 확인해본다.
아래 명령어를 사용한다.
마스터 노드에 들어가서 사용하자.
2초 간격으로 어느 파드에 트래픽을 발생시키는지 hostname이 출력되는 것을 통해 확인할 수 있다.
[root@k8s-master monitoring]# while true; do curl http://192.168.56.30:31221/hostname; sleep 2; echo ''; done;
app-1-2-2-1-78cbbff668-xkpgs
app-1-2-2-1-78cbbff668-xkpgs
app-1-2-2-1-78cbbff668-xkpgs
app-1-2-2-1-78cbbff668-xkpgs
app-1-2-2-1-78cbbff668-vmqgb
app-1-2-2-1-78cbbff668-vmqgb
app-1-2-2-1-78cbbff668-vmqgb
app-1-2-2-1-78cbbff668-xkpgs
app-1-2-2-1-78cbbff668-xkpgs
app-1-2-2-1-78cbbff668-xkpgs
app-1-2-2-1-78cbbff668-xkpgs
app-1-2-2-1-78cbbff668-xkpgs
그리고 쿠버네티스 대시보드에서 파드를 하나 죽이면, 파드가 다시 뜰 때까지 하나의 파드에만 트래픽을 보내서 처리한다.
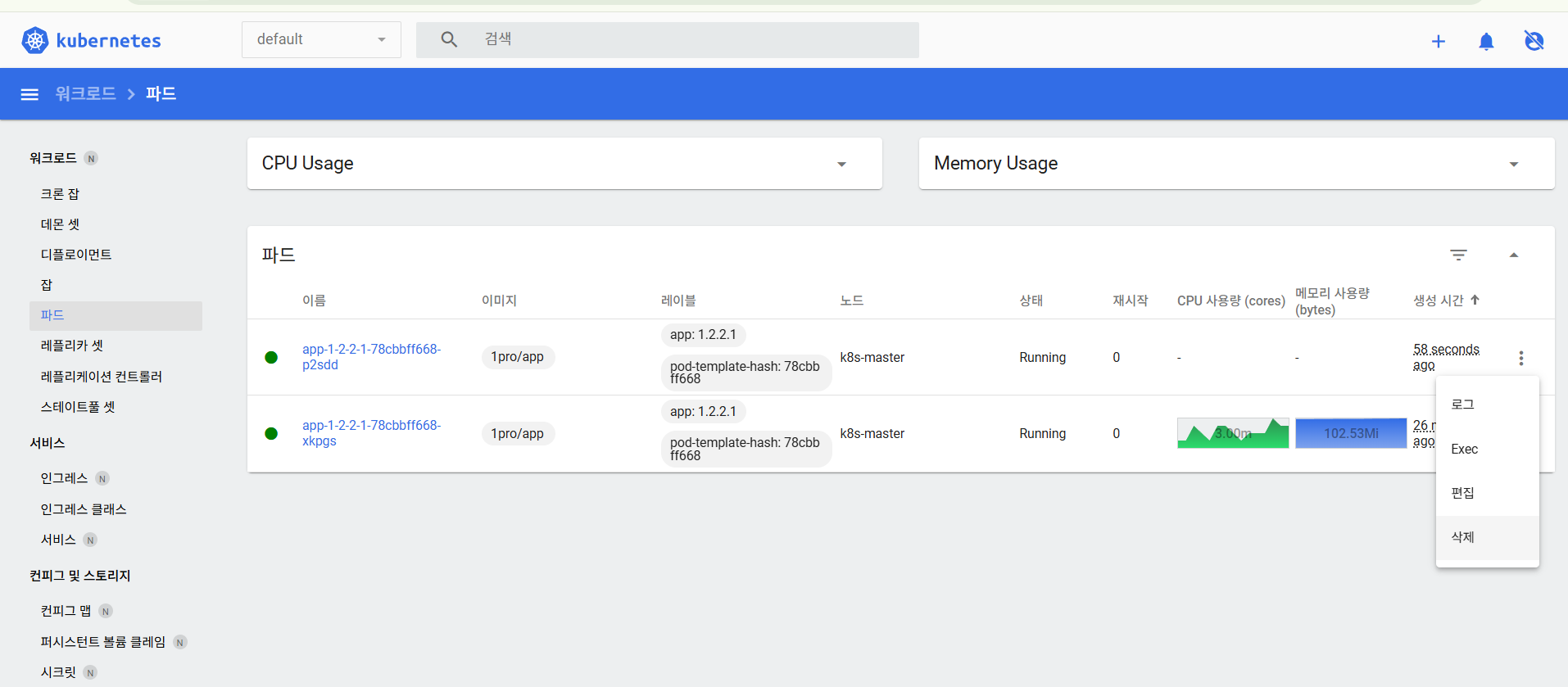
로그를 확인하면, 하나의 파드에만 트래픽을 보내는 것을 확인할 수 있다.
일반적으로 그냥 파드가 죽을 일보다는 내부적으로 메모리가 너무 증가해서 파드가 죽는 경우가 많은데, 아래 명령어를 통해서 메모리 릭이 나도록 되어있다.
(참고로 10~20초 정도 걸린다.)
[root@k8s-master ~]# curl 192.168.56.30:31221/memory-leak파드가 재시작된 것을 확인할 수 있다.
