
- 분류 전체보기 (258)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 리스트
- 도커
- LIST
- Java IO
- 자료구조
- filewriter filereader
- java
- 쿠버네티스
- java socket
- 도커 엔진
- 스레드
- 시작하세요 도커 & 쿠버네티스
- 알고리즘
- 김영한
- container
- Docker
- java network
- 자바
- 멀티 쓰레드
- 쓰레드
- 자바 io 보조스트림
- 인프런
- 컨테이너
- 동시성
- Collection
- 실전 자바 고급 1편
- 스레드 제어와 생명 주기
- Thread
- 자바 입출력 스트림
- Kubernetes
- Today
- Total
쌩로그
Jpa기본 04. 엔티티 매핑(인프런 + 자바 ORM 표준 JPA 프로그래밍) 본문
목록
- 포스팅 개요
- 본론
2-1. 객체와 테이블 매핑
2-2. 데이터베이스 스키마 자동생성
2-3. 기본 키 매핑
2-4. 필드와 컬럼 매핑 - 요약
- 짧은 생각과 느낀 점
1. 포스팅 개요
해당 포스팅은 인프런에서 영한님의 JPA기본 강의에서 엔티티 매핑 파트와 해당 파트에 맞는 책의 챕터를 보고 학습한 내용을 요약 및 정리하는 포스팅입니다.
2. 본론
2-1. 객체와 테이블 매핑
@Entity
@Entity가 붙은 클래스는 JPA가 관리하는 것으로, 엔티티라 부릅니다.
속성
- name
- JPA에서 사용할 엔티티 이름을 지정합니다.
- 기본값은 클래스 이름을 사용합니다.
- 다른 패키지에 이름이 같은 클래스가 있다면 이름을 지정해서 충돌하지 않도록 합니다.
주의사항
- 기본생성자는 필수입니다. JPA는 엔티티 객체를 생성할 때 기본생성자를 사용합니다.
- final 클래스, enum, interface, inner 클래스에서는 사용할 수 없습니다.
- 저장할 필드에 final을 사용해선 안 됩니다.
@Table
@Table은 엔티티와 매핑할 테이블을 지정합니다.
생략하면 매핑한 엔티티 이름을 테이블 이름으로 사용합니다.
속성
- name
- 매핑할 테이블이름을 지정합니다.
- 기본값은 엔티티 이름을 사용합니다.
- catalog
- catalog 기능이 있는 데이터베이스에서 catalog를 매핑합니다.
- 카탈로그 참고
- schema
- schema 기능이 있는 데이터 베이스에서 schema를 매핑합니다.
- uniqueConstratins
- DDL 생성 시에 유니크 제약조건을 만듭니다.
- 2개 이상의 복합 유니크 제약조건도 만들 수 있습니다.
- 이 기능은 스키마 자동 생성 기능을 사용해서 DDL을 만들 때만 사용됩니다.
@Table.catalog,
@Table.schema,
@Table.uniqueConstrains
이 세 가지는 왠지 잘 안 사용할 거 같기도 합니다만,,,,아직 저는 잘 모르겠습니다.
2-2. 데이터베이스 스키마 자동생성
데이터베이스 스키마 자동생성은 프로젝트 설정 파일(ex : persistence.xml, yml, properties, yaml 등등)에서 ddl_auto 속성에 따라 다르게 동작합니다.
속성
- create
- 애플리케이션을 시작할 때 기존 테이블을 삭제하고 새로 생성합니다.
- create-drop
- create의 기능과 동일하지만, 애플리케이션 종료시 생성한 테이블을 drop합니다.
- update
- 데이터베이스 테이블과 엔티티 매핑정보를 비교하여 변경 사항만 수정합니다.
- validate
- 데이터베이스 테이블과 엔티티 매핑정보를 비교해서 차이가 있으면 경고를 남기며 실행하지 않습니다. 이 설정은 DDL을 수정하지 않습니다.
- (none)
- 유효하지 않는 옵션입니다. ddl_auto 기능을 사용하지 않으려면 속성을 명시 하지 않으면 됩니다. 혹은 해당 속성에 유효하지 않은 값을 주면 됩니다.
잠시 그의 얘기를 간략히 전달하면,
그는... DDL_AUTO는 개발단계에서만 사용하고, 테스트, 운영서버에선 사용하지 않을 것을 권장 아니 하지말라고 하십니다.
그리고, 데이터베이스 스키마 자동 생성시 자바 코드에서 카멜케이스로 선언한 변수이름을 테이블 create문을 보면, 대문자는 소문자로 바꾸고, 각 단어사이에 언더바(_)가 있는 것을 확인할 수 있습니다.
강의에서는 영한님께서 기억이 나지 않으셔서 못 봤지만, 책에는 나와있습니다. 아래를 보시면 됩니다.
다음은 org.hibernate.cfg 패키지에 있는 ImprovedNamingStrategy 클래스입니다.
코드를 자세히 보면, addUnderscores(String name) 이 메서드에서 for문의 i번째 요소가 대문자라면, 언더스코어(언더바(_))를 insert하고 있습니다.
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.hibernate.cfg;
import java.io.Serializable;
import java.util.Locale;
import org.hibernate.AssertionFailure;
import org.hibernate.internal.util.StringHelper;
public class ImprovedNamingStrategy implements NamingStrategy, Serializable {
...
...
protected static String addUnderscores(String name) {
StringBuilder buf = new StringBuilder(name.replace('.', '_'));
for(int i = 1; i < buf.length() - 1; ++i) {
if (Character.isLowerCase(buf.charAt(i - 1)) && Character.isUpperCase(buf.charAt(i)) && Character.isLowerCase(buf.charAt(i + 1))) {
buf.insert(i++, '_');
}
}
return buf.toString().toLowerCase(Locale.ROOT);
}
...
...2-3. 기본 키 매핑
JPA가 제공하는 데이터베이스 기본 키 생성 전략은 다음 두 가지가 있습니다.
- 직접 할당
- 자동 생성
- IDENTITY
- SEQUENCE
- TABLE
입니다.
직접 할당
기본 키를 직접 할당하려면, 기본 키 필드에 @Id 어노테이션만 주면됩니다.
기본 키 직접 할당 전략은 em.persist() 로 엔티티를 저장하기 전에 기본 키를 할당하는 방법입니다.
앞 장에서 봤듯이 em.persist()를 하면, 영속성 컨텍스트의 1차 캐시로 들어가게 되는데, 1차 캐시에 들어가기 위해선 엔티티에 반드시 기본 키가 있어야 한다고 했습니다.
왜냐하면 영속성 컨텍스트에서는 기본 키로 엔티티를 식별하기 때문입니다.
기본 키가 할당되어 있지 않으면, 예외가 발생합니다.
자동 생성
IDENTITY 전략
- 기본 키 생성을 데이터베이스에 위임하는 전략입니다.
- IDENTITY 전략은 데이터베이스에 값을 저장하고 나서야 기본 키 값을 구할 수 있을 때 사용합니다.
- @GenreatedValue 어노테이션에서 strategy 속성에 GenerationType.IDENTITY로 지정함으로써 설정할 수 있습니다.
- JPA는 기본 키 값을 얻어오기 위해 데이터베이스를 추가로 지정합니다.
@Entity
class Board {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
...
}가 있을 때,
public static void main(String[] args) {
Board board = new Board();
em.persist(board);
Sysetm.out.println("board.id = " + board.getId());
}
// 출력 : board.id = 1 이렇게 나옵니다. IDENTITY 전략은 Entity를 데이터베이스에 insert 해야만, Id 값이 생깁니다.
이와 관련된 얘기를 해보자면,
저렇게 board.id가 나오기까지는 insert쿼리 한 번과 select 쿼리 한 번 하여 총 두 번의 쿼리가 나가야합니다.
하지만, JPA는 내부적으로 JDBC API를 호출하게 되는데, JDBC3에서 추가된 Statement.getGeneratedKeys()메서드를 사용하면, 데이터를 저장하면서 동시에 생성된 기본 키 값도 얻어올 수 있습니다.
그래서 한 번의 통신으로 기본 키를 얻어올 수 있기 때문에, 쿼리가 두 번 나가는 걱정은 하지 않으셔도 될 거 같습니다.^^
그리고, 영속성 컨텍스트에 저장되는 객체는 반드시 식별자가 필요합니다.