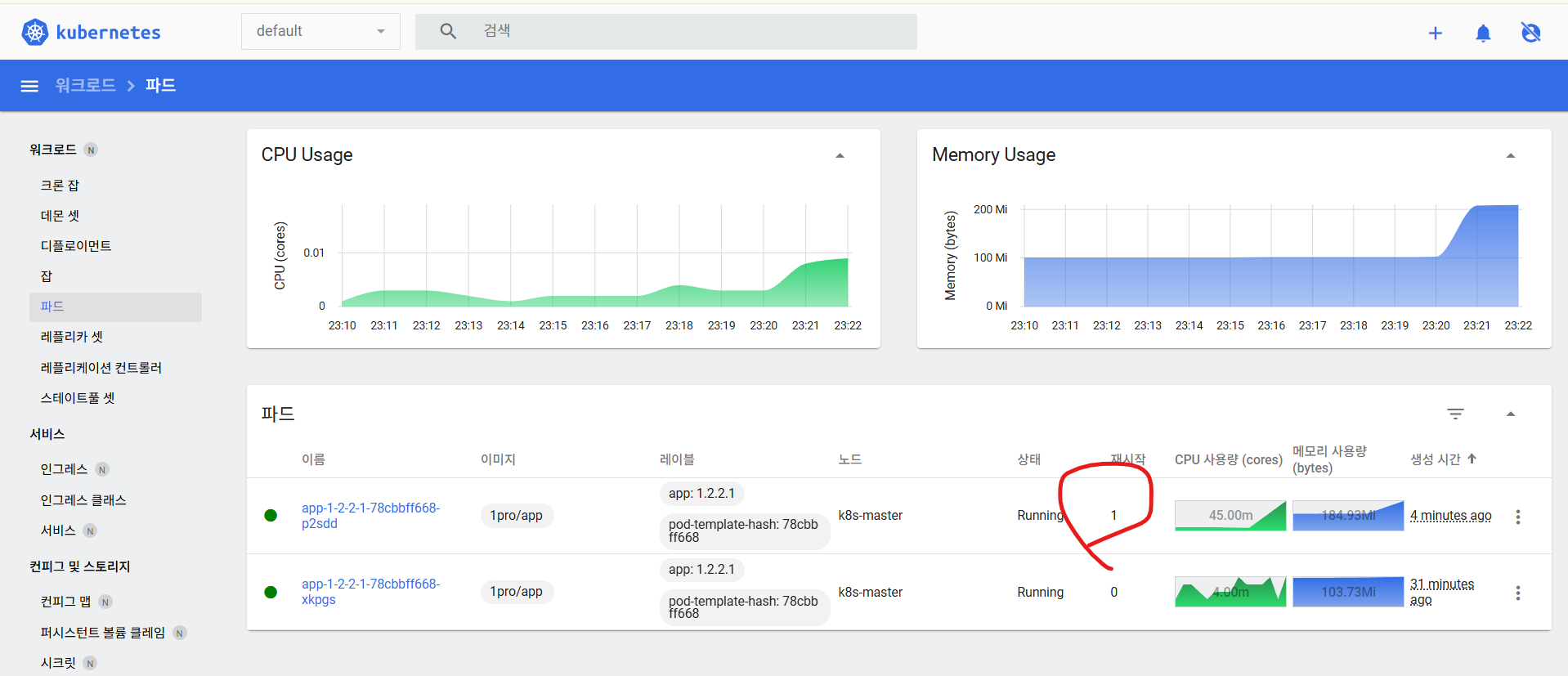
그리고 그라파나에 접속해서 재시작을 한 파드에 대한 지표를 통해서 메모리가 높아진 구간이 없는지 확인하고, Loki를 통해 로그를 확인할 수 있다.
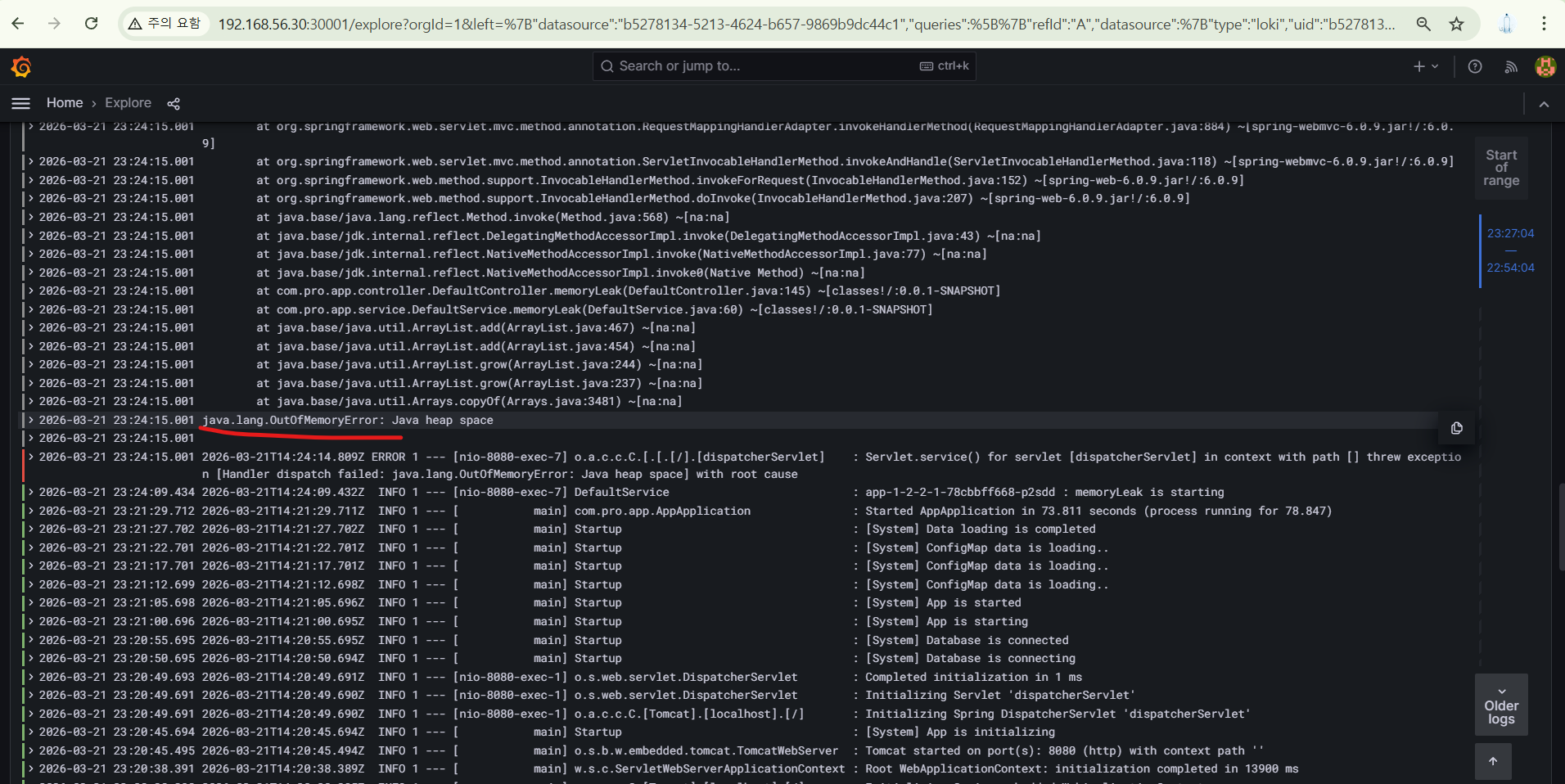
그리고 내용을 통해서 원인을 파악하면 된다.