하지만, 기본 키에 IDENTITY 전략을 사용하는 엔티티같은 경우 식별자가 없기 때문에, 영속성 컨텍스트에 저장할 수 없습니다.
그래서 기본 키에 IDENTITY 전략을 사용하는 엔티티는 em.persist() 메서드가 호출되는 즉시 insert 쿼리가 나가게 됩니다. 그렇기 때문에 IDENTITY 전략을 사용하는 경우에는 트랜잭션을 지원하는 쓰기 지연이 동작하지 않습니다.
SEQUENCE 전략
데이터베이스 시퀀스는 유일한 값을 순서대로 생성하는 특별한 데이터베이스 오브젝트입니다.
SEQUENCE 전략은 이 시퀀스를 사용해서 기본 키를 생성합니다.
@SequenceGenerator어노테이션
- 속성
- name
- 시퀀스 생성기 이름입니다.
- 기본 값은 필수로 줘야합니다.
- sequenceName
- 데이터베이스에 등록되어 있는 시퀀스 이름입니다.
- 기본 값은 hibernate_sequence입니다.
- initialValue
- DDL 생성 시에만 사용됩니다.
- 시퀀스 DDL을 생성할 때 처음 시작하는 수를 지정합니다.
- 기본 값은 1입니다.
- allocationSize
- 시퀀스를 한 번 호출에 증가하는 수입니다.
- 성능 최적화에 사용됩니다.
- 기본 값은 50입니다.
- catalog, schema
- 데이터베이스 catalog, schema 이름입니다.
- name
시퀀스 매핑 코드 예시를 살펴봅시다.
@Entity
@SequenceGenertator (
name = "BOARD_SEQ_GENERATOR", // 시퀀스 생성기 이름
sequenceName = "BOARD_SEQ", // 데이터베이스에 생성된 시퀀스
initialValue = 1, allocationSize = 1)
public Board {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "BOARD_SEQ_GENERATOR")
private Long id;
...
}@SequenceGenertator.name에 지정한 이름으로 시퀀스 생성기를 등록합니다.
@SequenceGenertator.sequenceName에 시퀀스 이름을 지정했는데, JPA는 시퀀스 생성기를 sequenceName으로 된 데이터베이스의 실제 시퀀스와 매핑합니다.
그럼 id의 식별자 값은 시퀀스 생성기가 할당합니다.
SEQUENCE 전략에서 em.persist()를 호출하면 다음과 같은 순서로 진행됩니다.
- 먼저 데이터베이스 시퀀스를 사용해서 식별자를 조회한다.
- 조회한 식별자를 엔티티에 할당합니다.
- 식별자가 할당된 엔티티를 영속성 컨텍스트에 저장합니다.
- 이후 트랜잭션을 커밋해서 플러시가 일어나서 데이터베이스에 반영됩니다.
SEQUENCE 전략은 데이터베이스 시퀀스를 통해 식별자를 조회하는 추가 작업이 필요합니다.
그래서 처음에 데이터베이스와 2번 통신합니다.
한 번은 식별자를 구하기 위해서 시퀀스를 조회하고,
한 번은 조회한 시퀀스를 엔티티의 기본 키에 할당하고 데이터베이스에 저장합니다.
그리고 SEQUENCE의 속성 중 allocationSize가 기본 50으로 되어있는 걸 주목해봐야하는데, 설정된 값만큼 한 번에 시퀀스 값을 증가시키고 난 후 그만큼 메모리에 시퀀스 값을 할당합니다.
그리고 시퀀스는 애플리케이션이 종료되면 끊깁니다.
한번 확인해보겠습니다!
먼저 persistence.xml에서 ddl_auto 옵션은 create를 줬습니다.

다음은 Member 클래스입니다.
import javax.persistence.*;
@Entity
@SequenceGenerator(
name = "member_seq_generator",
sequenceName = "member_seq",
initialValue = 1, allocationSize = 50)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "member_seq_generator")
private Long id;
@Column(name = "name", nullable = false)
private String username;
public Member() {
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
}다음은 main 메서드가 있는 클래스입니다.
package hellojpa;
import javax.persistence.*;
public class JpaMain {
public static void main(String[] args) {
// jpa 단위로 하나씩 생성되어 있어야 함.
EntityManagerFactory enf = Persistence.createEntityManagerFactory("hello"); // persistence.xml의 'persistence-unit name' 값
EntityManager em = enf.createEntityManager();
// JPA의 변경작업은 모두 하나의 트랜잭션 단위 안에서 이뤄져야 한다.
EntityTransaction tx = em.getTransaction();
tx.begin();
// 실제 애플리케이션 동작
try {
Member[] members = new Member[1402];
for(int i=0; i<members.length; i++) {
members[i] = new Member();
members[i].setUsername(i+"_member");
em.persist(members[i]);
System.out.println("members[i].getId() = " + members[i].getId());
}
System.out.println("==============");
System.out.println("==============");
System.out.println("==============");
System.out.println("==============");
tx.commit();
} catch (Exception e) { // 예외 발생시 롤백
tx.rollback();
} finally { // 트랜잭션 닫기
em.close();
}
// 애플리케이션 끝나면, enf, em 닫아주기
enf.close();
}
}콘솔을 보시면 다음과 같이 나옵니다.
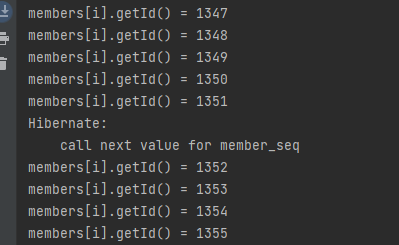
allocationSize를 50으로 주고,
인덱스가 0인 배열에 for문으로 값을 집어넣었으니, 51에서 SEQUENCE를 호출하고 있습니다.
H2에서 결과를 확인해보면, 1402까지 찍혀있습니다.
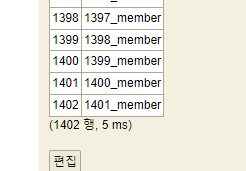
그리고 ddl_auto에 유효하지 않은 none을 넣어보겠습니다.
유효하지 않은 값이기에 해당 속성은 활성화되지 않습니다.

다시 돌려서 H2를 확인해보겠습니다.

1402에서 1452로 중간에 끊긴 채로 SEQUENCE를 시작합니다.
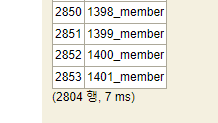
이처럼 중간에 서버가 중단되면 (참고로 H2 데이터베이스는 윈도우에서 계속 실행되고 있습니다.) SEQUENCE가 중간에 끊깁니다.
아! 그리고 SEQUENCE 전략을 순서로 얘기해봤으니
IDENTITY 전략에 대해서도 순서로 한 번 정리해보겠습니다.
- em.persist()를 하면, IDENTITY 전략이기 때문에, 곧바로 데이터베이스에 insert쿼리를 날려 데이터베이스에 저장합니다.
- 데이터베이스에 엔티티를 저장함과 동시에 JDBC3의 Statement.getGenerateKeys()를 호출하여 기본키를 얻어옵니다. (이 때 쿼리가 2번 나가야 정상인데, 한 번의 통신으로 인해서 insert와 select하는 효과를 가져입니다.)
- DB에 저장된 엔티티는 곧바로 영속성 컨텍스트에 저장됩니다.
- 순서는 아니지만, IDENTITY 전략은 이로 인해서 트랜잭션을 이용한 쓰기 지연을 사용할 수 없습니다.
TABLE 전략
키 생성 전용 테이블을 하나 만들고 여기에 이름과 값으로 사용할 컬럼을 만들어 데이터베이스 시퀀스를 흉내내는 전략입니다.
이 전략은 테이블을 사용하기 때문에 모든 데이터베이스에 적용할 수 있습니다.
하지만, 성능이 좋지 않은 단점이 있습니다.
총 세번의 쿼리가 나가는데
- 테이블에서 시퀀스를 조회합니다.
- 조회한 시퀀스를 엔티티에 할당하여 insert 쿼리를 날립니다.
- 그리고 다음 시퀀스를 위해 시퀀스 테이블에 update 쿼리를 날립니다.
이처럼 한번의 데이터 입력에 3번의 쿼리가 나갑니다.
SEQUENCE 전략처럼 클래스 레벨에 @TableGenerator 어노테이션을 선언할 수 있는데, 속성은 다음과 같이 있습니다.
속성
- name
- 식별자 생성기 이름입니다.
- 필수입니다.