아래 로그에서는 OOM(Out Of Memory)가 발생했음을 확인할 수 있다.
다음으로 App에 부하를 주어서 4개까지 늘어나는지 확인해보자.
아래 명령어를 입력하자.
[root@k8s-master ~]# curl 192.168.56.30:31221/cpu-load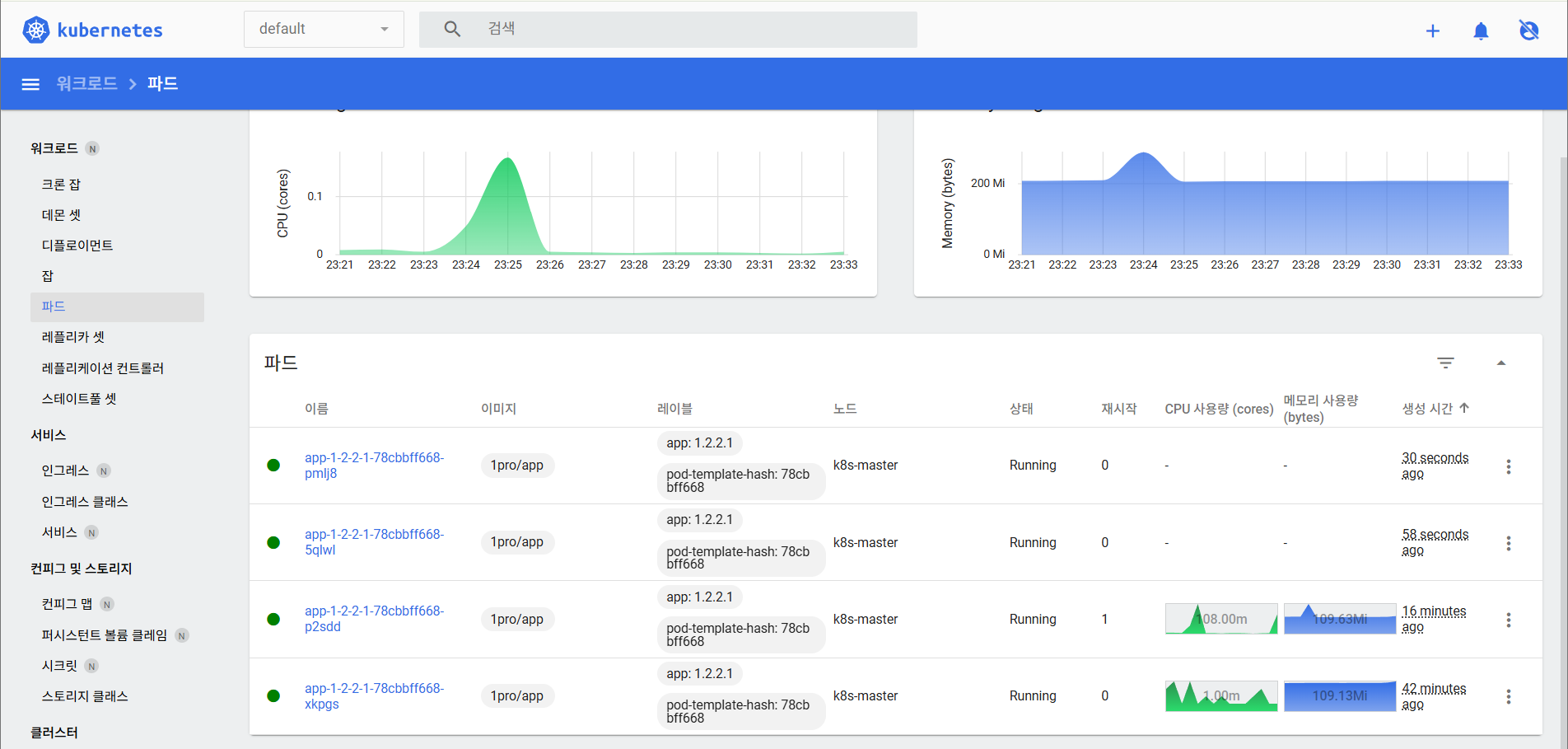
위와 같이 4개가 되었다.
그리고 부하가 줄면 다시 2개로 된다.