- table
- 키 생성 테이블 이름을 지정합니다.
- 기본 값은 JPA 구현체 Hibernate 기준 hibernate_sequences입니다.
- pkColumnName
- 시퀀스 컬럼명입니다.
- 기본 값은 sequence_name입니다.
- valueColumnName
- 시퀀스 값 컬럼명입니다.
- 기본 값은 next_val입니다.
- pkColumnValue
- 키로 사용할 값의 이름입니다.
- 기본 값은 엔티티 이름입니다.
- initailValue
- 시퀀스처럼 초기 값을 지정합니다.
- 마지막으로 생성된 값이 기준이 됩니다.
- 기본 값은 0입니다.
- allocationSize
- 시퀀스 한 번 호출에 증가하는 수를 지정합니다.
- 기본 값은 시퀀스전략과 동일하게 50입니다.
- catalog, schema
- 데이터베이스의 catalog, schema 이름입니다.
- uniqueConstraints(DDL)
- 유니크 제약 조건을 지정할 수 있습니다.
AUTO 전략
@GeneratedValue.strategy의 기본 전략입니다.
방언으로 설정한 데이터베이스 벤더에 맞게 자동으로 선택됩니다.
만약 AUTO를 사용할 때, SEQUENCE나 TABLE 전략이 선택되면 시퀀스나 키 생성용 테이블을 미리 만들어 두어야 합니다.
기본 키 선택 전략
영한님의 실무와 관련된 노하우에 대한 내용입니다.
기본 키를 선택할 때, 비즈니스 로직과 관계된 데이터를 기본 키로 두기보단, 대체 키를 선택하기를 권장한다고 합니다.
왜냐하면, 당시 null값이 아니고, 유일하고, 변하지 않는 데이터로 주민등록번호를 기본 키로 둔 적이 있었지만, 정부에서 주민등록번호를 저장하지 말라고 했을 때, 그걸 빼내는 게 보통이 아니었다고, 말씀하셨거든요.
그래서 비즈니스와 관계된 데이터가 아니라, 대리 키를 두기를 권장하셨습니다.
덧붙여 하신 말에는 비즈니스 환경은 언젠가 변한다라고 하셨고, 기본 키의 원칙 중 절대 변하면 안 된다는 원칙이 있기 때문에, 비즈니스와 관계된 데이터보단, 대리 키를 식별자로 두며, 비즈니스와 관계된 데이터는 유니크 키로 두고, 후에 보조 인덱스를 사용하는 방식으로 하는 것을 권장합니다.
기본 키 전략에 대한 나의 생각.
잠시 "IDENTITY와 SEQUENCE 중, 어떤 게 더 좋은걸까?" 를 생각해봤습니다
프로젝트 당시 MySQL을 DBMS로 선택해서 사용했습니다.
MySQL을 염두에 두고 생각해봤습니다.
MySQL은 insert쿼리를 실행하면, 페이지가 다 차면, 페이지 분할이 일어납니다.
페이지 분할을 생각하면, SEQUENCE보단 IDENTITY가 낫다고 생각되는데요.
물론 서비스의 요청이 계속 매번 들어오는 게 아니지만,,
애플리케이션 환경이 main메서드가 있는 곳에서 em.persist()메서드를 이용한다는 가정하에 한 번 생각해봤습니다.
IDENTITY는 insert에 대해서 '트랜잭션이 지원하는 쓰기 지연'이 되지않습니다.
즉 em.persist()로 데이터 입력시 곧바로 insert쿼리를 날리게 되는데요.
그럼 데이터 입력시 바로바로 insert쿼리를 날리게 됩니다. 그러면 간간이 일정시간동안 데이터가 저장되면서, 페이지 분할이 간간이 일어날텐데,
SEQUNCE전략을 사용하면, 시퀀스를 불러와서 메모리에 시퀀스만큼의 수롤 호출하게되고, 시퀀스가 차기까지 insert쿼리문을 '쓰기 지연 SQL 저장소'에 차곡차곡 모아두었다가, 트랜잭션 커밋 시점에 insert쿼리를 파바박 날리게 되는데, 이 때 한번의 많은 양의 데이터가 입력되기 때문에, 페이지 분할이 일어나게되지않을까? 생각이 듭니다.
페이지 분할이 일어나게 되면 성능에 영향을 미친다고 알고있습니다.
페이지 분할을 생각하면, SEQUENCE 전략보단, IDENTITY 전략이 더 좋은 선택인 거 같습니다. insert쿼리를 한 번에 많이 보내는 것이 아니라, 필요할 때 즉시 즉시 보내기 때문입니다.
하지만, 트랜잭션이 지원하는 쓰기 지연을 사용하지 못하는 점에서는 SEQUENCE 전략이 더 좋아보입니다...
흠... 정답은 모르겠습니다...
나중에 알 수 있겠지..요?!
의문을 남긴채 계속 넘어가보겠습니다...^^;;
2-4. 필드와 컬럼 매핑
필드와 컬럼 매핑 어노테이션에 대한 소개인데요.
이 기능들은 DDL을 자동 생성할 때만 사용되고, JPA의 실행 로직에서는 영향을 주지않는 점 참고바라겠습니다.
필드에 명시를 해줌으로써 개발자들이 테이블의 구조를 직관적으로 파악할 수 있다는 장점이 있습니다.
각 필드 어노테이션들을 살펴보겠습니다.
@Column
컬럼을 매핑하는 어노테이션입니다.
속성입니다.
- name
- 필드와 매핑할 테이블의 컬럼 이름을 지정합니다.
- 기본 값은 객체의 필드이름입니다.
- insertable
- 엔티티 저장시 이 필드도 같이 저장합니다.
- false로 설정하면, 이 필드는 데이터베이스에 저장하지 않습니다.
- false는 읽기 전용일 때만 사용합니다.
- 거의 사용하지 않습니다.
- 기본 값은 true입니다.
- updatable
- 엔티티 수정시 이 필드도 같이 수정합니다.
- false로 설정하면 데이터베이스에 수정하지 않습니다.
- 읽기 전용으로 사용할 때 false로 설정합니다.
- insertable처럼 거의 사용하지 않습니다.
- 기본 값은 true입니다.
- table
- 하나의 엔티티를 두 개 이상의 테이블에 매핑할 때 사용합니다.
- 지정한 필드를 다른 테이블에 매핑할 수 있습니다.
- 거의 사용하지 않습니다.
- 기본 값은 현재 클래스가 매핑된 테이블입니다.
- nullable(DDL)
- null 값의 허용 여부를 설정합니다.
- false로 설정하면 DDL 생성시에 null 제약조건이 붙습니다.
- 기본 값은 true입니다.(null 허용)
- unique(DDL)
- 한 컬럼에 간단한 유니크 제약조건을 걸 때 사용합니다.
- 만약 두 컬럼 이상을 사용하여 유니크 제약조건을 설정하려면 클래스 레벨에서 @Table.uniqueConstraints를 사용해야 합니다.
- 이 설정은 굳이 사용하지 않길 권장합니다.
- 이 설정으로 인해서 unique 제약조건을 보면, 이름이 알아보기 힘들게 되어있습니다.
- 그렇기 때문에, 실제 DB에 직접 접근해서 유니크 제약 조건을 생성하는 것을 영한님께서 권장하셨습니다.
- columnDefinition(DDL)
- 데이터베이스 컬럼 정보를 직접 줄 수 있습니다.
- 기본 값은 필드의 자바 타입과 방언 정보를 사용해서 적절한 컬럼 타입을 생성합니다.
- length(DDL)
- 문자 길이 제약조건, String 타입에만 사용합니다.
- 기본 값은 255입니다.
- percision, scale(DDL)
- BigDecimal, BigInteger타입을 사용합니다.
- perision은 소수점을 포함한 전체 자릿수를 의미합니다.
- scale은 소수의 자릿수를 의미합니다.
엔티티의 필드가 자바의 기본타입이라면, @Column을 사용할 때, nullable은 false로 지정하는 것이 안전합니다.
왜냐하면, 자바의 기본 타입엔 null이 허용되지 않습니다.
그런데, @Column을 주면, nullable의 기본 값이 true이기 때문에 null을 허용한다는 의미가 됩니다. 따라서 null을 허용하지 않는 자바의 기본 타입의 장점을 살리려면, @Column 어노테이션을 사용하되, nullable 속성에 false로 지정하는 것이 안전합니다.
@Enumerated
자바의 enum타입을 매핑하는 어노테이션입니다.