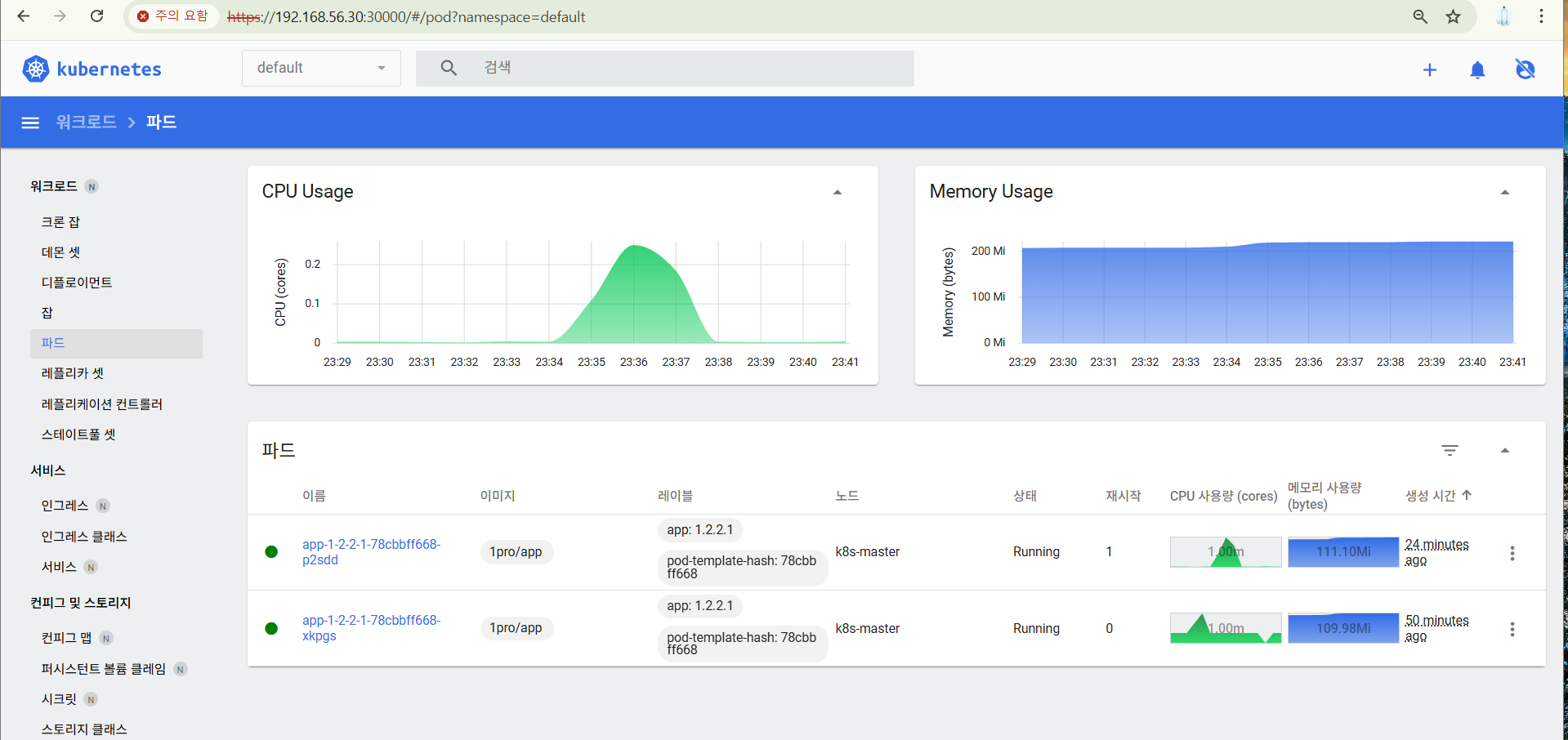
이제 이미지 업데이트도 가능하다.
대시보드에서는 다음과 같이 가능하다.디프로이먼트 - 점 세개 - 편집
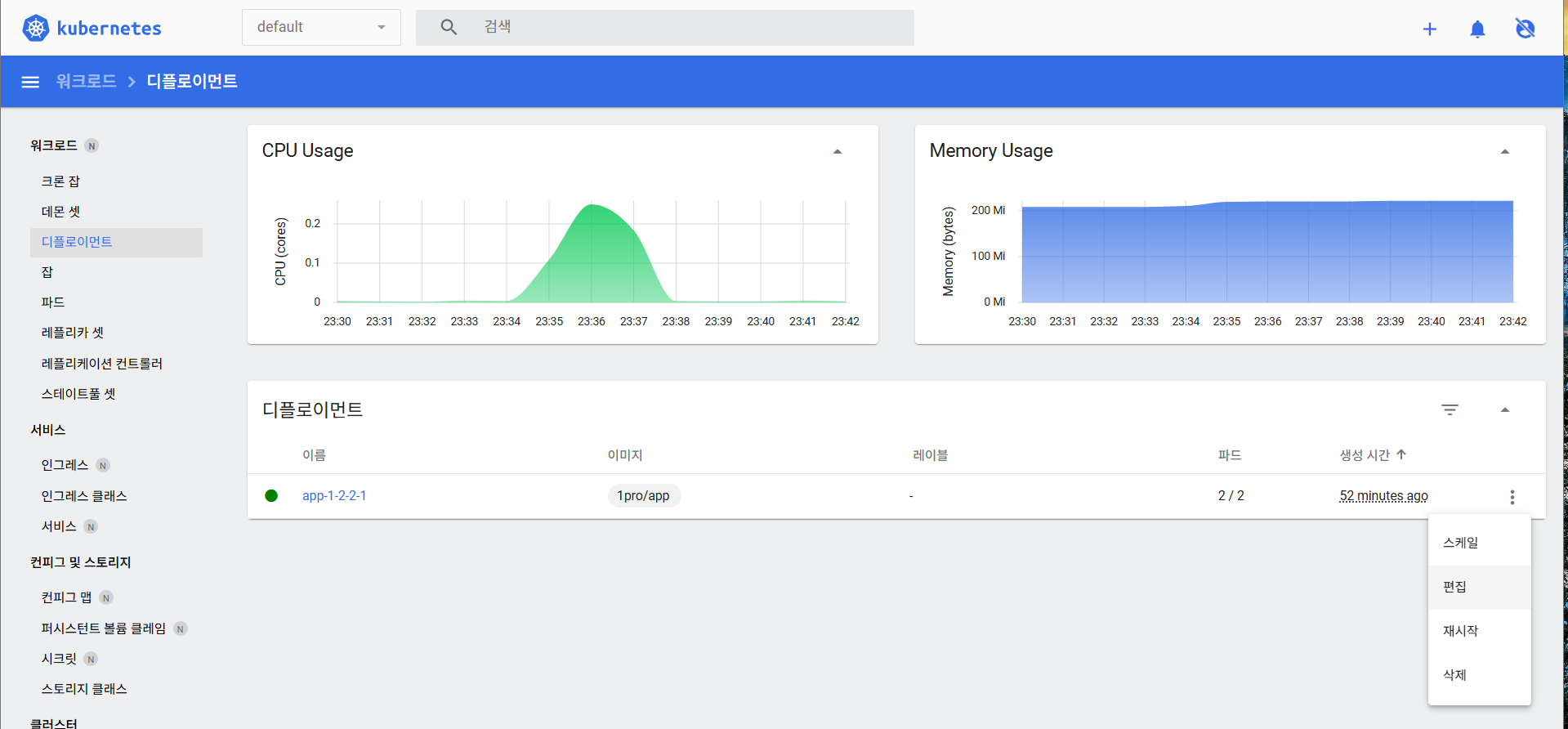
1pro/app -> 1pro/app-update로 변경하면 된다.