속성에는 다음과 같이 있습니다.
- value
- EnumType.ORDINAL
- enum 순서를 데이터베이스에 저장합니다.
- 데이터베이스에 저장되는 데이터 크기가 작은데, 저장된 enum 순서를 변경할 수 없습니다.
- EnumType.STRING
- enum 이름을 데이터베이스에 저장합니다.
- 저장된 enum의 순서가 바뀌거나 enum이 추가되어도 안전합니다.
- 데이터베이스에 저장되는 데이터 크기가 ORDINAL에 비해서 큽니다.
- EnumType.ORDINAL
그럼에도 불구하고, 여기서 EnumType.STRING을 무조건 써야됩니다.
왜냐하면, 예를 들어 쇼핑몰의 상품이 두 가지의 상태를 가진다고 가정했을 때, 판매중, 판매 완료 이 두 가지가 있다고 해봅시다.
먼저 ORDINAL로 지정하여 여러 개의 상품을 데이터베이스에 insert했을 때,
판매중, 판매완료에 해당하는 부분이 0 또는 1로 나올겁니다.
그런데, 만약 이 enum에 품절로 인한 판매 일시 중지라는 값을 처음 순서에 넣었다고 가정해봅시다.
그리고 어떤 상품의 상태를 품절로 인한 판매 일시 중지 이렇게 고친 후, 몇 건의 데이터를 insert한 후, 조회를 했을 때,
상태라는 컬럼에 품절로 인한 판매 일시 중지가 해당하는 값이 0으로 나옵니다.
그런데!
아까 0은 판매중이었습니다.
이렇게 되면, 이전에 상품 중 판매 중이었던 상품에는 상태가 0으로 나올 것입니다.
그런데, 제품 상태가 품절로 인한 판매 일시 중지인 상품의 상태에도 0으로 나옵니다.
이처럼 ORDINAL로 EnumType을 설정하면, 데이터가 꼬여버리는 일이 발생합니다.
그래서 ORDINAL이 아니라, STRING으로 설정하기를 권장합니다.
@Temporal
날짜 타입을 매핑할 때 사용합니다.
그런데 만약 날짜 자바 8 이상을 사용하고 있고, 날짜 타입을 LocalDate, LocalTime, LocalDateTime 중 하나를 사용한다면, 이 어노테이션을 생략해도 됩니다.
만약 DDL_AUTO로 테이블 자동 생성을 이용하면, 지정한 자바의 날짜 타입과 가장 유사한 데이터 타입으로 정의합니다.
제 이야기를 잠시 하자면,,,,
예전에 자바 코드에서 날짜 관련 타입을 Date로 지정했을 때, 자동으로 생성되는 테이블의 create문에는 날짜와 시간을 모두 다루는 타입인 timestamp가 정의되어있었습니다. 그런데 그 이유가 지정한 자바의 날짜 타입과 가장 유사한 데이터 타입으로 정의하기 때문이었다는 것을 이번에야 깨닫게 되었는데요...
자바에서 Date 클래스는 날짜와 시간을 함께 다루는 클래스입니다.
MySQL에서 날짜와 시간을 다루는 데이터타입에는 timestamp가 있습니다.
지정한 자바의 날짜 타입과 가장 유사한 데이터 타입으로 정의되기 때문에, Date와 가장 유사한 timestamp로 정의되는 것이었습니다
@Lob
데이터베이스의 BLOB과 CLOB 타입과 매핑합니다.
@Lob 어노테이션에는 저장할 수 있는 속성이 없습니다.
단지 매핑하는 필드타입이 문자면, CLOB으로 매핑하고, 나머지는 BLOB으로 매핑합니다.
@Transient
이 어노테이션이 선언된 필드는 매핑하지 않습니다.
즉, 데이터베이스에 저장하지 않고, 조회하지도 않습니다.
객체에 임시로 어떤 값을 보관하고 싶을 때 사용됩니다.
@Access
JPA가 엔티티 데이터에 접근하는 방식을 지정합니다.
접근하는 방식에는 필드 접근과 프로퍼티 접근이 있습니다.
필드 접근
- AccessType.FIELD로 지정합니다.
- 필드에 직접 접근합니다.
- 필드 접근 권한이 private이어도 접근할 수 있습니다.