명령어는 아래와 같다.
[root@k8s-master ~]# kubectl set image -n default deployment/app-1-2-2-1 app-1-2-2-1=1pro/app-update그리고 위에서 트래픽을 발생시키는 명령어를 실행해보면,
업데이트를 진행해도, 트래픽은 끊기지 않는다.
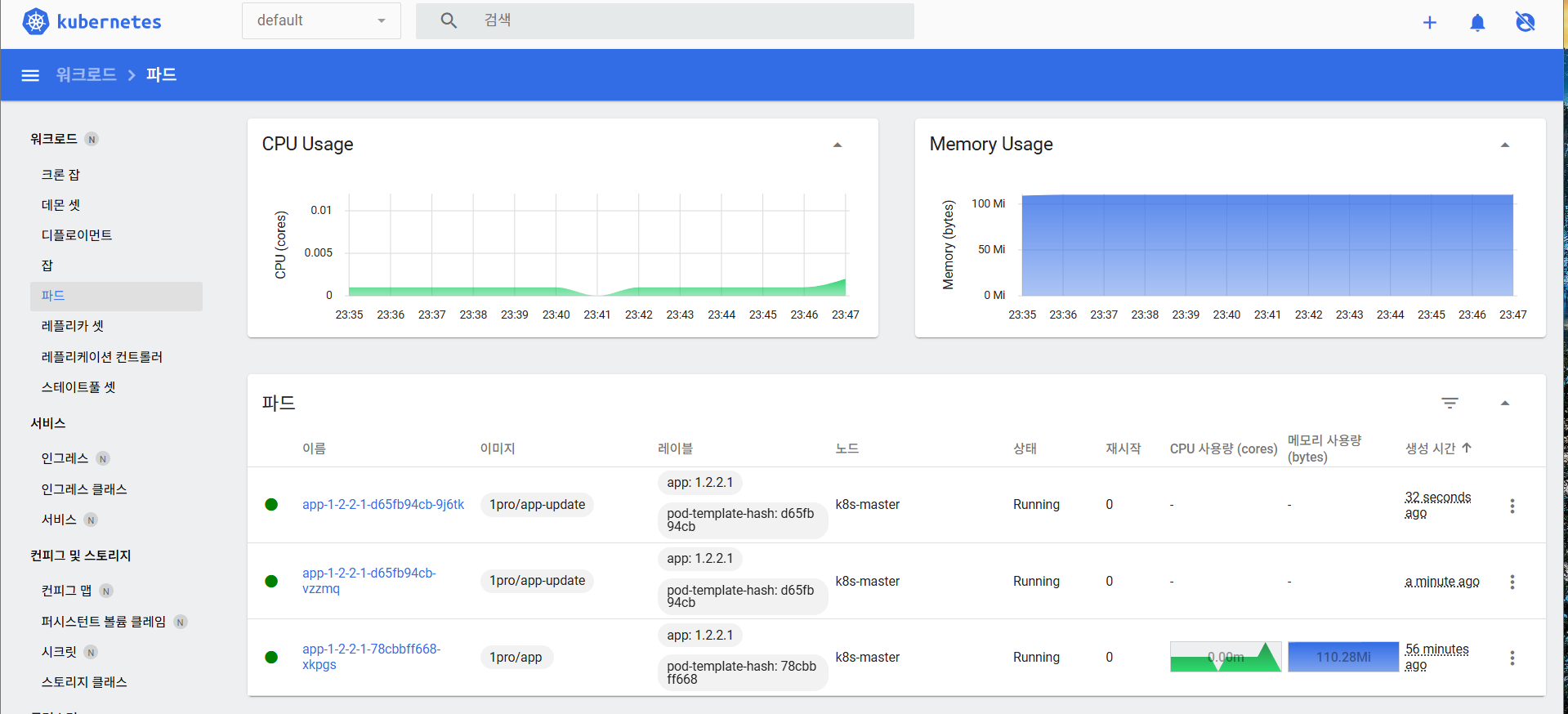
만약에 업데이트를 했는데, 새 이미지가 정상적으로 기동이 되지 않는다면,
(예: 검증은 잘 됐지만, config가 잘 안 먹히는 경우) 어떻게 되는지 확인해보자.
이번엔 app 시작이 제대로 되지 않는 이미지로 교체해보자.
[root@k8s-master ~]# kubectl set image -n default deployment/app-1-2-2-1 app-1-2-2-1=1pro/app-error새 이미지 올라오는 중,
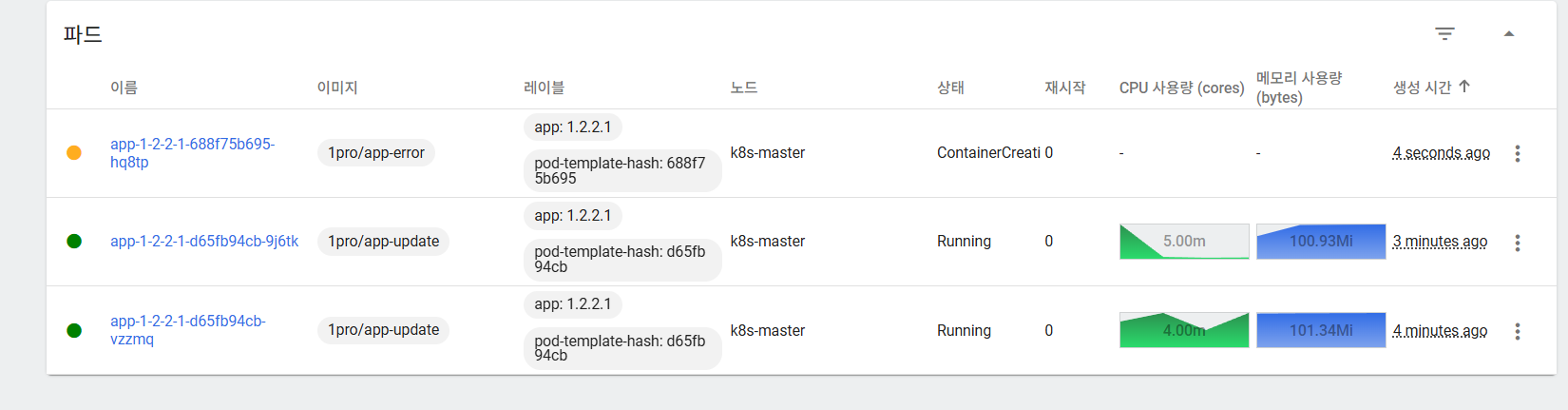
참고로 해당 app은 기동이 되지 않도록 되어있다.
기동이 되지 않도록 해놨지만, 쿠버네티스는 app을 계속 재시작한다.
정상적으로 실행이 되지 않기 때문에 재시작을 시키는데, 새 이미지가 잘 기동이 되는지 확인 후 기존 이미지를 변경하기 때문에, 작업자 실수가 있어도 보완을 해준다.
재시작을 3회까지 했지만, 기존의 2개는 여전히 잘 남아있다.
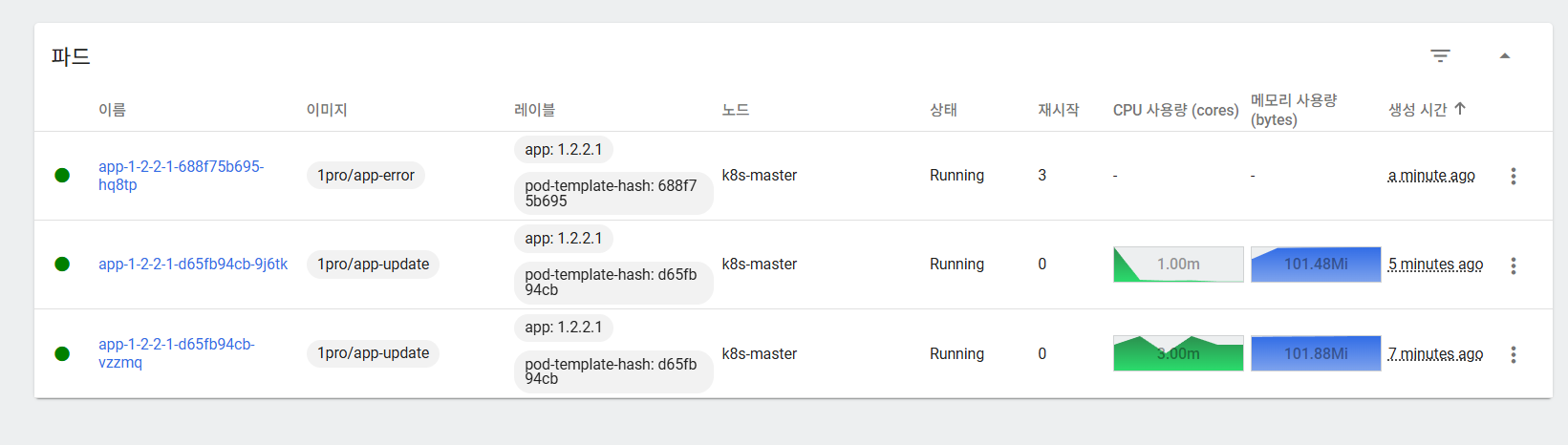
아래 명령어로 취소하자.
[root@k8s-master ~]# kubectl rollout undo -n default deployment/app-1-2-2-1이처럼 쿠버네티스는 앱 상태를 확인하고, 업데이트할 때 서비스를 안정적으로 유지시켜 주는 것을 확인했다.