필드 접근 예시
@Entity
@Access(AccessType.FIELD)
public class Member {
@Id
private String id;
...
...
}@Id가 필드에 있기 때문에, @Access(AccessType.FIELD)로 설정한 것과 같습니다.
@Access를 생략해도 상관없습니다.
프로퍼티 접근
- AccessType.PROPERTY로 지정합니다.
- Getter를 이용하여 필드에 접근합니다.
@Entity
@Access(AccessType.PROPERTY)
public class Member {
private String id;
@Id
public String getId() {
return id;
}
}여기서는 @Id가 프로퍼티에 있습니다.
@Access(AccessType.PROPERTY)로 설정한 것과 같은 효과입니다.
따라서 @Access를 생략해도 상관없습니다.
필드접근 + 프로퍼티 접근
@Entity
public class Member {
@Id
private String id;
@Transient
private String firstName;
@Transient
private String lastName;
@Access(AccessType.PROPERTY)
public String getFullName() {
return firstName + lastName;
}
...
}
@Id는 필드에 있으므로, 필드 접근 방식을,
getFullName() 메서드는 프로퍼티 접근 방식을 사용한다는 것을 확인 할 수 있습니다.
3. 요약
이번 포스팅은 객체와 테이블을 매핑하는 법,
그리고 ddl_auto를 이용해서 데이터베이스를 자동생성할 때 각 옵션마다의 차이점,
그리고 기본 키 매핑을 할 때 어떤 어떤 전략들이 있고, 각 전략들의 특징에 대해서 알아보았습니다.
기본 키 뿐만 아니라, 엔티티의 필드들을 데이터베이스의 테이블의 각 컬럼과 어떻게 매핑시키고, 어떻게 매핑에서 제외할 수 있을지에 대해서 알아보았습니다.
4. 짧은 생각과 느낀 점
나에 대해
지금 느끼는 것은.... 정말 모르는 채로 썻다는 느낌이 드네요.
강의는 이미 다 봤지만, 급한 마음에 빨리 빨리 봐서 모든 내용들이 새롭게 다가옵니다..
지금 천천히 조금 더 딥하게 보고, 여유로운 마음으로 보고있습니다만,
4장까지의 내용에서도 정말 고민할 점들이 많다는 것을 느낍니다..
이대로 QueryDSL까지 한번 로드맵을 천천히 여유롭게 밟아나가겠습니다.
그리고 조만간 배운 내용들을 토대로 지금까지 해왔던 프로젝트 두 개를 리팩터링해봐야겠네요 ㅎㅎ
JPA에 대해
잠시 생각되는 점을 말씀드려보면, 애플리케이션의 객체지향적인 설계를 위해서는 JPA는 무조건 해야되는구나 라고 생각됩니다.
이러한 생각은 다음 연관관계 매핑에서 풀어볼 수 있지 않을까 생각됩니다.
테이블 중심 적인 설계를 하다보면, 객체 그래프 탐색이 중간에 끊어집니다.
getId로 id를 찾고, find로 찾아오고,
find로 찾아온 객체에서 getId로 id를 찾고, find로 찾아오고,
find로 찾아온 객체에서 getId로 id를 찾고, find로 찾아오고,
find로 찾아온 객체에서 getId로 id를 찾고, find로 찾아오고,
ㅎㅎㅎ...
연관관계 매핑 기초로 찾아오겠습니다!

영한님에 대해
He is JPA 권위자
'Spring Project > JPA' 카테고리의 다른 글
| Jpa기본 06. 다양한 연관관계 매핑(인프런 + 자바 ORM 표준 JPA 프로그래밍) (11) | 2023.09.11 |
|---|---|
| Jpa기본 05. 연관관계 매핑 기초(인프런 + 자바 ORM 표준 JPA 프로그래밍) (0) | 2023.09.01 |
| Jpa기본 03. 영속성 관리(인프런 + 자바 ORM 표준 JPA 프로그래밍) (4) | 2023.08.21 |
| Jpa기본 02. JPA 시작하기(인프런 + 자바 ORM 표준 JPA 프로그래밍) (0) | 2023.08.21 |
| Jpa기본 01. JPA의 소개(인프런 + 자바 ORM 표준 JPA 프로그래밍) (1) | 2023.08.20 |