※ 앱 삭제
[root@k8s-master ~]# kubectl delete -n default deploy app-1-2-2-1
[root@k8s-master ~]# kubectl delete -n default svc app-1-2-2-1
[root@k8s-master ~]# kubectl delete -n default hpa app-1-2-2-12-4. 쿠버네티스 기능으로 편해진 서비스 안정화 및 인프라 환경 관리 코드화
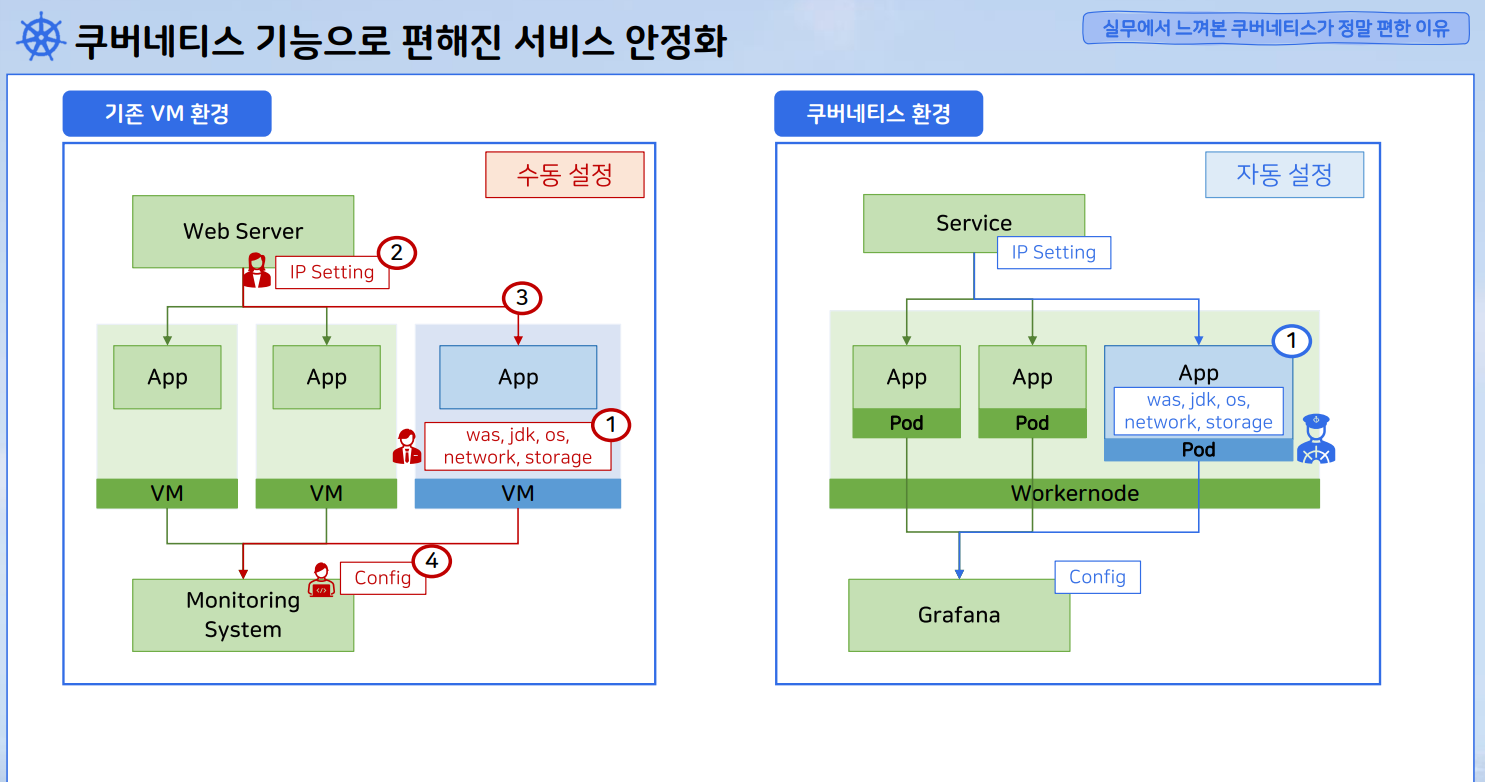
이미지 출처 - 인프런-쿠버네티스 어나더 클래스-Sprint 1, 2 (#실무기초 #설치 #배포 #Jenkins #Helm #ArgoCD)
서비스를 오픈할 때, VM과 Pod를 늘릴 수 있는 상황이라고 가정해보자.
가정이다.
기존 VM 환경
기존 VM 환경에 부하가 심해져서 증설을 해야한다고 판단되면,
- 기존 VM 환경의 VM OS에 ①과 같은 설정을 해놓는다.
- 웹 서버를 관리하는 사람이 IP를 설정해야 한다.
- IP 설정 같은 경우, 작업자에게는 단순한 작업이지만, 운영 상황에서 관리자가 판단할 때, 기존에 잘 돌아가고 있는 App에 영향을 주게 되는 설정은 작업을 하라고 쉽게 말하기 힘들다.
- 관리자도 예전에 이러한 작업을 요청했을 떄, 웹 서버에 이전 잘못된 설정이 같이 반영되어서, 아예 시스템이 중지됐던 경험이 있는 관리자였던 것이다.
- 부하가 심할 땐 간헐적으로 에러가 나지만, 야간에 작업을 하기로 한다.
- 그리고 관리자가 와서 모니터링 화면을 봤을 때, 2개 밖에 나오지 않고 있는 상황이 결국 작업이 안 된 것인 줄 안다.
- 그래도 확인을 해보니 어제 작업했다는 얘기를 들어서, 모니터링 담당자를 불러서 App이 세 개가 보이도록 config 작업을 시킨다.
위 같은 상황은 기존 VM방식의 서비스 오픈날 일어나는 흔한 방식이었음.
쿠버네티스 환경
- 증설이 필요하다고 쿠버네티스 엔지니어에게 말하면 클릭 한번으로 끝남
- 쿠버네티스가 파드 생성과 동시에 VM에서 수동으로 했던 작업들을 자동으로 안정적으로 진행한다..
- 개발기간동안 혹은 성능 테스트를 하면서 자동화된 동작들에는 문제가 없다는 것을 계속 보고 검증하게 된다.
- 파드 안에 설정들이 다 들어있기 때문에 스케일링된 파드 하나만 설정에 실수가 생기는 일이 발생하기 힘들다.
- 쿠버네티스 환경이 관리자 입장에서 빠른 의사결정과 실행을 할 수 있도록 해준다.
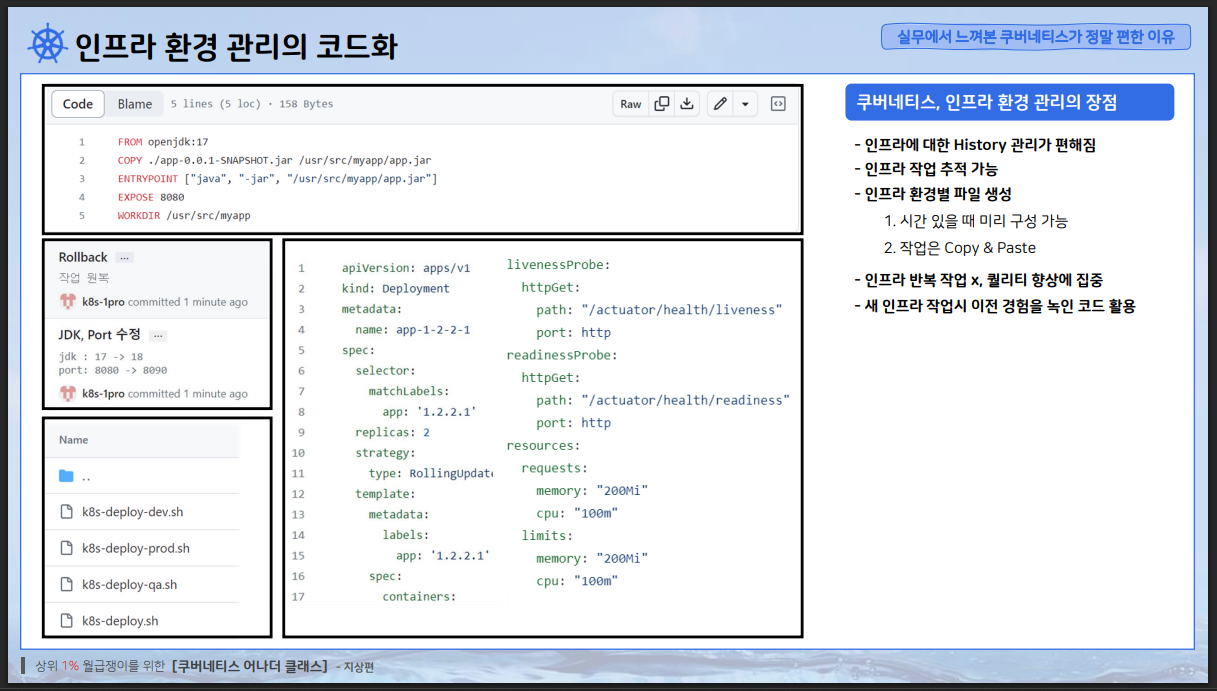
이미지 출처 - 인프런-쿠버네티스 어나더 클래스-Sprint 1, 2 (#실무기초 #설치 #배포 #Jenkins #Helm #ArgoCD)
그리고 인프라 설정을 수동으로 하는 것과 파드에 인프라 설정이 코드로 들어가서 자동으로 되는 것은 큰 차이가 있다.
- 도커 이미지에는 자바 17을 사용하고, 포트는 8080을 쓴다고 정의했다면 해당 코드로 컨테이너가 만들어진다.
- 기존 VM 환경에서는 자바 버전과 포트 작업 내용이 기록으로 남진 않는다.
- 작업 절차 문서를 만든다고 해도 실제 작업 내용과 차이가 생길 수 있다.
- 쿠버네티스 환경은 코드로 인프라 환경을 관리하고 변경하기 때문에 배포를 하려면 작업 이력을 남길 수 밖에 없다.
- 개발처럼 인프라도 변경 관리의 대상이 될 수 있고 인프라의 스토리 관리가 상당히 편해진다.
- 쿠버네티스의 파드 관리도 yaml로 하기 때문에 파드를 몇 개를 띄울지, 자원은 얼마나 줄 것인지 다 코드로 관리할 수 있고, 누가 무슨 작업을 했는지도 확인할 수 있다.
- 또한 코드로 관리하기 때문에 인프라 이슈 발생시에 누가 코드를 변경했는지 추적가능하다.
1. 코드로 인프라를 관리하기 때문에 환경별로 배포 파일을 나눠서 관리할 수 있다.
이는 큰 장점이 있다.
개발 -> 검증 -> 운영순으로 인프라를 구성하는데 실제 장비가 들어오고 네트워크 설정이나 보안 사전 작업이 끝나야 내가 들어가서 환경을 설정할 수 있다. 그래서 보통 운영 환경을 구성할 때 운영 환경을 구성하랴 기존에 구성했던 개발, 검증 환경의 나오는 이슈를 처리하느라 바쁘다.
하지만 이렇게 파일로 관리하면 사전에 작업해야 하는 것 없이 내가 시간이 있을 때 미리 구성해놓을 수 있다.
2. 코드로 관리하기 때문에 파일을 복사할 수 있다.
기존 vm 환경에서는 작업할 내용이 많으면 하나씩 놓치게 된다.
서버 수마다 반복해야 하고, 운영 환경에서는 이중화 구성을 해야한다.
하지만 쿠버네티스는 replicas만 2로 늘려주면 된다.
이처럼 앱이 늘어난다고 하더라도 인프라 설치 일정이 더 걸리지 않는다.
복제본을 늘리는 개념이라 설정이 누락되지고 않는다.
단순 반복작업은 줄어들고, 어떻게 인프라 환경의 질을 늘릴 수 있을지를 더 고민을 할 수 있다.
2-5. 쿠버네티스 엔지니어가 되려면..
전체 흐름를 완성하는데 중점을 두고 시작.
- 흐름을 만들기 위한 최소한의 도구 선택해야한다.
- 그 도구들도 최소한의 기능만 사용하면 된다.
전문 분야 공부
- 배포
- 클라우드
- 서비스 매시
- 이후에 전문 분야별 디테일 공부 및 사용
상황별 공부
- 마음에 드는 도구가 있을 때
- 프로젝크에 써야할 때
3. 요약
기존의 VM 환경과 쿠버네티스 환경을 사용했을 떄의 상황을 비교해보면서 쿠버네티스 환경이 얼마나 인프라 구성을 편하게 해주는지 알게되었다.
'Deploy > Kubernetes' 카테고리의 다른 글
| [Kubernetes] 쿠버네티스 어나더 클래스-Sprint 1. Object 그려보며 이해하기 (0) | 2026.04.30 |
|---|---|
| [Kubernetes] 쿠버네티스 어나더 클래스-Sprint 1. 쿠버네티스 무게감 있게 설치하기 (0) | 2025.10.12 |
| [Kubernetes] 쿠버네티스 어나더 클래스-Sprint 1. 컨테이너 한방정리 (0) | 2025.09.26 |
| [Kubernetes] 대세는 쿠버네티스 (초급~중급편) Ch02. [기초편] 다지기 (0) | 2025.08.13 |
| [Kubernetes] 쿠버네티스 서비스(Service) (0) | 2025.03.05 |